推荐
专栏
教程
课程
飞鹅
本次共找到5082条
nginx反向代理配置详解
相关的信息
Stella981
•
4年前
SILC超像素分割算法详解(附Python代码)
SILC算法详解一、原理介绍SLIC算法是simplelineariterativecluster的简称,该算法用来生成超像素(superpixel)算法步骤: 已知一副图像大小M\N,可以从RGB空间转换为LAB空间,LAB颜色空间表现的颜色更全面假如预定义参数K,K为预生成的超像素数量,即预计将M\N大小的图
Wesley13
•
4年前
CAP定理与BASE理论
1\.CAP定理C:Consistency,一致性A:Availability,可用性P:Partitiontolerance,分区容错性CAP定理,指的是在一个分布式系统中,一致性、可用性、分区容错性,三者不可得兼。2\.CAP详解2.1一致性(C)指所有节点访问同一份最新的
Wesley13
•
4年前
Java字节码详解
也许你写了无数行的代码,也许你能非常溜的使用高级语言,但是你未必了解那些高级语言的执行过程。例如大行其道的Java。Java号称是一门“一次编译到处运行”的语言,但是我们对这句话的理解深度又有多少呢?从我们写的java文件到通过编译器编译成java字节码文件(也就是.class文件),这个过程是java编译过程;而我们的java虚拟机执行的就是字节码文件
Wesley13
•
4年前
http协议请求响应详解
http协议请求响应详解一、http协议简介HTTP是HyperTextTransferProtocol(超文本传输协议)的简写,它是TCP/IP协议的一个应用层协议,用于定义WEB浏览器与WEB服务器之间交换数据的过程及数据本身的格式。二、HTTP1.0的基本运行方式1、基于HTTP协议(https://www.osc
Wesley13
•
4年前
34.TCP取样器
阅读文本大概需要3分钟。1、TCP取样器的作用 TCP取样器作用就是通过TCP/IP协议来连接服务器,然后发送数据和接收数据。2、TCP取样器详解!(https://oscimg.oschina.net/oscnet/32a9b19ba1db00f321d22a0f33bcfb68a0d.png)TCPClien
Stella981
•
4年前
DevOps 安全威胁,你值得关注!
随着开源软件被大量引用,线上运行的代码中超过80%的部分是开源代码。软件安全的重点已经从内部代码转移到所引用开源部分上。DevOps安全需要关注内部研发团队的自研代码以及外部第三方开源软件的安全,对于内部代码,所使用的依赖必须清楚,如果底层依赖有风险,还必须快速反向分析哪些其他软件受到同样的威胁;目前DevOps安全团队和持续交付团队往往独立运行,信息交
Wesley13
•
4年前
mysql explain执行详解
!(https://oscimg.oschina.net/oscnet/c6df6d3229fc511bc625bc3a89f58c7b0ce.png)1)、id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询。2)、select\_type列常见的有:A:
小尉迟
•
2年前
IntelliJ IDEA版本控制功能不显示颜色提示怎么解决
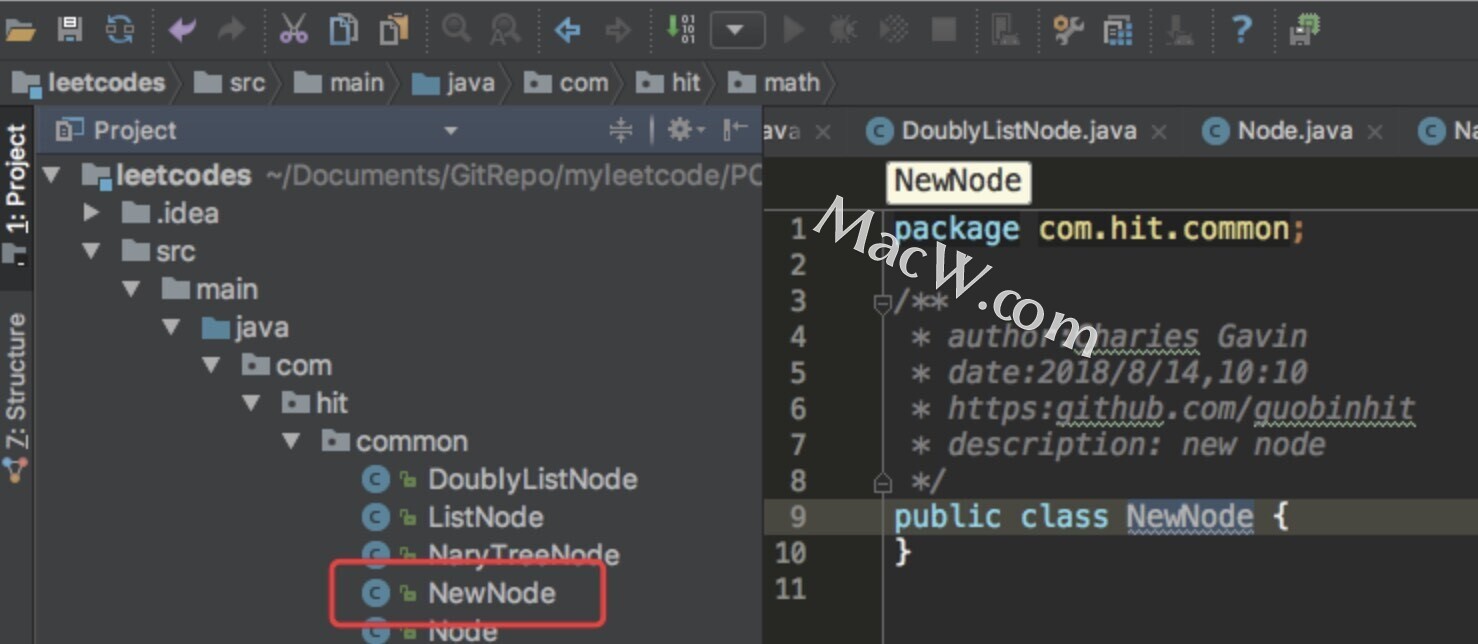
在使用本控制功能时,新增文件或者打开文件IDEA就会给出颜色提示,以区分文件类型,如新增、或者未加入控制版本。但偶尔会出现导入checkout新项目到本地的时候,不显示颜色提示,这个问题如何解决呢?请听下文详解!我们新建了一个名为NewNode的类文件,这
陈杨
•
8个月前
鸿蒙5开发宝藏案例分享---快捷触达的骑行体验
鸿蒙宝藏案例详解:共享单车“丝滑”骑行体验的代码实现🚲💻大家好!上次分享了鸿蒙那个超棒的共享单车体验案例,很多朋友留言说想看代码细节。没问题!这就带大家深入代码层,看看那些“丝滑”的体验(扫码直达、实时状态窗、路径规划)到底是怎么敲出来的。官方文档有时
GeorgeGcs
•
6个月前
【HarmonyOS】应用设置全屏和安全区域详解
【HarmonyOS】应用设置全屏和安全区域详解一、前言IDE创建的鸿蒙应用,默认采取组件安全区布局方案。顶部会预留状态栏区域,底部会预留导航条区域。这就是所谓的安全区域。如果不处理,界面效果很割裂。所以业内UI交互设计,都会设置应用为全屏布局。将页面绘制
1
•••
100
101
102
•••
509