推荐
专栏
教程
课程
飞鹅
本次共找到3884条
mysql分页查询语句
相关的信息
捉虫大师
•
4年前
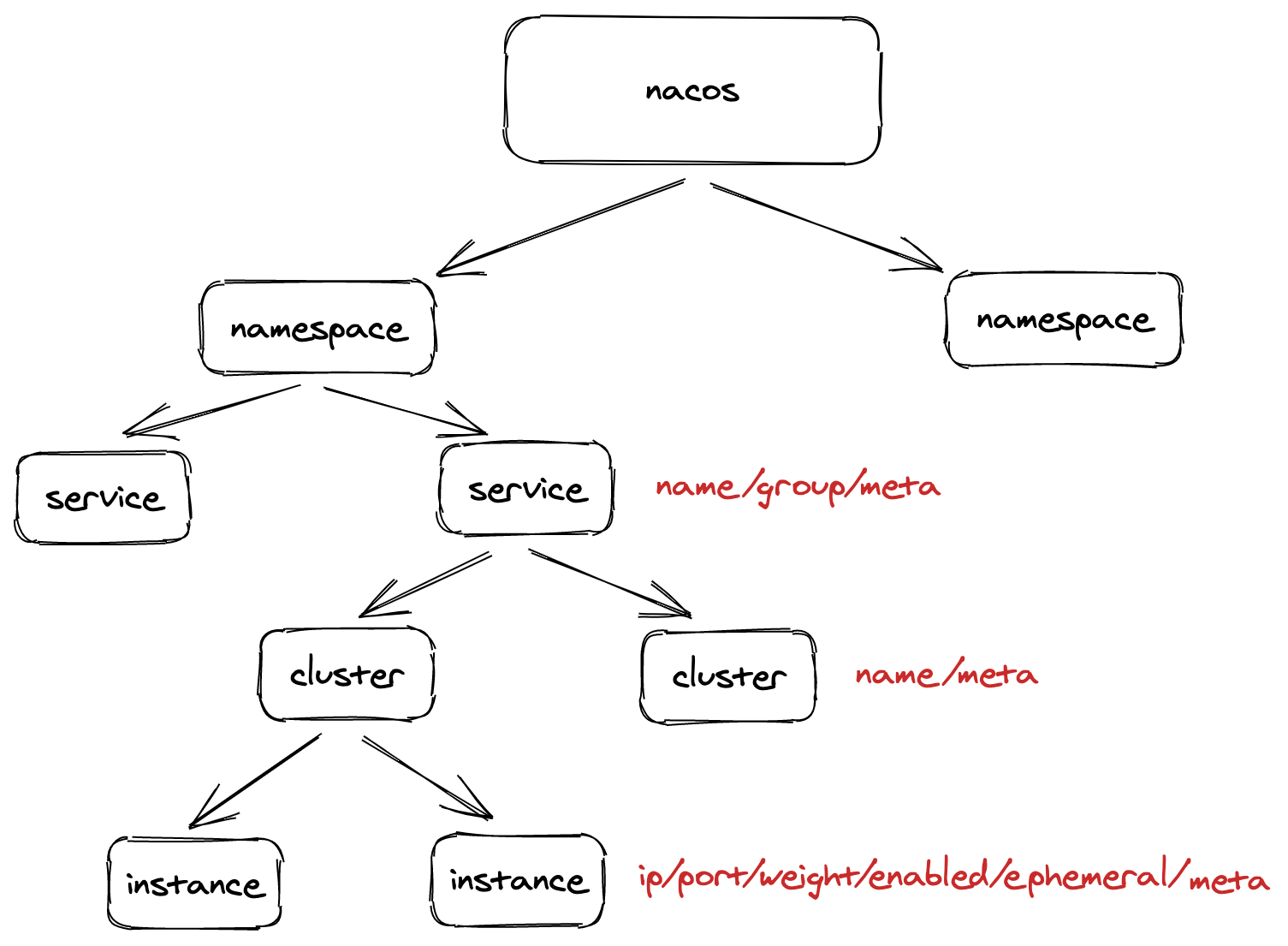
我在组内的Nacos分享
本文已收录https://github.com/lkxiaolou/lkxiaolou欢迎star。Nacos简介Nacos:NamingandConfigurationService,可打包部署配置中心和注册中心,也可独立部署其中之一,配置中心、控制台依赖mysql,由阿里巴巴2018年8月开源,github19.1kstar(截止20
Wesley13
•
4年前
MongoDB 存储引擎说明
MongoDB存储引擎说明MongoDB存储引擎可以插件化(3.0开始提供插件化API),根据不同的场景选择不同的存储引擎,跟Mysql有点类似。MongoDB常用存储引擎:WiredTiger,MMAPv1,InMemoryMongoDB存储引擎之WiredTiger3.2版本开始WiredTiger已经是M
Stella981
•
4年前
SpringBoot2.2.2版本自动建表
环境idea2019.2 jdk1.8 数据库mysql5.7项目结构!(https://oscimg.oschina.net/oscnet/3179dc9eee1e56f4ce94321ca71451f2f43.png)newProject 使用springboot快速搭建web项目 选好sdk next
Wesley13
•
4年前
PHP常用代码大全(新手入门不可错过的好文章)
php常用代码大全,可以作为php入门教程(https://www.oschina.net/action/GoToLink?urlhttp%3A%2F%2Fwww.jbxue.com%2Fwb%2Fphp)使用,确实不错,收藏一下。1、连接MYSQL数据库代码<?php$connecmysql\_connect("localhost
Easter79
•
4年前
TiDB 部署及数据同步
简介TiDB是PingCAP公司受GoogleSpanner/F1论文启发而设计的开源分布式HTAP(HybridTransactionalandAnalyticalProcessing)数据库,结合了传统的RDBMS和NoSQL的最佳特性。TiDB兼容MySQL,支持无限的水平扩展,具备强一致性和高可用
Wesley13
•
4年前
MySQL数据库InnoDB存储引擎Log漫游(1)
作者:宋利兵来源:MySQL代码研究(mysqlcode)0、导读本文介绍了InnoDB引擎如何利用UndoLog和RedoLog来保证事务的原子性、持久性原理,以及InnoDB引擎实现UndoLog和RedoLog的基本思路。00–UndoLogUndoLog是为了实现事务的原子性,
Stella981
•
4年前
Linux锐速当前连接数等状态查询,service serverSpeeder status 服务,帮助信息
使用serverSpeeder服务进行锐速的启动,停止,以及重新加载配置等操作;各参数说明如下:1.serviceserverSpeederstart:启动锐速,加载加速模块;使用/serverspeeder/etc/config文件中的配置作为模块加载时的初始化参数;1.serviceserverSp
Stella981
•
4年前
GraphQL 使用介绍
!(https://oscimg.oschina.net/oscnet/9d854df9aa4e01f403bbb6ae4c9da2afbdf.jpg)GraphQL是Fackbook的一个开源项目,它定义了一种查询语言,用于描述客户端与服务端交互时的数据模型和功能,相比RESTfulAPI主要有以下特点:根据需要返回数据
Stella981
•
4年前
Elasticsearch学习记录(1.安装,简单的查询,聚合,防止数据重复,冲突控制等)
首先我的学习是基于该教程进行的(下列部分代码文字出自该教程,在学习过程中增加我自己的理解和补充,便于更好的裂解和学习,并指出下列教程错误的地方):http://es.xiaoleilu.com/(https://www.oschina.net/action/GoToLink?urlhttp%3A%2F%2Fes.xiaoleilu.com%2F
天翼云开发者社区
•
7个月前
sql优化谓词下推在join场景中的应用
谓词下推的原理是将sql中的限制条件的逻辑尽可能的提前在sql中执行,从而减少加载的数据量,提升下游数据处理的效率以及减少内存消耗。该种方式在hive,MySQL,Doris的语法中均适用。
1
•••
287
288
289
•••
389