推荐
专栏
教程
课程
飞鹅
本次共找到2182条
hadoop集群搭建
相关的信息
Prodan Labs
•
4年前
Kubernetes自定义调度器 — 初识调度框架
Kubernetes已经成为容器编排(Orchestration)平台的事实标准,它为容器化应用提供了简单且高效部署的方式、大规模可伸缩、资源调度等生命周期管理功能。kubescheduler作为kubernetes的核心组件,它负责整个集群资源的调度功能,根据特定的调度算法或调度策略,将Pod调度到最优的Node节点,使集群的资源得到合理且充分的利用。
Chase620
•
4年前
Dubbo 源码分析 - 集群容错之Directory
注:本系列文章已捐赠给Dubbo社区,你也可以在Dubbo中阅读本系列文章。1\.简介前面文章分析了服务的导出与引用过程,从本篇文章开始,我将开始分析Dubbo集群容错方面的源码。这部分源码包含四个部分,分别是服务目录Directory、服务路由Router、集群Cluster和负载均衡LoadBalance。这几个部分的源码逻辑比
Easter79
•
4年前
SQL on Hadoop性能对比-Hive、Spark SQL、Impala
1三种语言、三套工具、三个架构不了解SQLonHadoop三驾马车-Hive、SparkSQL、Impala吗?听小编慢慢道来1HiveApacheHive数据仓库软件提供对存储在分布式中的大型数据集的查询和管理,它本
Stella981
•
4年前
CoreOS实践指南(五):分布式数据存储Etcd(上)
分布式数据的存储一直是解决集群服务消息同步和协调操作的核心关注点。在这个系列的上一篇(https://www.oschina.net/action/GoToLink?urlhttp%3A%2F%2Fwww.csdn.net%2Farticle%2F20150114%2F2823554%2F2),介绍了用于集群管理的Fleet服务,而Fleet的功能
Easter79
•
4年前
TiDB 最佳实践系列(四)海量 Region 集群调优
作者:张博康在TiDB的架构中,所有的数据按照range划分成一个个Region分布在多个TiKV实例上。随着数据的写入,一个集群中会产生上百万,甚至千万个Region。而量变引起质变,单TiKV实例上过多的Region无疑会带来比较大的负担,进而影响整个集群的性能表现。本文将介绍TiKV核心模块Raftstore的
Stella981
•
4年前
Centos7安装hadoop2.7.5(单节点)
1.安装JavaJDK编辑配置文件vim/etc/profile添加以下内容exportJAVA_HOME/usr/local/java/jdk1.7.0_79exportPATH$JAVA_HOME/bin:$PATHexportCLASSPATH
Stella981
•
4年前
Kettle构建Hadoop ETL实践(一):ETL与Kettle
点击上方蓝色字体,选择“设为星标”回复”资源“获取更多资源!(https://oscimg.oschina.net/oscnet/c89e158d10cd4b32aa814d82441219a9.jpg)!(https://oscimg.oschina.net/oscnet/5e8f53277a9c4e51
Stella981
•
4年前
Kettle构建Hadoop ETL实践(二):安装与配置
点击上方蓝色字体,选择“设为星标”回复”资源“获取更多资源!(https://oscimg.oschina.net/oscnet/bab3ab8729664e4292cd3d91cf2b98fb.jpg)!(https://oscimg.oschina.net/oscnet/1c9db90b4b05450e
此账号已注销
•
3年前
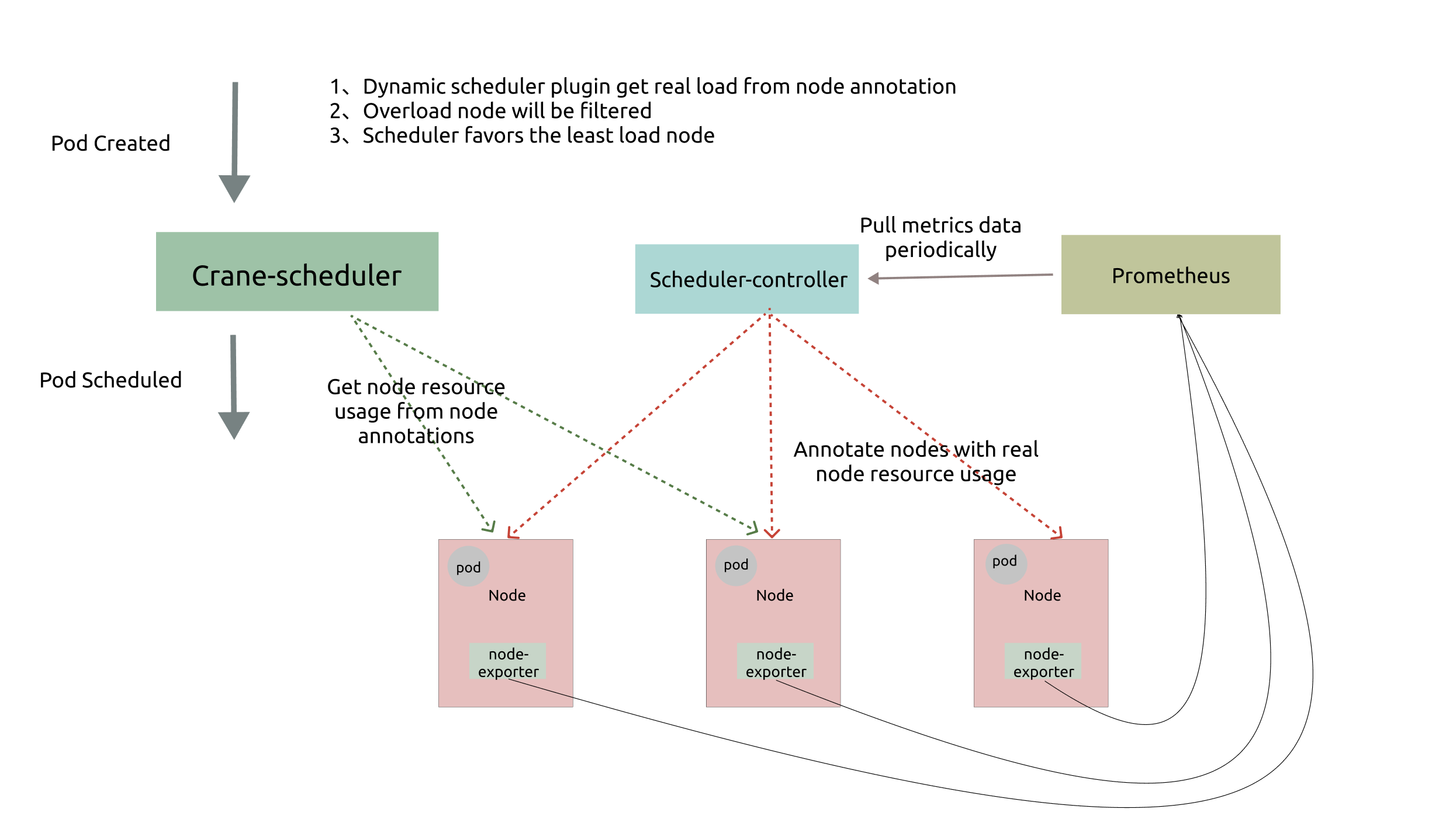
Crane-scheduler:基于真实负载进行调度
作者邱天,腾讯云高级工程师,负责腾讯云TKE动态调度器与重调度器产品。背景原生kubernetes调度器只能基于资源的resourcerequest进行调度,然而Pod的真实资源使用率,往往与其所申请资源的request/limit差异很大,这直接导致了集群负载不均的问题:1.集群中的部分节点,资源的真实使用率远低于resourc
程序员小五
•
2年前
什么是专有云(专属)?
专有云是基于公有云网络进行服务集群独立部署,既能享受公有云的稳定链路服务,又具备资源隔离的优势。适用对象:高消息量、高并发、有实时数据监控服务诉求以及对品质有要求高的客户部署方式:在公有云上有独立的计算集群服务特点:自既能享受公有云的稳定链路服务,又具备资
1
•••
52
53
54
•••
219