推荐
专栏
教程
课程
飞鹅
本次共找到4091条
dubbo源码分析
相关的信息
Irene181
•
4年前
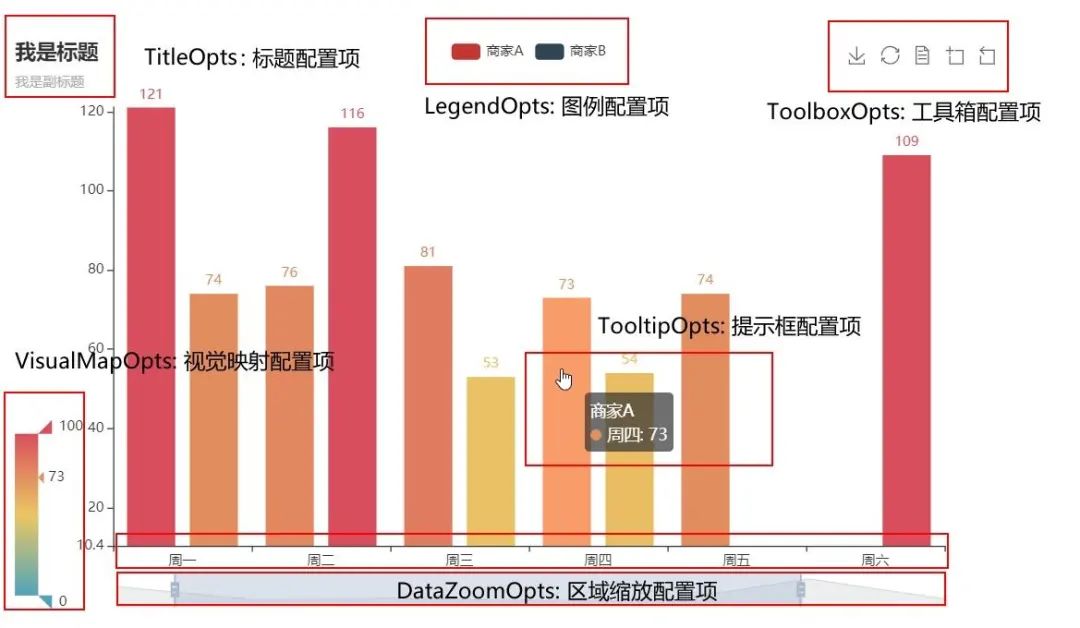
python数据分析——pyecharts柱状图全解(小白必看)
一、pyecharts简介pyecharts主要基于Web浏览器进行显示,绘制的图形比较多,包括折线图、柱状图、饼图、漏斗图地图和极坐标图等。使用pyecharts绘图代码量很少,但绘制的图形比较美观。pyecharts分为v0.5.X和v1两个大版本,v0.5.X和v1间不兼容,v1是一个全新的版本v0.5.X支持Python2
CuterCorley
•
4年前
Python数据分析实战(3)Python实现数据可视化
一、数据可视化介绍数据可视化是指将数据放在可视环境中、进一步理解数据的技术,可以通过它更加详细地了解隐藏在数据表面之下的模式、趋势和相关性。Python提供了很多数据可视化的库:matplotlib是Python基础的画图库,官网为,在案例地址中介绍了很多种类的图和代码示例。pandas是在matplotlib的基础上实现
Wesley13
•
4年前
java模拟JVM的GCRoots追踪算法,对象可达性分析
本文是个人学习《从0开始带你成为JVM实战高手》内容总结,详细内容扫描二维码!(https://oscimg.oschina.net/oscnet/f18738cc2bdb60514e276b710adbb434923.png),有问题可以加群讨论 !(https://oscimg.oschina.net/oscnet/aeb43c2f9
Karen110
•
4年前
女神周迅离婚,Python分析国内离婚情况,结果触目惊心!
2020年的最后一段时间里,大家都在期盼着新一年到来的日子里,又有一位重量级的女明星宣布结束了自己的婚姻。12月23日中午,周迅和高圣远在微博中向大家宣布了自己的离婚的消息,一时间成为了微博的沸点话题。大家为他们感到惋惜的同时,也祝福两人以后都能够各自安好,拥有自己美好的人生。其实离婚的话题,在我们的日常生活中,已经不算是非常新鲜的话题了,根据民政部
Stella981
•
4年前
SparkSql学习1 —— 借助SQlite数据库分析2000万数据
总所周知,Spark在内存计算领域非常强势,是未来计算的方向。Spark支持类Sql的语法,方便我们对DataFrame的数据进行统计操作。但是,作为初学者,我们今天暂且不讨论Spark的用法。我给自己提出了一个有意思的思维游戏:Java里面的随机数算法真的是随机的吗?好,思路如下:1\.取样,利用Java代码随机生成2000万条01
Stella981
•
4年前
Mybatis useGeneratedKeys 填充自增主键值(使用Mysql)的原理分析
一、Mybatis配置<insertid"insert"parameterType"com.test.TestDO"keyProperty"id"useGeneratedKeys"true"useGeneratedKeys“true”时,mybatis会将自增ID值填充到TestDO对象中的id(
Stella981
•
4年前
Hadoop源代码分析(包hadoop.mapred中的MapReduce接口)
前面已经完成了对org.apache.hadoop.mapreduce的分析,这个包提供了HadoopMapReduce部分的应用API,用于用户实现自己的MapReduce应用。但这些接口是给未来的MapReduce应用的,目前MapReduce框架还是使用老系统(参考补丁HADOOP1230(https://www.oschina.net/act
Stella981
•
4年前
Spring+Log4j+ActiveMQ实现远程记录日志——实战+分析
应用场景随着项目的逐渐扩大,日志的增加也变得更快。Log4j是常用的日志记录工具,在有些时候,我们可能需要将Log4j的日志发送到专门用于记录日志的远程服务器,特别是对于稍微大一点的应用。这么做的优点有:可以集中管理日志:可以把多台服务器上的日志都发送到一台日志服务器上,方便管理、查看和分析
Stella981
•
4年前
Alamofire4.x开源代码分析(一)使用方法
!输入图片说明(https://static.oschina.net/uploads/img/201706/28090437_aIT1.png"在这里输入图片标题")本着了解框架的实现思路和学习Swift的目的开启本系列的博客.本系列参考Alamofire(https://www.oschina.net/action/GoToLink?urlh
Stella981
•
4年前
Javascript中,实现类与继承的方法和优缺点分析
Javascript是一种弱类型语言,不存在类的概念,但在js中可以模仿类似于JAVA中的类,实现类与继承第一种方法:利用Javascript中的原型链1//首先定义一个父类23functionAnimal(name,age){4//定义父类的属性5thi
1
•••
260
261
262
•••
410