推荐
专栏
教程
课程
飞鹅
本次共找到5779条
集群技术
相关的信息
Prodan Labs
•
4年前
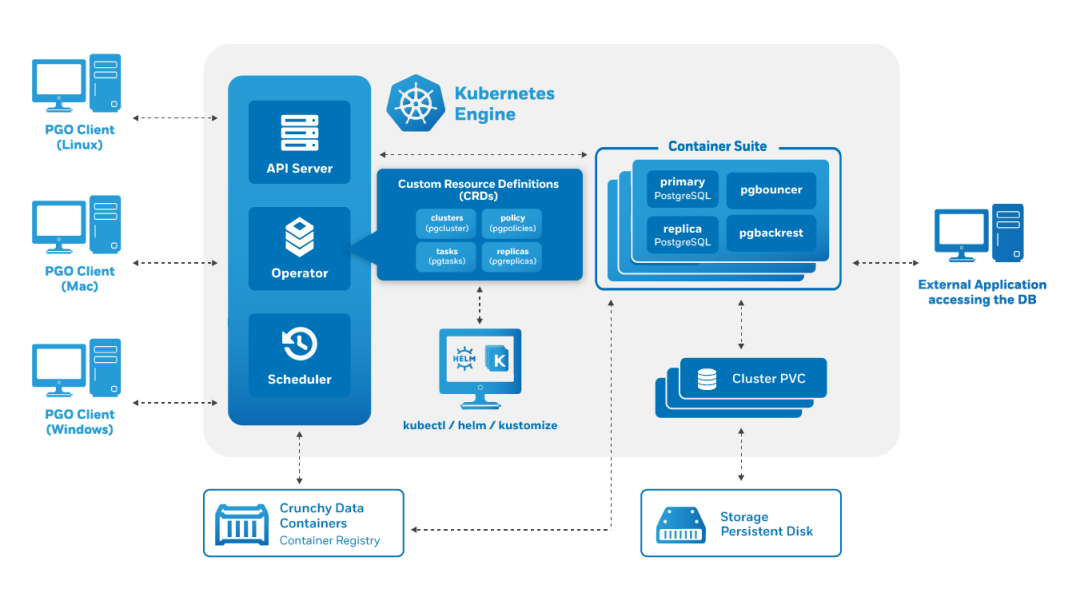
Kubernetes部署高可用PostgreSQL集群
PostgreSQL是一个功能强大的开源关系数据库,它使用和扩展了SQL语言,并结合了许多安全存储和扩展最复杂数据工作负载的功能。PostgreSQL的起源可以追溯到1986年,作为加利福尼亚大学伯克利分校POSTGRES项目的一部分,与Linux内核相似,PostgreSQL是由社区驱动的开源项目,由全世界贡献者所维护。Postgre
Easter79
•
4年前
springboot部署到tomcat
把springboot项目按照平常的web项目一样发布到tomcat容器下多点经验:1.保证运行环境的jdk和开发环境一致,不然class文件无法被编译2.保证tomcat和java的版本匹配,不然tomcat无法启动3.集群一般会进行ip和域名的映射,如果tomcat服务器不在集群内,需要在所在服务器进行
Prodan Labs
•
4年前
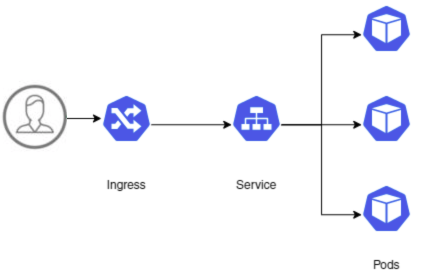
Kubernetes Ingress — NGINX
在Kubernetes中,Service是一种抽象的概念,它定义了每一组Pod的逻辑集合和访问方式,并提供一个统一的入口,将请求进行负载分发到后端的各个Pod上。Service默认类型是ClusterIP,集群内部的应用服务可以相互访问,但集群外部的应用服务无法访问。为此Kubernetes提供了NodePorts,LoadBalan
此账号已注销
•
4年前
作业帮上万个 CronJob 和在线业务混部,如何解决弱隔离问题并进一步提升资源利用率?
作者吕亚霖,作业帮基础架构架构研发团队负责人。负责技术中台和基础架构工作。在作业帮期间主导了云原生架构演进、推动实施容器化改造、服务治理、GO微服务框架、DevOps的落地实践。别路,作业帮基础架构高级研发工程师,在作业帮期间,负责多云K8s集群建设、K8s组件研发、Linux内核优化调优相关工作。背景作业帮在云原生容器化改造的过程中,随着
Stella981
•
4年前
Eureka Server集群重启问题追踪
问题在生产环境重启EurekaServer集群的时候,发现订单客户端调用分布式Id生成服务出错,1Caused by: com.netflix.client.ClientException: Load balancer does not have available server for client: IDG显示订单服务调不到
Stella981
•
4年前
Nginx+Tomcat搭建高性能负载均衡集群
一、 工具 nginx1.8.0 apachetomcat6.0.33二、 目标 实现高性能负载均衡的Tomcat集群: !(https://imgblog.csdn.net/20150819113525774)三、 步骤 1
Stella981
•
4年前
POLARDB v2.0 技术解读
回顾POLARDB1.0POLARDB1.0主要的改进包括采用了计算存储分离的架构,完全兼容MYSQL,性能是原生MySQL的6倍。一个用户集群可以在分钟级弹性扩展到16个计算节点,对业务完全透明的计算和存储分离代理,从库延迟仅毫秒级。存储为分布式块存储,可以弹性扩展至100TB的规模。存储层面采用多副本技术,使得数据库的RPO做到了0,完全没有丢
Stella981
•
4年前
LVS,HAPROXY,NGINX各自的优缺点
Nginx/LVS/HAProxy的基于Linux的开源免费的负载均衡软件。LVS:使用集群技术和Linux操作系统实现一个高性能、高可用的服务器,它具有很好的可伸缩性、可靠性和可管理性,是一款强大实用的开源软件。LVS的优点:1:抗负载能力强、是工作在网络4层之上仅作分发之用,没有流量的产生,这个特点也决定了它在负载均衡软件里的性能最强的,也保
Wesley13
•
4年前
CDH集群安装配置(三)
集群时间同步(主节点)1\.查看是否安装ntp服务,如果没有安装rpmqa|grepntpd查看命令yuminstallntp安装命令2\.修改配置vi/etc/ntp.conf去掉这个注释,将地址改成网段地址restrict10.228.86.252
乌秃头
•
1年前
docker-compose 安装arangodb集群
先构建一个secret文件arangodbcreatejwtsecretsecretarangodb.secretdockercompose.ymlversion:"3"services:agency:image:arangodb:latestcontai
1
•••
28
29
30
•••
578