推荐
专栏
教程
课程
飞鹅
本次共找到65条
蚂蚁森林
相关的信息
Irene181
•
4年前
手把手教你用Scrapy爬虫框架爬取食品论坛数据并存入数据库
大家好,我是杯酒先生,这是我第一次写这种分享项目的文章,可能很水,很不全面,而且肯定存在说错的地方,希望大家可以评论里加以指点,不胜感激!一、前言网络爬虫(又称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。百度百科 说人话就是,爬虫是用来海量规则化获取数据
helloworld_78018081
•
4年前
高级java面试题,附答案+考点
蚂蚁金服一面1.两分钟的自我介绍2.二叉搜索树和平衡二叉树有什么关系,强平衡二叉树(AVL树)和弱平衡二叉树(红黑树)有什么区别3.B树和B树的区别,为什么MySQL要使用B树4.HashMap如何解决Hash冲突5.epoll和poll的区别,及其应用场景6.简述线程池原理,FixedThreadPoo
Karen110
•
4年前
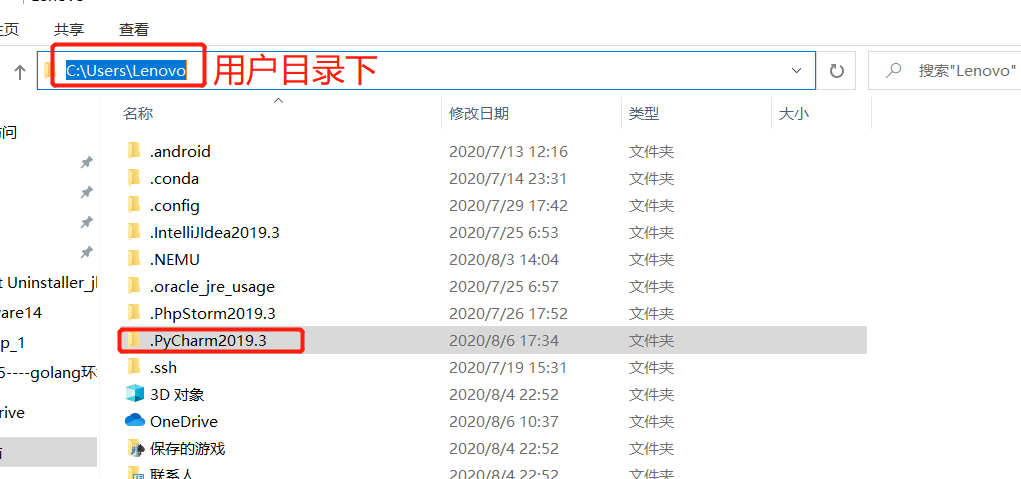
解决安装Pycharm后在C盘下生成大文件的问题
前言上次在整理C盘时,无意间发现了一个这样的文件。在我的用户目录下,有个.PyCharm2019.3这样的文件夹,我猜想和Pycharm可能有什么py关系。那这个文件有多大呢,来操作一下康康。雾草,竟然0.5个G了,我才刚用没多久唉!这对于我这强迫症来说很难受哎,蚂蚁在我心上爬。PyCharm2019.3文件夹的用途是什么呢???里面会有一些配置信息
Wesley13
•
4年前
2019云原生产业大会召开 蚂蚁金服贡献云原生典型实践
4月24日,国内最权威、最大规模的云原生应用大会——2019云原生产业大会在北京召开。本次大会上,中国信息通信研究院重磅发布了《云原生行业应用实践白皮书》和《无服务架构技术白皮书》两份白皮书。《云原生行业应用实践白皮书》系统阐述了云原生架构的主要技术、云原生技术的行业落地实践、云原生应用发展趋势和标准化建议。在金融行业落地实践中,蚂蚁金服的
Stella981
•
4年前
SOFAStack 活动回顾整理集合(含视频回顾)
SOFAStack是蚂蚁金服完全自主研发的金融级分布式架构,包含了构建金融级云原生架构所需的各个组件,如微服务研发框架、RPC框架、服务注册中心、分布式定时任务、限流/熔断框架、动态配置推送、分布式链路追踪、Metrics监控度量、分布式高可用消息队列、分布式事务框架和分布式数据库代理层等。SOFAStack:https://gitee.com/
Stella981
•
4年前
2020稳拿offer宝典,阿里天猫、蚂蚁、钉钉 java 面试题汇总(附解析)
!(https://oscimg.oschina.net/oscnet/up3fe8daac484fa16296efcca6a78cb7c2cf9.JPEG)Java基础面向对象的特征:继承、封装和多态int和Integer有什么区别;Integer的值缓存范围说说反射的用途及实现Http请求的GET和PO
Wesley13
•
4年前
4年Java经验,备战两月成功拿到美团、京东、字节offer
写在前面本人4年java开发经验,从上家公司离职之后恰巧碰上疫情就在家闭关修炼!没日没夜的苦修2个多月,面试了几家公司,最终拿下美团、京东、字节跳动(java高级工程师)offer。我是如何拿下美团等大厂的offer的呢,今天分享我的秘密武器我把一位蚂蚁金服资深架构师整理的【Java核心知识点整理】资料啃完了,这份资料是我看
可莉
•
4年前
2020稳拿offer宝典,阿里天猫、蚂蚁、钉钉 java 面试题汇总(附解析)
!(https://oscimg.oschina.net/oscnet/up3fe8daac484fa16296efcca6a78cb7c2cf9.JPEG)Java基础面向对象的特征:继承、封装和多态int和Integer有什么区别;Integer的值缓存范围说说反射的用途及实现Http请求的GET和PO
Easter79
•
4年前
TOP100summit:【分享实录
王洋:猫眼电影商品业务线技术负责人、技术专家。主导了猫眼商品供应链和交易体系从0到1的建设,并在猫眼与美团拆分、与点评电影业务融合过程中,从技术层面保障了商品业务的平稳切换,同时也是美团点评《领域驱动设计》课程的讲师。在加入猫眼电影之前,曾就职于蚂蚁金服,参与了阿里网商银行从0到1的建设,以及支付宝钱包、花呗等产品的研发。导读:互联网电影行业在2016年
Stella981
•
4年前
Gdevops峰会:一起探讨国产分布式数据库的选型与应用
从过去40年至今,数据库的形态基本经历了传统商业数据库、开源数据库到云原生数据库的演进过程。云时代下数据库将如何革新与创变?金融行业核心数据库迁移与建设如何安全平稳展开?Gdevops全球敏捷运维峰会由阿里巴巴、腾讯、工商银行、民生银行、爱可生、蚂蚁金服等几大巨头,对云原生数据库进行探索,带领我们眺望数据库发展变革更长远的未来。!
1
2
3
4
5
6
7