推荐
专栏
教程
课程
飞鹅
本次共找到6505条
版本库
相关的信息
CuterCorley
•
4年前
商业数据分析从入门到入职(9)Python网络数据获取
@toc前言本文主要讲Python最常见的应用之一——网络数据获取,即爬虫:先介绍了网页和网络的基础知识,为从网页中获取数据打好基础;接下来以两个案例介绍从网络中获取数据和处理数据的不同方式,以进一步认识Python爬虫和数据处理。一、网络和网页基础知识1.数据来源数据源有很多,可以从数据库中获取,可以从文件中获取,也可以从
Karen110
•
4年前
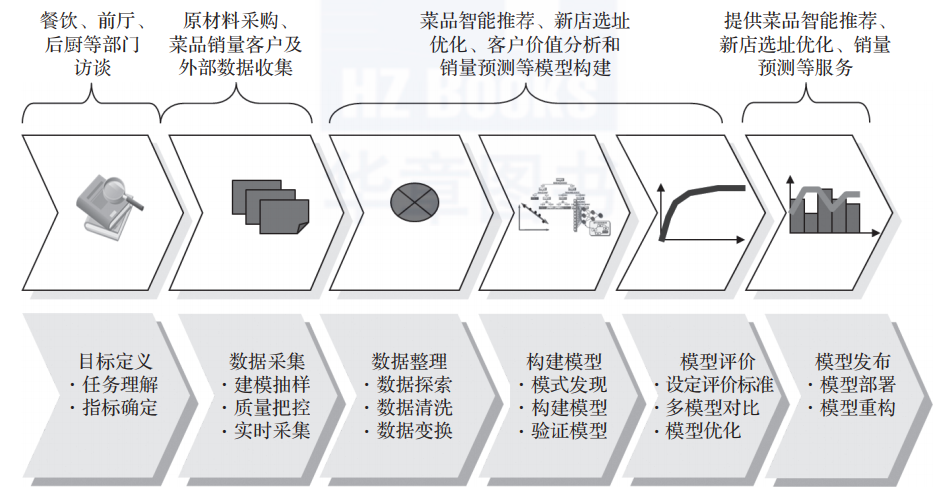
数据挖掘建模过程全公开
「数仓宝贝库」,带你学数据!导读:本文以餐饮行业的数据挖掘应用为例,详细介绍数据挖掘的建模过程。数据挖掘的基本任务包括利用分类与预测、聚类分析、关联规则、时序模式、偏差检测、智能推荐等方法,帮助企业提取数据中蕴含的商业价值,提高企业的竞争力。对餐饮企业而言,数据挖掘的基本任务是从餐饮企业采集各类菜品销量、成本单价、会员消费、促销活动等内部数据,
请叫我海龟先生
•
4年前
js 理解模块化
经常在面试或者其他文章看到关于模块化的问题,之前也只是寥寥看了几次,对于CommonJS,AMD,ES6也说不出个所以然,于是今天抽空好好看了红宝书第4版关于模块化的介绍,这里记录一下。理解模块模式初衷在开发中肯定有设计大量三方库或者业务逻辑代码,较好的方式是将其分割为多个小模块,最后以一定的方式连接起来
Chase620
•
4年前
vue-cli3.0结合lib-flexible、px2rem实现移动端适配,完美解决第三方ui库样式变小问题
vuecli3.0结合libflexible、px2rem实现移动端适配,完美解决第三方ui库样式变小问题公司最近做的一个移动端项目从搭框架到前端开发由我独立完成,以前做移动端适配用的媒体查询,这次想用点别的适配方案,然后就采用了vuecli3.0结合libflexible、px2rem实现移动端适配的方案,开发过程中也遇到一些坑,自己选的方案自己
Wesley13
•
4年前
mysql 修改字符集为utf8mb4
一般情况下,我们会设置MySQL默认的字符编码为utf8,但是近些年来,emoji表情的火爆使用,给数据库带来了意外的错误,就是emoji的字符集已经超出了utf8的编码范畴😄令人抓狂的字符编码问题谈到字符编码问题,会让很多人感到头疼,这里不在深究各个字符编码的特点和理论,这里只说下Unicode和utf8字符编码的关系
Wesley13
•
4年前
Java并发系列 1
程序开发中并发的场景还是比较常见的,特别是当下分布式环环境开发大行其道的情况下,从前端处理,到服务调用、缓存处理、数据库处理、文件处理、消息处理等等,无不需要并发的知识。从今天开始,我要写一个关于Java并发的系列文章,希望各位可以从中受益。我们先从基础的线程开始说起!一、线程基础知识从宏观来看,简单说一下进程:所谓进程
Easter79
•
4年前
SpringBoot2.0之六 多环境配置
开发过程中面对不同的环境,例如数据库、redis服务器等的不同,可能会面临一直需要修改配置的麻烦中,在以前的项目中,曾通过Tomcat的配置来实现,有的项目甚至需要手动修改相关配置,这种方式费时费力,出错的概率还极大,SpringBoot为我们提供了更加简单方便的配置方案来解决多环境的配置问题,下面我们看看怎么实现。一、新建一个项目(本文以上篇的代码
Stella981
•
4年前
SQL JOIN语法,以及JOIN where 和and区别,还有where和join效率问题。
语法join用于根据两个或多个表中的列之间的关系,从这些表中查询数据。Join和Key有时为了得到完整的结果,我们需要从两个或更多的表中获取结果。我们就需要执行join。数据库中的表可通过键将彼此联系起来。主键(PrimaryKey)是一个列,在这个列中的每一行的值都是唯一的。在表中,每个主键的值都是唯一的。这
Wesley13
•
4年前
MySQL 分区表原理及使用详解
1\.什么是表分区?表分区,是指根据一定规则,将数据库中的一张表分解成多个更小的,容易管理的部分。从逻辑上看,只有一张表,但是底层却是由多个物理分区组成。2\.表分区与分表的区别分表:指的是通过一定规则,将一张表分解成多张不同的表。比如将用户订单记录根据时间成多个表。分表与分区的区别在于:
Stella981
•
4年前
Redis 分区
Redis分区分区是分割数据到多个Redis实例的处理过程,因此每个实例只保存key的一个子集。分区的优势通过利用多台计算机内存的和值,允许我们构造更大的数据库。通过多核和多台计算机,允许我们扩展计算能力;通过多台计算机和网络适配器,允许我们扩展网络带宽。分区的不足redis的一些特性在分区方面表现的不是很好:
1
•••
628
629
630
•••
651