推荐
专栏
教程
课程
飞鹅
本次共找到10000条
校验和
相关的信息
Wesley13
•
4年前
java容器之HashMap
HashMap采用了数组和链表的数据结构,能在查询和修改方便继承了数组的线性查找和链表的寻址修改,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的。解决哈希冲突的三个方法:a.开放定址法 又被称为再散列法,包括线性探测再散列、二次探测再散列、伪随机探测再散列b.再哈希法 地址冲突后,对哈希结果再次进行哈希,直到
CuterCorley
•
4年前
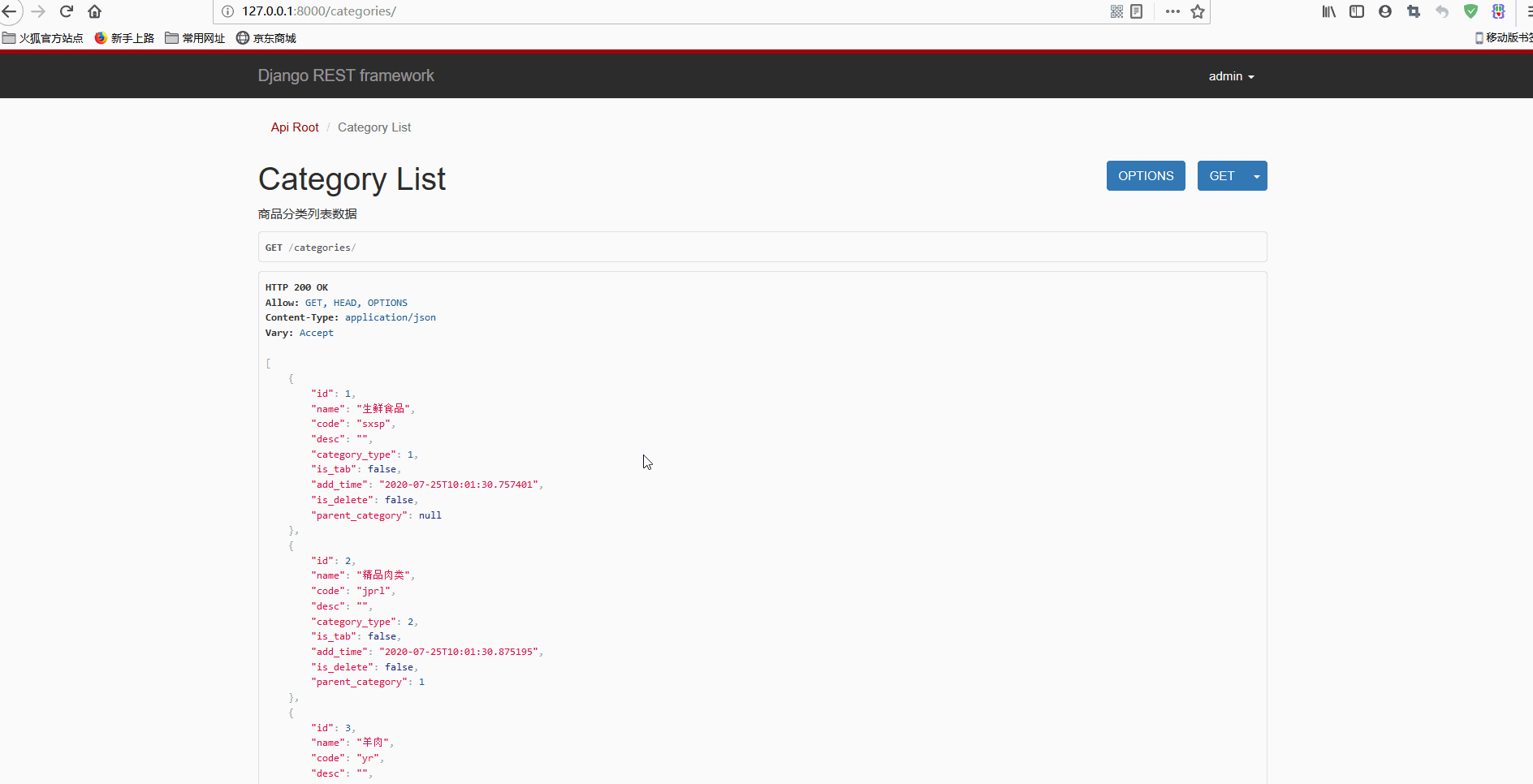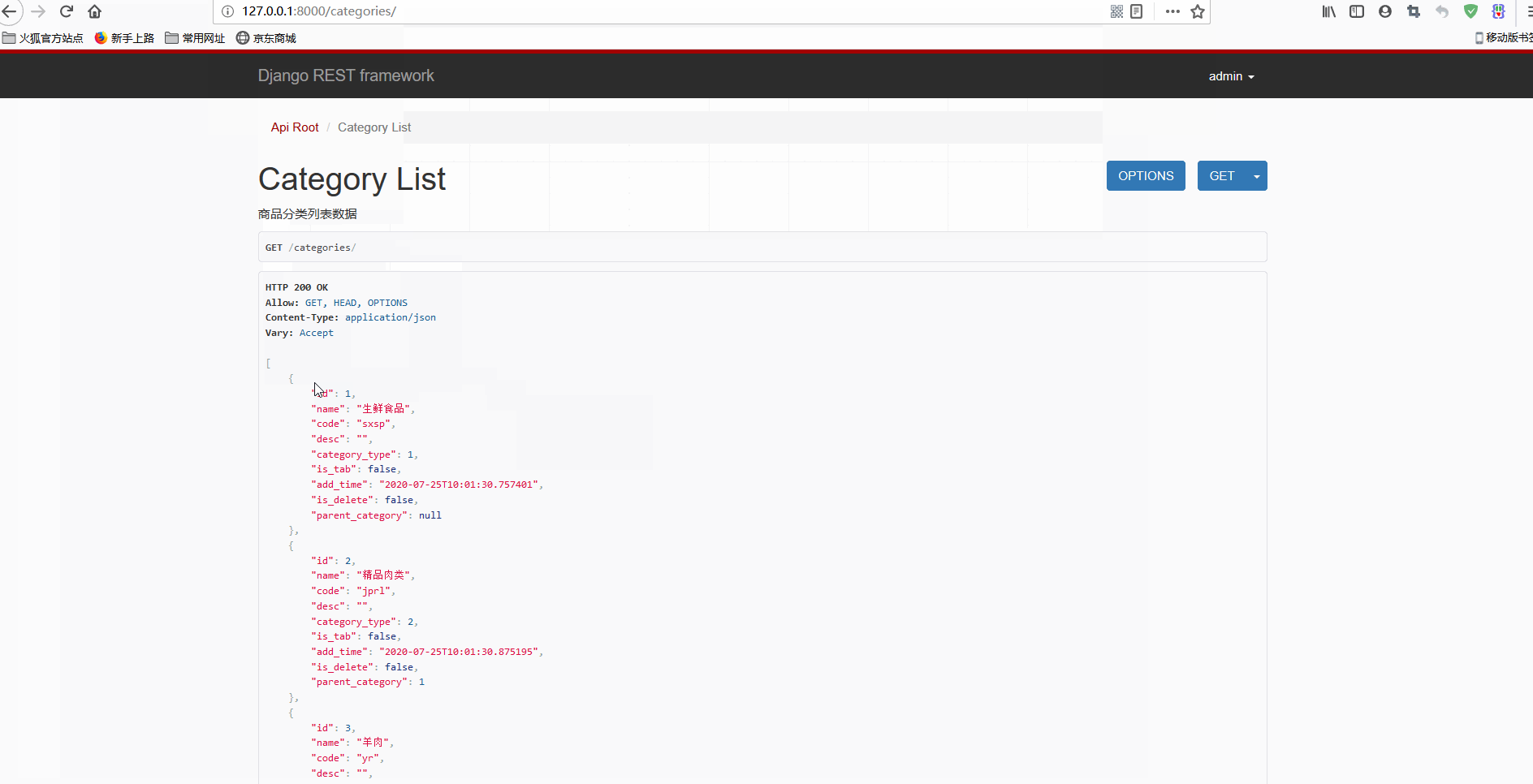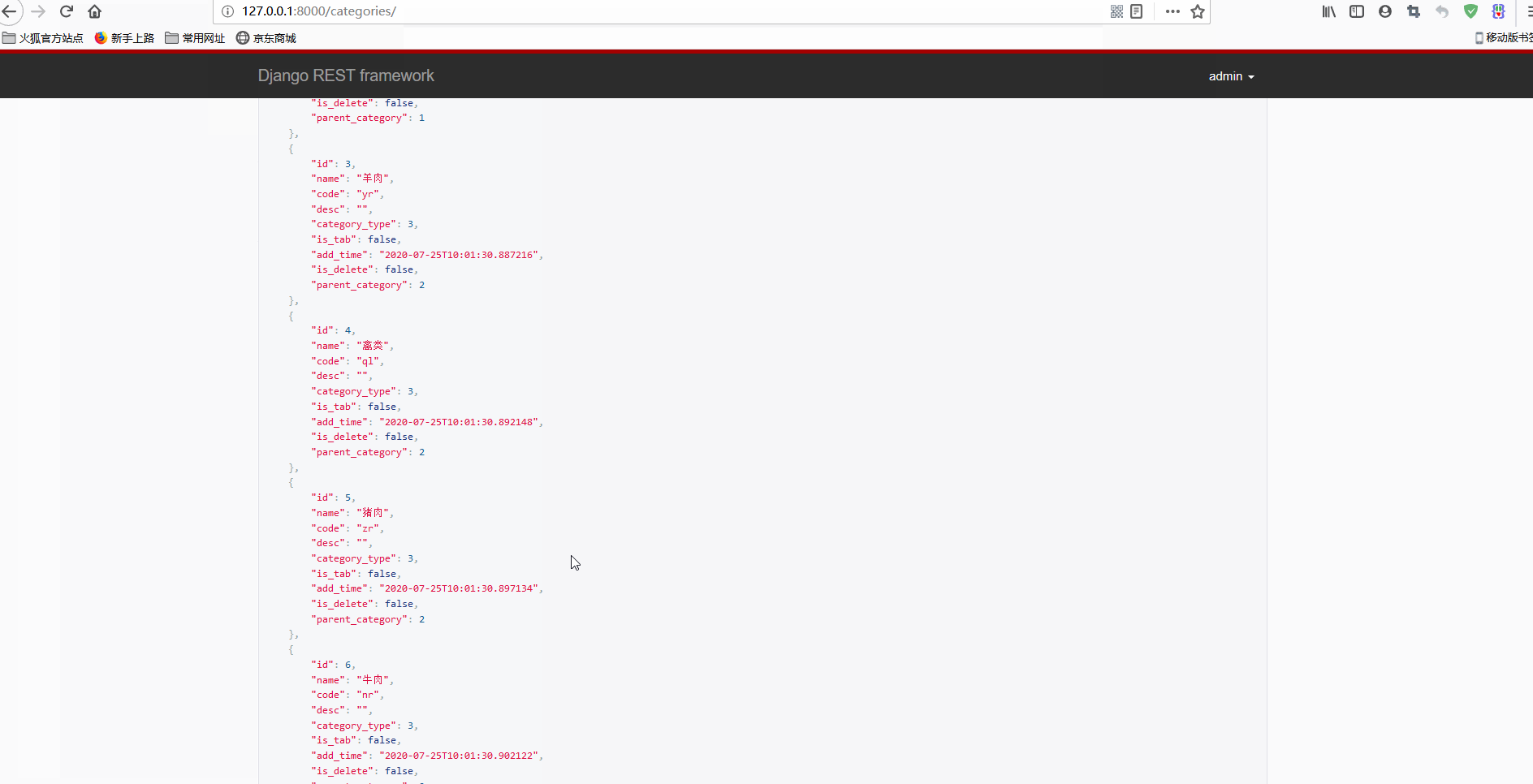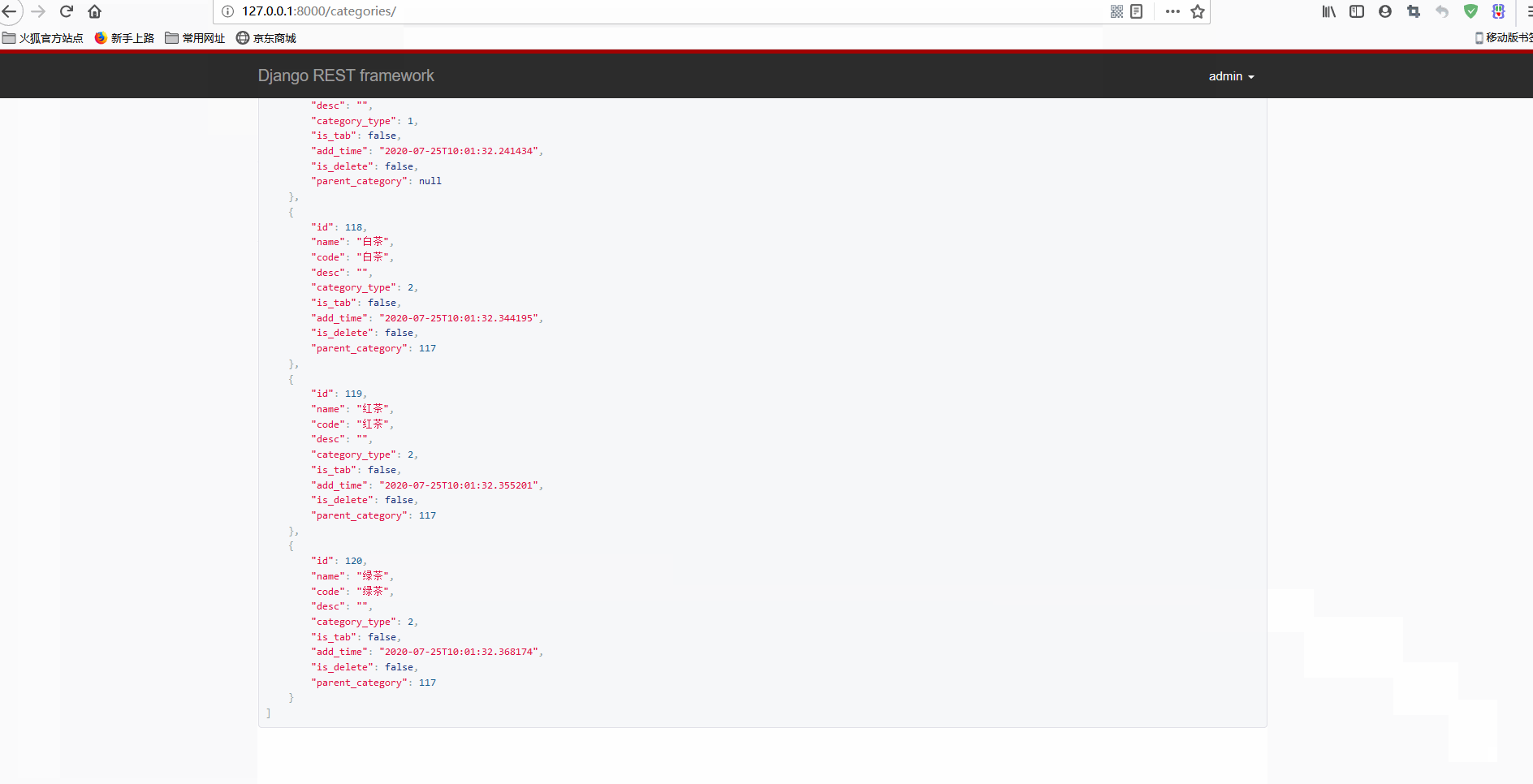
Django+Vue开发生鲜电商平台之6.使用Vue实现商品类别和商品数据前台显示
什么是胸怀?胸怀是人生的志向和抱负,胸怀是人格的品位和质量,胸怀是人对待世界万物气量和风度的定位。胸怀,能使弱者走过别人不敢走的路,攀上别人难以达到的高峰;胸怀,可以使先天低矮的人在别人眼里变得挺拔高大;胸怀,能使一名柔弱的女子充满大丈夫的英雄气概;胸怀,也使一个弱质变得体格健壮。——马云Github和Gitee代码同步更新:;。现在将DRF
徐小夕
•
4年前
如果进阿里前端,代码能力得达到什么程度?
笔者身边有很多在阿里不同部门的朋友,也曾经被面试过阿里,也面试过很多求职者,这里笔者通过自身经验,来谈谈如何面进大厂(比如阿里).为了保证回答的逻辑性和堵有所获,我将按照以下3点来谈前端如何才能进大厂(阿里):阿里不同部门的技术和要求大厂喜欢的求职者需求具备哪些能力和潜质如何打造程序员的职场核心竞争力首先像阿里,字
Stella981
•
4年前
PySpark简介及详细安装教程
Spark在前面已经和大家说过很多了,Python这几天也整理出了很多自己的见解,今天就和大家说下一个新的东西,PySpark,一看名字就知道和前面二者都有很大关系,那么PySpark到底是什么,和之前所说的Spark与Python有什么不一样的呢?今天就和大家简单的聊聊。回忆下Spark的简介:Spark是一种通用的大数据计算框架,是基于
Wesley13
•
4年前
mysql数据库设计规范
一、数据库设计规范1.使用innodb引擎2.数据库和表的字符集统一使用utf83.所有表和字段添加注释4.单表数据量控制<500w5.谨慎使用mysql分区,跨区查询影响性能6.冷热数据分离,缓存7.禁止在数据库中存储图片,文件等大的二进制数据8.禁止在线上做数据库压力测试9.禁止从开发和测试环境直接连
Stella981
•
4年前
C++ STL中哈希表 hash_map介绍
0为什么需要hash\_map用过map吧?map提供一个很常用的功能,那就是提供keyvalue的存储和查找功能。例如,我要记录一个人名和相应的存储,而且随时增加,要快速查找和修改:岳不群-华山派掌门人,人称君子剑张三丰-武当掌门人,太极拳创始人东方不败-第一高手,葵花宝典...这些信息如果保存下来并不复杂,但是找起来比较麻烦
Wesley13
•
4年前
Java 8 stream 实战
概述平时工作用python的机会比较多,习惯了python函数式编程的简洁和优雅。切换到java后,对于数据处理的『冗长代码』还是有点不习惯的。有幸的是,Java8版本后,引入了Lambda表达式和流的新特性,当流和Lambda表达式结合起来一起使用时,因为流申明式处理数据集合的特点,可以让代码变得简洁易读。幸福感爆棚,有没有!本文主要列举一些
Stella981
•
4年前
Centos7上安装docker
Docker从1.13版本之后采用时间线的方式作为版本号,分为社区版CE和企业版EE。社区版是免费提供给个人开发者和小型团体使用的,企业版会提供额外的收费服务,比如经过官方测试认证过的基础设施、容器、插件等。社区版按照stable和edge两种方式发布,每个季度更新stable版本,如17.06,17.09;每个月份更新edge版本,如17.09,1
Wesley13
•
4年前
Go 语言初级教程之六[基本类型]
基本类型像C语言一样,Go提供了一系列的基本类型,常见的布尔,整数和浮点数类型都具备。它有一个Unicode的字符串类型和数组类型。同时该语言还引入了两种新的类型:slice和map。数组和切片Go语言当中的数组不是像C语言那样动态的。它们的大小是类型的一部分,在编译时就决定了。数组的索引还是使用的熟悉的
Easter79
•
4年前
SSM框架(3):配置Spring的事务管理器,实现事务控制
一、相关概念1、不可重复读和幻读的区别 很多人容易搞混不可重复读和幻读,确实这两者有些相似。但不可重复读重点在于update和delete,而幻读的重点在于insert。 如果使用锁机制来实现这两种隔离级别,在可重复读中,该sql第一次读取到数据后,就将这些数据加锁,其它事务无法修改这些数据,就可以实现可重复读了。但
1
•••
443
444
445
•••
1000