推荐
专栏
教程
课程
飞鹅
本次共找到10000条
时间序列数据
相关的信息
此账号已注销
•
4年前
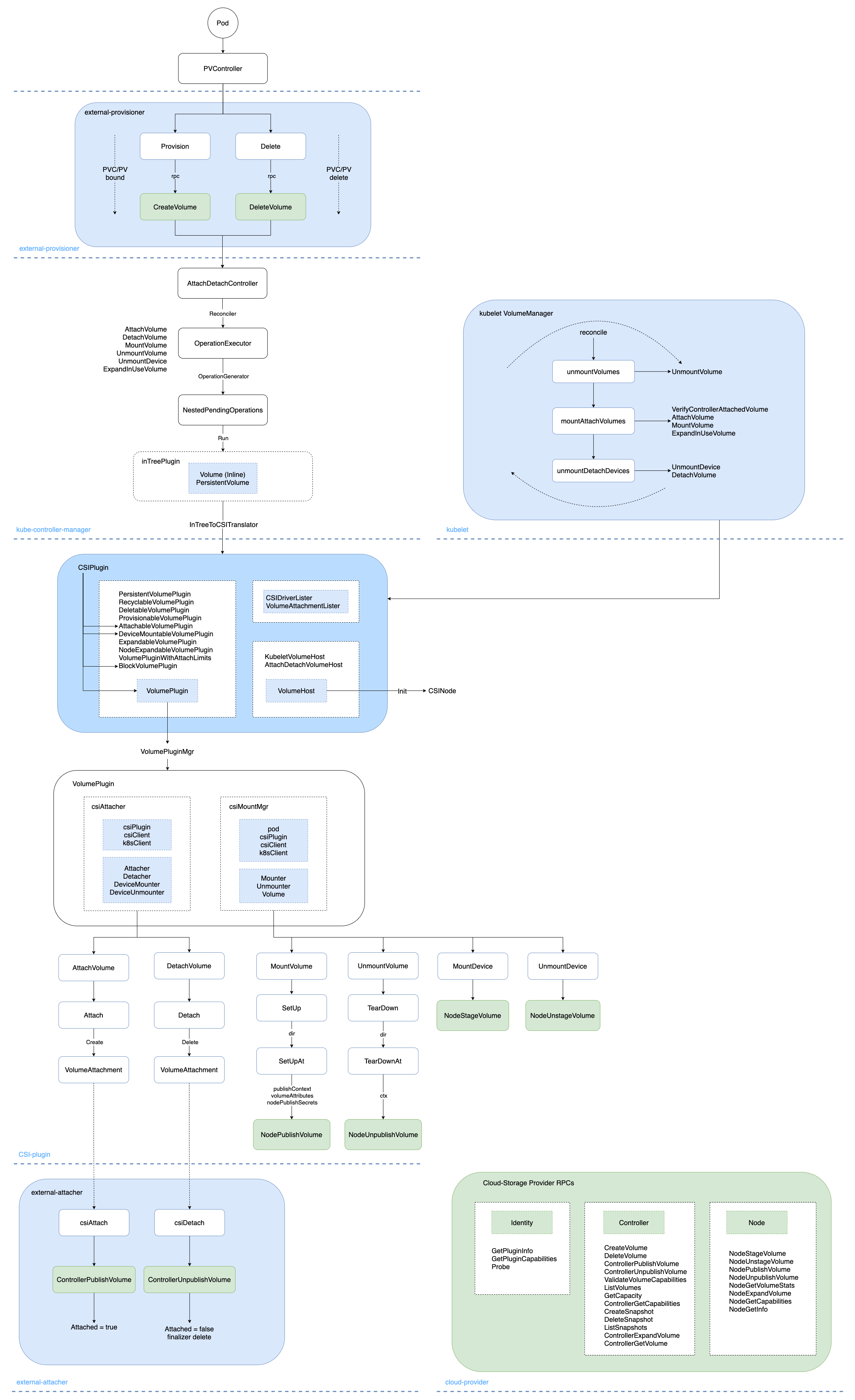
如何接入 K8s 持久化存储?K8s CSI 实现机制浅析
作者王成,腾讯云研发工程师,Kubernetescontributor,从事数据库产品容器化、资源管控等工作,关注Kubernetes、Go、云原生领域。概述进入K8s的世界,会发现有很多方便扩展的Interface,包括CSI,CNI,CRI等,将这些接口抽象出来,是为了更好的提供开放、扩展、规范等能力。K8s持久化存储经历了从in
Wesley13
•
4年前
UDP协议报文格式
今天让我们来认识一下UDP协议的报文格式UDP协议和TCP协议同位于传输层,介于网络层(IP)和应用层之间:UDP数据部分为应用层报文,而UDP报文在IP中承载。如下图:!(https://oscimg.oschina.net/oscnet/74e201602c3a16bf23339e6347610af1f67.png)UDP报文格式
Wesley13
•
4年前
Java8系列之Stream总结
流的简介 官方解释,Stream是Java8的一大亮点,它与java.io包里的InputStream和OutputStream是完全不同的概念。它也不同于StAX对XML的解析的Stream,也不是AmazonKinesis对大数据实时处理的Stream。它是对集合对象功能的增强,她专注于对集合对象进行各种非常便利、高效的聚合操作(ag
Stella981
•
4年前
Hadoop之Mapreduce详解
1、什么是Mapreduce Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上;2、Mapreduce框架结构及核心运行机制
Stella981
•
4年前
ConnectionPool实现redis在python中的连接
这篇文章主要介绍了Python与Redis的连接教程,Redis是一个高性能的基于内存的数据库,需要的朋友可以参考下今天在写zabbixstormjob监控脚本的时候用到了python的redis模块,之前也有用过,但是没有过多的了解,今天看了下相关的api和源码,看到有ConnectionPool的实现,这里简单说下。在ConnectionPoo
Wesley13
•
4年前
RHCE系列之备份工具
我一哥们最近在搞备份,需要用到rsync。因此,鄙人就简单总结了下rsync,也就有了这篇博文,希望对51的博友们有所帮助!RSYNC简介:Rsync(remotesync)是一款开源、快速,多功能、可实现增量的本地或远程数据镜像同步备份优秀工具。它可通过 LAN/WAN 快速同步多台主机间的文件。Rsync 本来是用以取代r
Wesley13
•
4年前
Java中的字符串的最大长度
Java中的字符串的最大长度看String的源码可以看出来,String实际存储数据的是charvalue\\,数组的长度是int类型,整数在java中是有限制的,我们通过源码来看看int类型对应的包装类Integer可以看到,其长度最大限制为2^311,那么说明了数组的长度是0~2^311,那么计算一下就是(2^31121474
Stella981
•
4年前
Flink简介
1. Flink的引入这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop、Storm,以及后来的 Spark,他们都有着各自专注的应用场景。Spark 掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。Spark 的火热或多或少的掩盖了其他分布式计算的系统身影。就像 Flin
天翼云开发者社区
•
3年前
坐标中国|中国速度,挑战极限驱动发展“快车”
1秒5G时代下载数据超500兆1秒浮点运算次数超150000000兆次我国算力总规模居全球第二200秒“九章”量子计算原型机可求解5000万个样本的高斯玻色取样问题1小时C919可巡航约880公里1小时复兴号新型动车组(单列)行进435公里创世
1
•••
968
969
970
•••
1000