推荐
专栏
教程
课程
飞鹅
本次共找到5413条
数据库设计
相关的信息
Chase620
•
4年前
前端GIF生成及优化
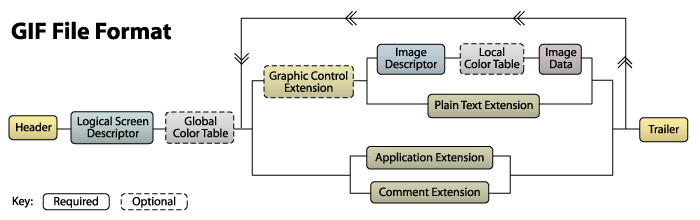
羚珑平台的动图可视化设计之前只支持mp4的导出,但在业务方使用场景中大部分需要投放GIF。故本文主要介绍使用gif.js生成GIF时遇到的一些问题、GIF压缩以及GIF的文件格式和对应编码在gif.js是如何实现的。GIF文件结构介绍位图图形文件格式,采用8位(256色)重现真彩色的图像。它实际上是一种压缩文档,采用LZW压缩算
helloworld_52822375
•
3年前
在线学习系统政务版
政务版专注内部培训政务版介绍:专为政府部门、机关单位和企事业单位设计。风格端庄、整洁,集“学、练、考”于一体的在线教育系统。适用于单位的内部培训、内部考核...一、用户分析1.政府部门2.机关单位3.企事业单位4....总结:政务版用户大致分为以上三类,此类用户使用学习系统均用于内部培训,不考虑营销。所以在系统的选择上更倾向于教育,不需要营销功能
Johnny21
•
4年前
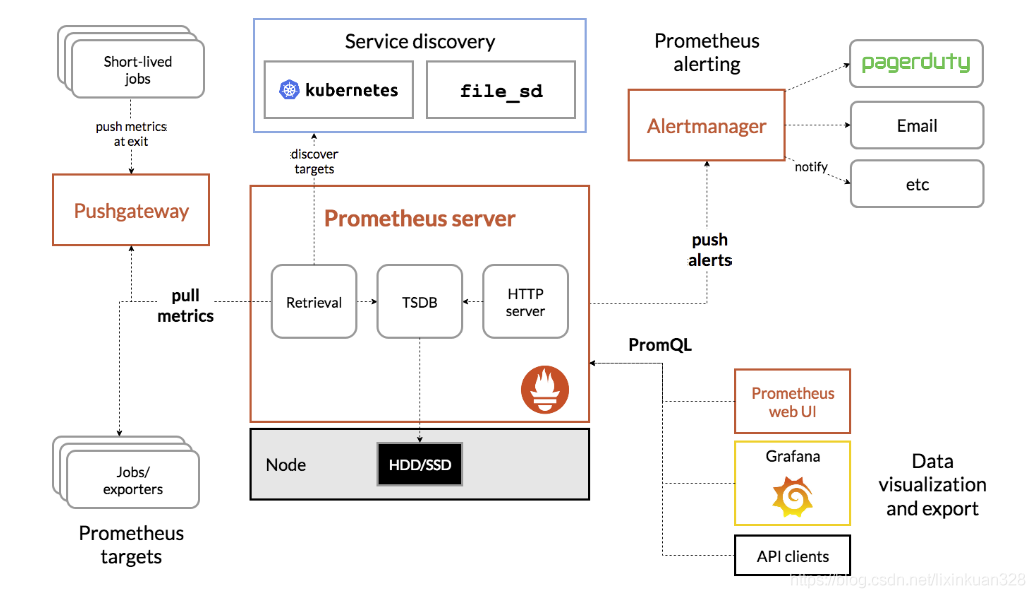
Promethus(普罗米修斯)监控
一、任务背景某某某公司是一家电商网站,由于公司的业务快速发展,公司要求对现有机器进行业务监控,责成运维部门来实施这个项目。任务要求1)部署监控服务器,实现7x24实时监控2)针对公司的业务及研发部门设计监控系统,对监控项和触发器拿出合理意见3)做好问题预警机制,对可能出现的问题要及时告警并形成严格的处理机制4)做好监控告警系统,要求可以实
科工人
•
4年前
一文吃透 Go 语言解密之接口 interface
转载:大家好,我是煎鱼。自古流传着一个传言...在Go语言面试的时候必有人会问接口(interface)的实现原理。这又是为什么?为何对接口如此执着?实际上,Go语言的接口设计在整体扮演着非常重要的角色,没有他,很多程序估计都跑的不愉快了。在Go语言的语义上,只要某个类型实现了所定义的一组方法集,则就认为其就是同一种类型,是一个东西。大家常常称其
Stella981
•
4年前
Python 命令行库的大乱斗
当你想实现一个命令行程序时,或许第一个想到的是用Python来实现。比如CentOS上大名鼎鼎的包管理工具yum就是基于Python实现的。而Python的世界中有很多命令行库,每个库都各具特色。但我们往往不知道其背后的设计理念,也因此在选择时感到迷茫。这些库的作者为何在重复造轮子,他是从哪个角度来考虑,来让命令行库“演变”到一个新的
Wesley13
•
4年前
P1
通过本文,您的收获可能有:从课下部分,了解一些基本部件搭建时可能遇到的坑点,稍微深入一点理解两种状态机的区别;从课上测试部分,可以了解重点的考察内容,明白设计时状态机的类型在测试中的重要性。课下测试部分:课下测试主要考察了splitter的实现,ALU的实现,格雷码计数器的实现,扩位器的实现,以及合法表达式判别的有限状态机问题。本次课下部分比
Easter79
•
4年前
TiDB 在威锐达 WindRDS 远程诊断及运维中心的应用
公司简介 西安锐益达风电技术有限公司成立于2012年1月4日,是一家专业化的工业测量仪器系统、机电产品和计算机软件研发、设计和制造公司,是北京威锐达测控系统有限公司在西安成立的全资子公司。依托大学的科研实力,矢志不渝地从事仪器仪表及测量系统的研究和应用开发,积累了丰富的专业知识和实践经验,具备自主开发高端仪器系统和工程实施的完
Stella981
•
4年前
SpreadJS 纯前端表格控件应用案例:表格数据管理平台
由某科技公司研发的表格数据管理平台,是一款面向业务和企业管理系统定制开发的应用平台,包括类Excel设计器、PC应用端和移动应用端等应用模块。该平台具备强大的业务配置和集成开发能力,对于企业客户的信息系统在管理模式、业务流程、表单界面等个性化需求,均可快速实现个性化配置。下面,让我们一起来看看该公司是如何在“表格数据管理平台”中应用表格技术,实现“
Wesley13
•
4年前
PGET,一个简单、易用的并行调用框架
使用场景当我们的服务收到一个请求后,需要大量调用下游服务获取业务数据,然后对数据进行转换、计算后,响应给请求方。如果我们采用串行获取下游数据,势必会增加响应时长,降低接口的qps。如果是并行获取下游数据,则是不错的。最直接想到的并行获取方法,无非是将一个个获取数据的方法封装成一个个task,然后放到线程池里执行。但这种没经过设计的使用方
Wesley13
•
4年前
2021年最值得学习的10种编程语言
本星球的第一种编程语言要归功于一位英国数学家AugustaAdaByron,他被世人称为AdaLovelace。他发明第一种编程语言,这是一种“汇编”语言,但是,它的解析器未完成。继阿达·洛芙莱斯之后是“Plankalkül”计划。1942年,德国计算机科学家和工程师KonradZuse发明了一种专用于工程的程序语言,它是第一种为计算机设计的高级程序
1
•••
499
500
501
•••
542