推荐
专栏
教程
课程
飞鹅
本次共找到2922条
数据库视图
相关的信息
Wesley13
•
4年前
SQL JOIN 简单介绍
前言本文还是秉持之前一贯的写作风格,以简单易懂的示例帮助大家了解各种join的区别。为什么需要join为什么需要join?join中文意思为连接,连接意味着关联即将一个表和多个表之间关联起来。在处理数据库表的时候,我们经常会发现,需要从多个表中获取信息,将多个表的多个字段数据组装起来再返回给调用者。所以join的前提是这
捉虫大师
•
4年前
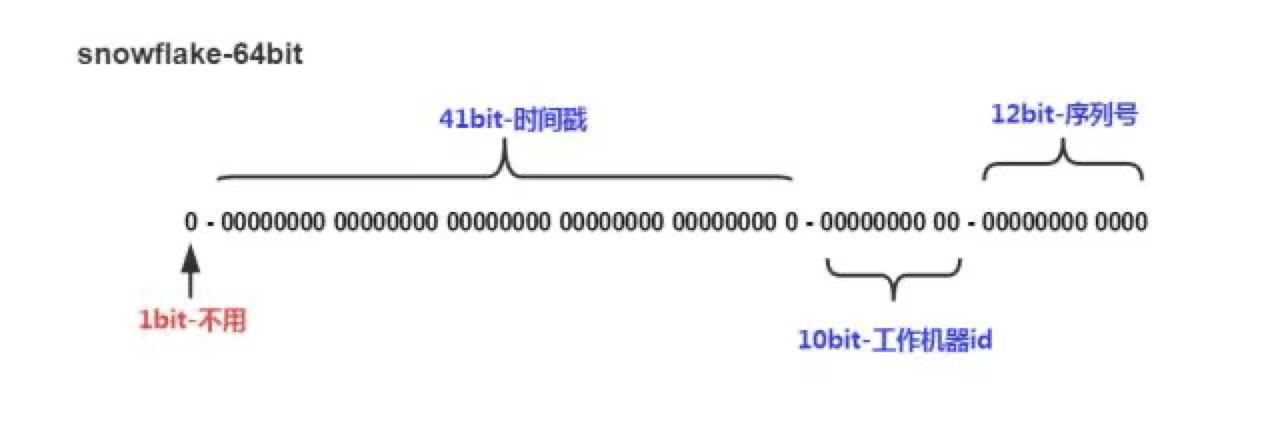
如何设计一款“高可用高性能”的发号器
本文已收录https://github.com/lkxiaolou/lkxiaolou欢迎star。背景在分布式场景中,很多地方需要生成全局唯一的id,如数据库分库分表后需要用唯一id代替单机版本的自增id。发号器的基本要求是全局唯一,无论如何都不能重复某些场景下还要求单调递增,如排序需求等。网上有很多介绍发号器的文章,比如美团的《Leaf——美团点
Stella981
•
4年前
OpenTSDB在HBase中的底层数据结构设计
0.时序数据库时间序列(TimeSeries):是一组按照时间发生先后顺序进行排列的数据点序列,通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,1小时等)。时间序列数据可被简称为时序数据。实时监控系统所收集的监控指标数据,通常就是时序数据。时序数据具有如下特点:每一个时间序列通常为某一固定类型的数值
Wesley13
•
4年前
DDOS防护原理
1.常见DDoS攻击分类DDoS粗略分类为流量型攻击和CC攻击。流量型攻击主要是通过发送报文侵占正常业务带宽,甚至堵塞整个数据中心的出口,导致正常用户访问无法达到业务服务器。CC攻击主要是针对某些业务服务进行频繁访问,重点在于通过精心选择访问的服务,激发大量消耗资源的数据库查询、文件IO等,导致业务服务器CPU、内存或者IO出现瓶颈,无法正常提供服务。比
Stella981
•
4年前
Redis持久化存储详解(一)
为什么要做持久化存储?持久化存储是将Redis存储在内存中的数据存储在硬盘中,实现数据的永久保存。我们都知道Redis是一个基于内存的nosql数据库,内存存储很容易造成数据的丢失,因为当服务器关机等一些异常情况都会导致存储在内存中的数据丢失。持久化存储分类在Redis中,持久化存储分为两种。一种是aof日志追加的方式
Wesley13
•
4年前
17条避坑指南,获赞5K+,这是一份来自谷歌工程师的数据库经验贴
点击关注上方“杰哥的IT之旅”,设为“置顶或星标”,第一时间送达干货。!(https://oscimg.oschina.net/oscnet/dae4bd406f10ef773895e2b8da38cb2bb9a.jpg)作者:JaanaDogan机器之心编译参与:Panda、张倩「ACID
Stella981
•
4年前
CNKI小爬虫(Python)
CNKI作为国文最大的数据库,虽然下载文章是需要登陆的,但是只除了全文外还有很多有价值的信息,包括文章名,作者,基金还有摘要,都可以作为重要数据进行匿名爬取,先写个简单的出来,之后有空再建个关联的数据吧因为闲放在一个文件中太乱所以把他们分开两个文件,一个为主文件Crawl\_cnki.py,一个为参数文件Parameters.py。文件包:https:
子非鱼
•
3年前
Redis高级
第一章Redis的持久化由于redis是一个内存数据库,所有的数据都是保存在内存当中的,内存当中的数据极易丢失,所以redis的数据持久化就显得尤为重要,在redis当中,提供了两种数据持久化的方式,分别为RDB以及AOF,且Redis默认开启的数据持久化方式为RDB方式。1、RDB持久化方案Redis会定期保存数据快照至一个rbd文件中,并在启动时自动
天翼云开发者社区
•
3个月前
通过中国信通院SQL质量管理最高等级评测,天翼云TeleDB引领数据库管理新标准!
近日,天翼云数据管理服务(DMS)顺利通过中国信息通信研究院“SQL质量管理平台分级基础能力检验”专项评测。依据《大数据结构化查询语言(SQL)质量管理平台能力分级要求》标准,在SQL采集、审核、查询优化三大能力域,以及系统兼容性与平台基础能力方面,天翼云
1
•••
282
283
284
•••
293