推荐
专栏
教程
课程
飞鹅
本次共找到4696条
数据库服务器
相关的信息
代码哈士奇
•
4年前
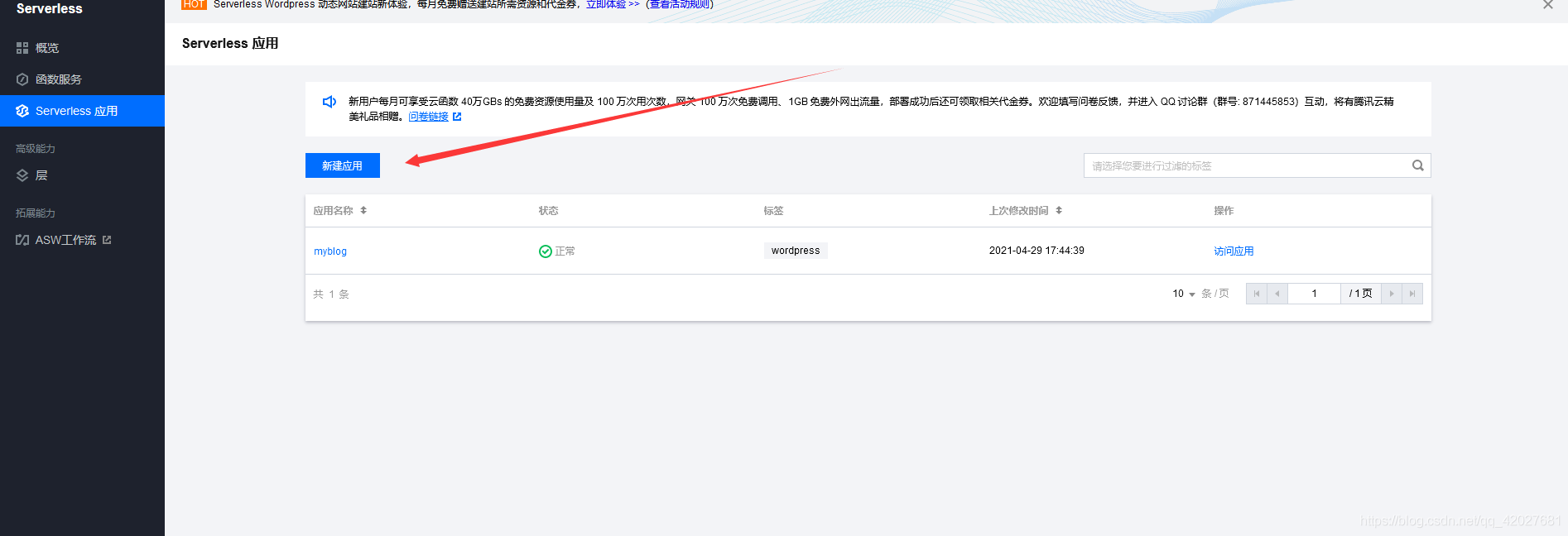
仅需三分钟不懂代码也可完成---使用Serverless快速搭建wordpress博客
不依托服务器可不需要域名便宜,方便100块都没有5块钱总有吧安装部署首先进入腾讯云Serverless地址为创建wordpress模板应用输入名称完成即可等待部署部署完成进入管理访问第一次进入需要安装下面输入的需要根据自己需求输入别学我登录即可此时进入了管理模板我们可以更换主体等等我们访问下主页完成自定义域名如果你没有域
九路
•
5年前
深挖前端 JavaScript 知识点 —— 史上最全面、最详细的 Cookie 总结
1.Cookie产生的背景所有新技术的出现都是为了解决某一痛点。——《前端三昧》我们都知道,HTTP协议是无状态的,服务器无法知道两个请求是否来自同一个浏览器,也不知道用户上一次做了什么,每次请求都是完全相互独立,这严重阻碍了交互式Web应用程序的实现。例子:购物车:在典型的网上购物
Stella981
•
4年前
Linux上传下载
使用Linux系统时一般会借助第三方工具,例如Xshell、SecureCRT等,常常会遇到需要在服务器上与本地机子上做上传下载的文件交互。交互通信有很多协议,下面描述下我常用的Zmodem协议。该协议是针对modem的一种错误校验协议,是Xmodem文件传输协议的一种增强形式,不仅能传输更大的数据,而且错误率更小,并且支持断点
Wesley13
•
4年前
ubuntu18.04里更新系统源和pip源
一、修改ubuntu系统源我的ubuntu系统是在清华的开源网站上下的,所以我还以为他应该就帮我弄好源了,可是没想到下载的还是非常慢,看到下载的时候网址前还有个us,就知道不是国内源了。所以这里我们来换系统源。(ps:我上次用的阿里云服务器好像倒是直接就是阿里的源了,速度还可以。)国内有很多Ubuntu的镜像源,包括阿里的
Wesley13
•
4年前
Java和PHP在Web开发方面的比较
比较PHP和JSP这两个Web开发技术,在目前的情况是其实是比较PHP和Java的Web开发。以下是我就几个主要方面进行的比较:一、语言比较 PHP是解释执行的服务器脚本语言,首先php有简单容易上手的特点。语法和c语言比较象,所以学过c语言的程序员可以很快的熟悉php的开发。而java需要先学好java的语法和熟悉一些核心的
Stella981
•
4年前
24.Mysql高级安装和升级
24.Mysql高级安装和升级24.1Linux/Unix平台下的安装24.1.1安装包比较Linux下的Mysql安装包分为RPM包、二进制包、源码包3种。RPM包优点是安装简单,适合初学者;缺点是默认路径不能修改,服务端和客户端分别安装,一台服务器只能安装一个Mysql。RPM包文件布局:/usr/bin/mysql客户
Wesley13
•
4年前
Java Socket编程——通信是这样炼成的
Java最初是作为网络编程语言出现的,其对网络提供了高度的支持,使得客户端和服务器的沟通变成了现实,而在网络编程中,使用最多的就是Socket。像大家熟悉的QQ、MSN都使用了Socket相关的技术。下面就让我们一起揭开Socket的神秘面纱。Socket编程一、网络基础知识(参考计算机网络)关于计算机网络部分可以参
Stella981
•
4年前
PHP开发web应用安全总结
一、SQL注入攻击(SQLInjection)攻击者把SQL命令插入到Web表单的输入域或页面请求的字符串,欺骗服务器执行恶意的SQL命令。在某些表单中,用户输入的内容直接用来构造(或者影响)动态SQL命令,或作为存储过程的输入参数,这类表单特别容易受到SQL注入式攻击。常见的SQL注入式攻击过程类如:1.某个Web应用有一个登录页面,这
Wesley13
•
4年前
mysql 心跳检测
MySQL服务器所支持的最大连接数是有上限的,因为每个连接的建立都会消耗内存,因此我们希望客户端在连接到MySQLServer处理完相应的操作后,应该断开连接并释放占用的内存。如果你的MySQLServer有大量的闲置连接,他们不仅会白白消耗内存,而且如果连接一直在累加而不断开,最终肯定会达到MySQLServer的连接上限数,这会报'toomany
Wesley13
•
4年前
NIO入门之传统的BIO编程
网络编程的基本模型是Client/Server模型,也就是两个进程之间进行相互通信,其中服务端提供位置信息(绑定的IP地址和监听端口),客户端通过连接操作向服务器监听的地址发起连接请求,通过三次握手建立连接,如果连接建立成功,双方就可以通过网络套接字(Socket)进行通信。在基于传统同步阻塞模型开发中,ServerSocket负责绑定IP地址,启动监听
1
•••
414
415
416
•••
470