推荐
专栏
教程
课程
飞鹅
本次共找到3111条
复杂网络
相关的信息
待兔
•
5年前
理解软件设计的基本原则
任何软件唯一不变的真理是变化,毕竟软件是"软"的。软件研发需要快速响应市场、需求的变化。为了快速响应,我们可以通过增加人手来达到部分目的,但软件开发属于知识密集型工作,当人数增加到一定数量后,不仅不能够提升研发效能。反而增加管理成本,沟通成本及由于人与人沟通、理解上产生的歧义而最终造成软件实现的混乱和复杂度。所以软件本身需要能够轻易的扩展,适应各种需
飞速低代码平台
•
3年前
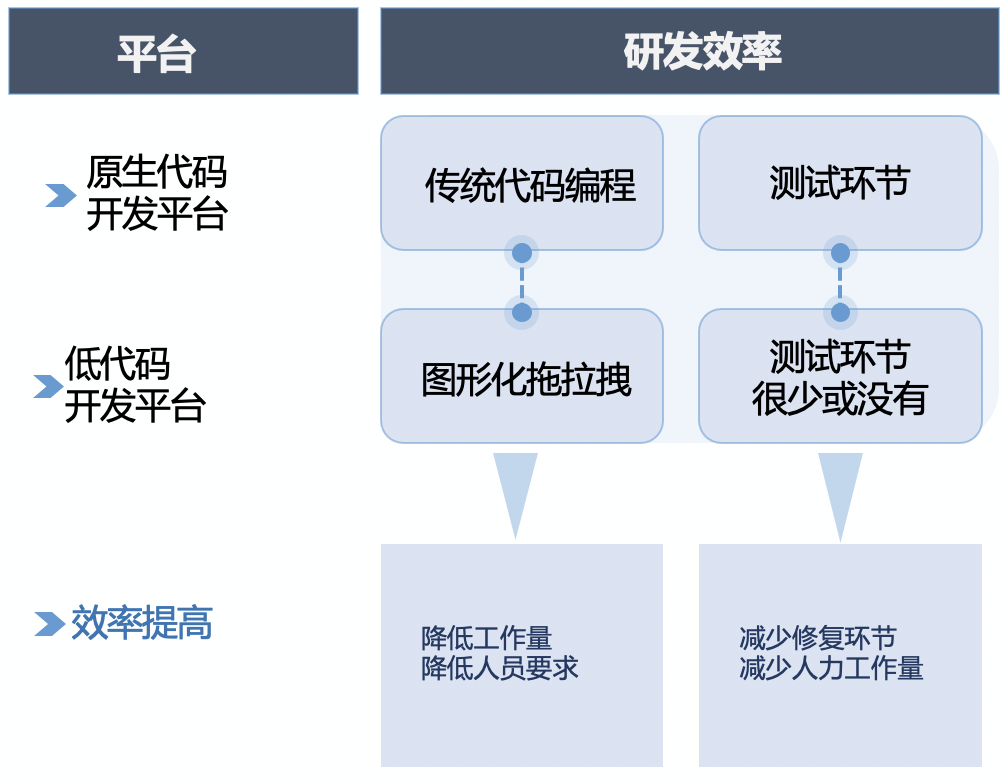
低代码开发平台 | 低代码的衍生历程、优势及未来趋势
通过简单的拖拉拽操作,而不用编写复杂的代码,实现少写代码或者不写代码,就能快速高效完成业务目标。低代码平台演进1.低代码概念低代码是无需编码(0代码)或通过少量代码就可以快速生成应用程序的开发平台。通过可视化进行应用程序开发的方法,具有不同经验水平的开发人员可以通过图形化的用户界面,使用拖拽组件和模型驱动的逻辑来创建网页和移动应用程序。2.低代码衍生历
Irene181
•
4年前
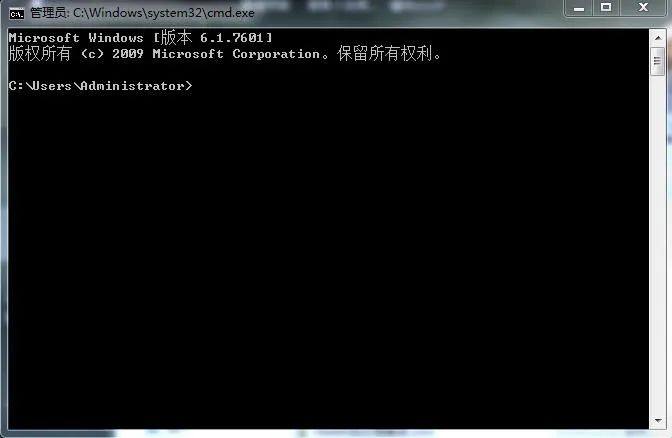
一篇文章带你读懂批处理命令
批处理,顾名思义,批量处理,它可以将复杂的事情变得简单,最早出现在dos操作系统中,也就是我们经常说的cmd黑窗口,这在早期没有gui界面的时候用的是最多的,而且命令比较丰富,虽然现在有很多功能都被封装到了软件中,但是你会发现在dos中执行操作会更快,哪怕会比较麻烦,如果你无法忍受慢节奏。下面就基本命令咱们先看看吧,首先打开cmd窗口:你可以通过快捷键徽
艾木酱
•
4年前
我们与MemFire Cloud的缘起2--MemFireDB
中大概阐述了一下我们之前碰到过的一些应用开发中的痛点:现有的云数据库起步使用成本较高应用开发对团队的起步要求较高现有云数据库配置复杂这些痛点当然不是我们先发现的,也不是我们先要尝试解决的。Google早在2014年就收购了firebase,或许是对这些痛点认可的最佳佐证。就在前两天,InfoQ上发布了一篇翻译文章:,这其实是作者的副标题,原标题是,文章
helloworld_94734536
•
4年前
Application Repository一键启用微信告警通知
前言我们在使用云平台时偶尔会在管理员邮箱中收到系统发出的告警通知,如EC2维护信息,这些邮件很容易淹没在收件箱中,没有得到及时处理。另外对于重要的应用我们可能会在CloudWatch设置一些指标告警并进行邮件通知。如果这些都可以发到微信等即时通信软件,就比邮件通知好多了,毕竟很多人都习惯在即时通信软件上查看消息。具体实现原理并不复杂,我们知道微信等即时通信
Wesley13
•
4年前
DDD领域驱动
DDD领域驱动领域驱动模型。模型驱动代码接触到需求第一步就是考虑领域模型,而不是将其切割成数据和行为,然后数据用数据库实现,行为使用服务实现,最后造成需求的首肢分离。DDD让你首先考虑的是业务语言而不是数据,重点不同导致编程世界观不同。具体的问题,具体解决,以后遇到相同的问题,这个问题就成了领域DDD是解决复杂中大型软件的一套行之有效方式,在
Wesley13
•
4年前
C语言
大家晚上好,最近忙每天忙于项目没有时间更新自己的博客,时间就是海绵嘛硬挤挤就是有的,咂看标题"流程图",编程界的一个不可或缺的技能,特别是在做复杂的逻辑的时候要处理好每一步的关系,在数据中讲就是数据之间的关联关系,或者关联模型等,通俗点也就是父子,母子等关系。首先给大家介绍几款画流程图的软件:亿图图示,VISIO,百度脑图(在线使用),office等
Stella981
•
4年前
Cloud Team:上能修 DB,下能改容器的云原生信仰者 | PingCAP 招聘季
TiDB从诞生之时就带着云原生的标签,并且底层存储引擎TiKV也在2019年成为了CNCF(云原生计算基金会)的孵化项目。我们很早就认识到,云提供的基础设施可编程、按量付费等区别于传统数据中心的核心特质,正是释放TiDB弹性伸缩潜力的最佳载体。而在另一方面,由于有状态应用天生的复杂性和数据资产不可估量的重要性,云原生革命的上半场
Wesley13
•
4年前
0.7秒完成动漫线稿上色,爱奇艺发布AI上色引擎
中国漫画的需求量在不断增加,而动漫制作成本一直居高不下。究其原因为动漫制作是一个复杂且耗时的过程,需要大量工作人员在不同阶段进行协作。动漫制作过程中,需先创作关键帧草图,接着完成中间动作草图,最后在设计的颜色图表基础上反复为所有线条上色。在上色部分,需要大量重复工作,例如画师画好人物风格后,有大量人物形象的相同或相似帧需要上色,而其背
Stella981
•
4年前
Service Mesh 初体验
1前言计算机软件技术发展到现在,软件架构的演进无不朝着让开发者能够更加轻松快捷地构建大型复杂应用的方向发展。容器技术最初是为了解决运行环境的不一致问题而产生的,随着不断地发展,围绕容器技术衍生出来越来越多的新方向。最近几年,云计算领域不断地出现很多新的软件架构模式,其中有一些很热门的概念名词如:云原生
1
•••
234
235
236
•••
312