推荐
专栏
教程
课程
飞鹅
本次共找到480条
合并排序
相关的信息
仲远
•
2年前
PDF Merge PDF Splitter for Mac(PDF合并和拆分软件)
PDFMergePDFSplitterforMac正式版是款针对PDF文件打造的拆分以及合并工具。PDFMergePDFSplitterforMac最新版支持拖放,支持拖动项目进行排,可按字母顺序排序。并且PDFMergePDFSplitterforMac
helloworld_78018081
•
4年前
腾讯T2亲自讲解!Android-App的设计架构经验谈
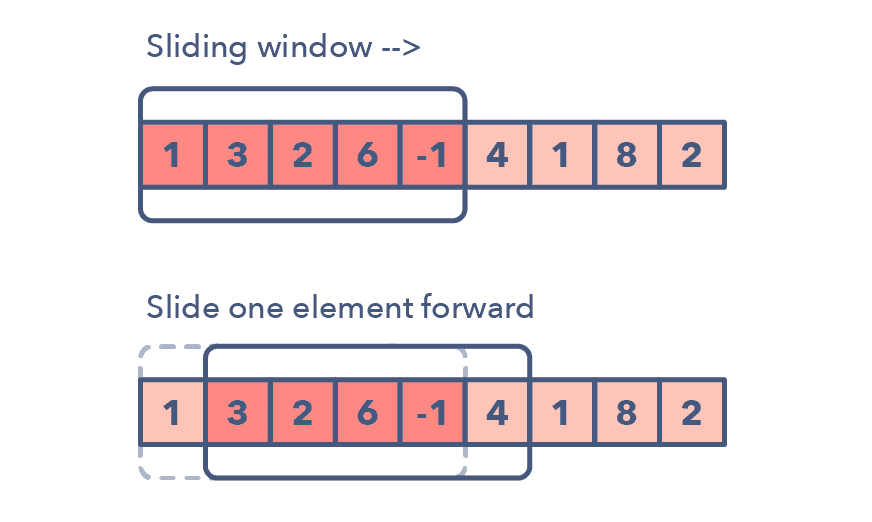
正文我们今天将说明以下14种模式:1.滑动窗口2.二指针或迭代器3.快速和慢速指针或迭代器4.合并区间5.循环排序6.原地反转链表7.树的宽度优先搜索(TreeBFS)8.树的深度优先搜索(TreeDFS)9.TwoHeaps10.子集11.经过修改的二叉搜索12.前K个元素13.K路合并14.拓扑排序我们开始吧!1.滑动窗口滑动窗口模式
Stella981
•
4年前
MapReduce之Shuffle,自定义对象,排序已经Combiner
1\.Shuffle:MapReduce的计算模型主要分为三个阶段,Map,shuffle,Reduce。Map负责数据的过滤,将文件中的数据转化为键值对,Reduce负责合并将具有相同的键的值进行处理合并然后输出到HDFS。为了让Reduce可以并行处理map的结果,必须对Map的输出进行一定的排序和分割,然后交个Red
Stella981
•
4年前
Hadoop学习之路(二十三)MapReduce中的shuffle详解
概述1、MapReduce中,mapper阶段处理的数据如何传递给reducer阶段,是MapReduce框架中最关键的一个流程,这个流程就叫Shuffle2、Shuffle:数据混洗——(核心机制:数据分区,排序,局部聚合,缓存,拉取,再合并排序)3、具体来说:就是将MapTask输出的处理结果数据,按照Par
Easter79
•
4年前
TiDB Binlog 源码阅读系列文章(二)初识 TiDB Binlog 源码
作者:satoruTiDBBinlog架构简介TiDBBinlog主要由Pump和Drainer两部分组成,其中Pump负责存储TiDB产生的binlog并向Drainer提供按时间戳查询和读取binlog的服务,Drainer负责将获取后的binlog合并排序再以合适的格式
Stella981
•
4年前
Halcon区域region的合并,旋转与排序
内容源自:\对目标进行排序\http://www.ihalcon.com/read15537.html(https://www.oschina.net/action/GoToLink?urlhttp%3A%2F%2Fwww.ihalcon.com%2Fread15537.html)重点关注:union1(Selected
Wesley13
•
4年前
PHP二维数据排序,二维数据模糊查询
一、因为项目中的一个报表需要合并三个表的数据,所以分表查询再合并数据,利用PHP数组函数进行排序,搜索。三表合并后的数组结构如下:Array(0Array(history_id12sla_group_
菜园前端
•
2年前
什么是归并排序?
原文链接:什么是归并排序(mergeSort)?主要分成两部分实现,分、合操作:分:把数组分成两半,在递归地对子数组进行"分"操作,直到分成一个个单独的数合:把两个数组合并为有序数组,再对有序数组进行合并,直到全部子数组合并为一个完整数组归并排序就是采用了
京东云开发者
•
2年前
时间复杂度为 O(nlogn) 的排序算法 | 京东物流技术团队
归并排序归并排序遵循分治的思想:将原问题分解为几个规模较小但类似于原问题的子问题,递归地求解这些子问题,然后合并这些子问题的解来建立原问题的解,归并排序的步骤如下:划分:分解待排序的n个元素的序列成各具n/2个元素的两个子序列,将长数组的排序问题转换为短数
京东云开发者
•
2年前
分布式场景怎么Join | 京东云技术团队
背景最近在阅读查询优化器的论文,发现SystemR中对于Join操作的定义一般分为了两种,即嵌套循环、排序合并联接。在原文中,更倾向使用排序合并联接逻辑。考虑到我的领域是在处理分库分表或者其他的分区模式,这让我开始不由得联想我们怎么在分布式场景应用这个Jo
1
2
3
•••
48