推荐
专栏
教程
课程
飞鹅
本次共找到1209条
动态分配内存
相关的信息
灯灯灯灯
•
4年前
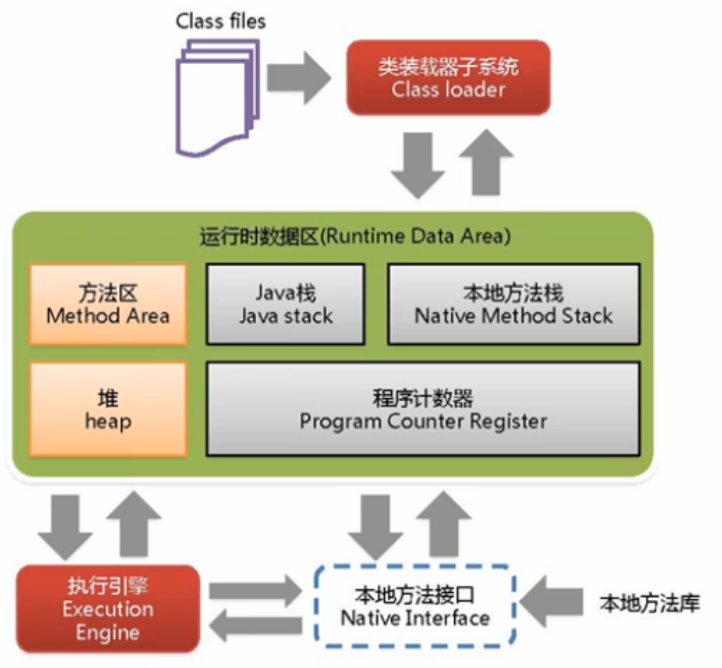
图文详解,史上最全【类加载子系统】解说!!
内存结构概述简图详细图英文版中文版注意:方法区只有HotSpot虚拟机有,J9,JRockit都没有如果自己想手写一个Java虚拟机的话,主要考虑哪些结构呢?1.类加载器2.执行引擎类加载器子系统类加载器子系统作用:1.类加载器子系统负责从文件系统或者网络中加载Class文件,class文件在文件开头有特定的文件标识。2.ClassLo
个推技术实践
•
4年前
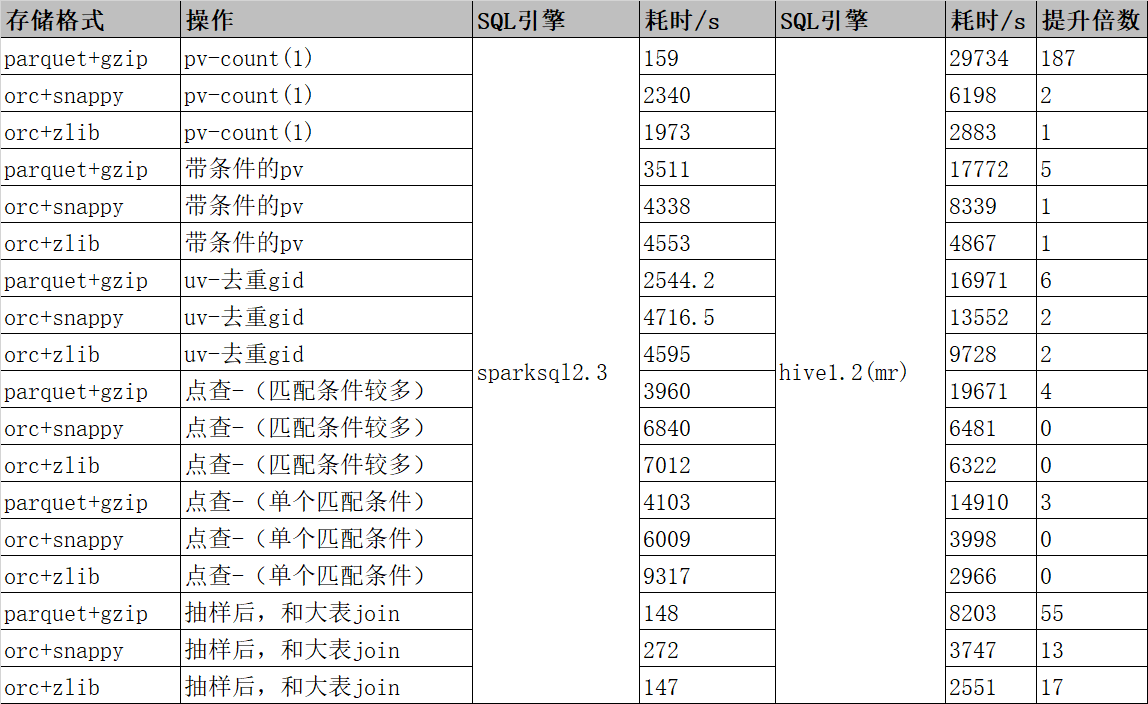
个推分享Spark性能调优指南:性能提升60%↑ 成本降低50%↓
前言Spark是目前主流的大数据计算引擎,功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计算操作,应用范围与前景非常广泛。作为一种内存计算框架,Spark运算速度快,并能够满足UDF、大小表Join、多路输出等多样化的数据计算和处理需求。作为国内专业的数据智能服务商,个推从早期的1.3版本便引入Spark,
Stella981
•
4年前
Redis之父表示ARM服务器没戏!
ARM表示NeoverseN1平台和E1CPU即将发布,NeoverseN1和E1采用7nm制程,并且为服务器和通信设备增加重要提升,拥有高可扩展性、高处理量以及高性能,将分别在2020年和2021年投入使用。与CortexA72内核相比,N1分别将Java和memcacheD性能提高了1.7倍和2.5倍。与A72相比,N1内存延迟从110ns
Stella981
•
4年前
JVM笔记九
在上一篇文章中,我们通过代码运行结果,查看到JVM的堆内存逻辑上分区是三部分,物理上分区是2部分,以及是新生代分区三部分,占比分布是8/1/1。而且我们还通过代码和堆JVM参数配置,制造出了OOM异常。下面我们就来分析GC回收器的日志信息。先来看看,OOM后,GC详细日志信息:!dd604a3c4cda17304edcc43b03106d58.pn
Wesley13
•
4年前
Jade模板引擎入门教程
Jade是一款高性能简洁易懂的模板引擎,Jade是Haml的Javascript实现,在服务端(NodeJS)及客户端均有支持。功能客户端支持超强的可读性灵活易用的缩进块扩展代码默认经过编码处理以增强安全性编译及运行时的上下文错误报告命令行编译支持HTML5模式(使用!!!5文档类型)可选的内存缓存联合动态和静态标记类利用过滤器解析树
Wesley13
•
4年前
Java面试官最常问的volatile关键字
在Java相关的职位面试中,很多Java面试官都喜欢考察应聘者对Java并发的了解程度,以volatile关键字为切入点,往往会问到底,Java内存模型(JMM)和Java并发编程的一些特点都会被牵扯出来,再深入的话还会考察JVM底层实现以及操作系统的相关知识。接下来让我们在一个假想的面试过程中来学习一下volitile关键字吧。1\.Java并发
Wesley13
•
4年前
DDOS防护原理
1.常见DDoS攻击分类DDoS粗略分类为流量型攻击和CC攻击。流量型攻击主要是通过发送报文侵占正常业务带宽,甚至堵塞整个数据中心的出口,导致正常用户访问无法达到业务服务器。CC攻击主要是针对某些业务服务进行频繁访问,重点在于通过精心选择访问的服务,激发大量消耗资源的数据库查询、文件IO等,导致业务服务器CPU、内存或者IO出现瓶颈,无法正常提供服务。比
Stella981
•
4年前
Redis中的Scan命令踩坑记
1原本以为自己对redis命令还蛮熟悉的,各种数据模型各种基于redis的骚操作。但是最近在使用redis的scan的命令式却踩了一个坑,顿时发觉自己原来对redis的游标理解的很有限。所以记录下这个踩坑的过程,背景如下:公司因为redis服务器内存吃紧,需要删除一些无用的没有设置过期时间的key。大概有500多w的key。虽然key的数目听起来
Stella981
•
4年前
JVM类加载
运行时数据区java虚拟机定义了若干种程序运行时使用到的运行时数据区1.有一些是随虚拟机的启动而创建,随虚拟机的退出而销毁2.第二种则是与线程一一对应,随线程的开始和结束而创建和销毁。java虚拟机所管理的内存将会包括以下几个运行时数据区域!(http://static.oschina.net/uplo
Easter79
•
4年前
TODO:Windows10的使用感想及兼容Linux
TODO:Windows10的使用感想及兼容Linux这段时间一直使用了Windows10,介绍一下本机配置,双核CPU,8G内存,C盘100G。把不必要的软件卸载掉之后,Windows10给小O的感觉是win7win8的结合体,总体使用还算流畅。适合开发者使用。左下角的win键,弹出的内容个人有些花俏,也许是考虑到手机版和触屏版的体验,如果你习惯
1
•••
114
115
116
•••
121