推荐
专栏
教程
课程
飞鹅
本次共找到1577条
分布式缓存
相关的信息
peter
•
4年前
Go:分布式锁实现原理与最佳实践
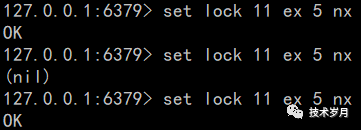
分布式锁应用场景很多应用场景是需要系统保证幂等性的(如api服务或消息消费者),并发情况下或消息重复很容易造成系统重入,那么分布式锁是保障幂等的一个重要手段。另一方面,很多抢单场景或者叫交易撮合场景,如dd司机抢单或唯一商品抢拍等都需要用一把“全局锁”来解决并发造成的问题。在防止并发情况下造成库存超卖的场景,也常用分布式锁来解决。实现
Stella981
•
4年前
Python远程方法调用 RPyC
rpyc(RemotePythonCall)为分布式计算环境提供了优良的基础平台。使用rpyc编写c/s结构程序,完全不用考虑老式的socket编程,现在只用编写简单的3、5行代码即可完成以前的数千行代码的功能。RemotePythonCall(RPyC)是一个Python的库用来实现RPC和分布式计算的工具。支持同步和异步操作、
Stella981
•
4年前
Raft协议
在很多分布式系统场景下,并不需要解决拜占庭将军问题(https://www.oschina.net/action/GoToLink?urlhttp%3A%2F%2Fwww.868qkl.com%2Fjiaocheng%2Fmingci%2FByzantinefailures.html),也就是说,在这些分布式系统的实用场景下,其假设条件不需要考虑拜占
Easter79
•
4年前
TransmittableThreadLocal在使用线程池等会缓存线程的组件情况下传递ThreadLocal
1、简介TransmittableThreadLocal是Alibaba开源的、用于解决“在使用线程池等会缓存线程的组件情况下传递ThreadLocal”问题的InheritableThreadLocal扩展。若希望TransmittableThreadLocal在线程池与主线程间传递,需配合_TtlRunnab
Stella981
•
4年前
Gradle使用杂记
1、配置环境变量GRADLE\_HOME2、把gradle缓存目录指向了gradle安装目录下的.gradle目录,设置环境变量GRADLE\_USER\_HOMEGRADLE\_USER\_HOME%GRADLE\_HOME%\\.gradle或者指定目录GRADLE\_USER\_HOMED:\\gradle\\.grad
Wesley13
•
4年前
ubuntu18.04.2 hadoop3.1.2+zookeeper3.5.5高可用完全分布式集群搭建
ubuntu18.04.2hadoop3.1.2zookeeper3.5.5高可用完全分布式集群搭建集群规划:hostnameNameNodeDataNodeJournalNodeResourceManagerZookeepernode01√√√node02√√node03√√
Wesley13
•
4年前
CEPH总结
ceph简介Ceph是一个分布式存储系统,诞生于2004年,是最早致力于开发下一代高性能分布式文件系统的项目。随着云计算的发展,ceph乘上了OpenStack的春风,进而成为了开源社区受关注较高的项目之一。ceph基本结构!(http://uploadimages.jianshu.io/upload_images/4
Stella981
•
4年前
Eureka与Zookeeper的区别
作为服务注册中心,Eureka比Zookeeper好在哪里著名的CAP理论指出,一个分布式系统不可能同时满足C(一致性)、A(可用性)和P(分区容错性)。由于分区容错性P是在分布式系统中必须要保证的,因此我们只能在A和C之间进行权衡。因此Zookeeper保证的是CPEureka则
Wesley13
•
4年前
MAPREDUCER学习笔记
MAPREDUCE基本原理 一,概念理解 1,Mapreduce是一个分布式运算程序的编程架构,相对于HDFS来说就是客户端。其核心功能就是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并运行在一个hadoop集群上。 2,基本整体架构:MEAppMaster,MapTask,R
天翼云开发者社区
•
3年前
这个算法不一般,控制拥塞有一手!
数字时代下,远程办公、线上协同成为刚需,直播带货等业务模式盛行,数据流量爆炸式增长,低时延、高流畅的网络传输诉求给数据中心的处理能力带来了极大挑战。RDMA作为一种新型网络传输技术,可大幅提升网络传输实效,帮助网络IO密集的业务(比如分布式存储、分布式数据
1
•••
48
49
50
•••
158