

作者:小傅哥 博客:https://bugstack.cn
沉淀、分享、成长,让自己和他人都能有所收获!😄
作者:小傅哥 博客:https://bugstack.cn
沉淀、分享、成长,让自己和他人都能有所收获!😄
一、前言
算法是数据结构的灵魂!
好的算法搭配上合适的数据结构,可以让代码功能大大的提升效率。当然,算法学习不只是刷题,还需要落地与应用,否则到了写代码的时候,还是会for循环+ifelse。
当开发一个稍微复杂点的业务流程时,往往要用到与之契合的数据结构和算法逻辑,在与设计模式结合,这样既能让你的写出具有高性能的代码,也能让这些代码具备良好的扩展性。
在以往的章节中,我们把Java常用的数据结构基本介绍完了,都已收录到:跳转 -> 《面经手册》,章节内容下图;

那么,有了这些数据结构的基础,接下来我们再学习一下Java中提供的算法工具类,Collections。
二、面试题
谢飞机,今天怎么无精打采的呢,还有黑眼圈?
答:好多知识盲区呀,最近一直在努力补短板,还有面经手册里的数据结构。
问:那数据结构看的差不多了吧,你有考虑🤔过,数据结构里涉及的排序、二分查找吗?
答:二分查找会一些,巴拉巴拉。
问:还不错,那你知道这个方法在Java中有提供对应的工具类吗?是哪个!
答:这!?好像没注意过,没用过!
问:去吧,回家在看看书,这两天也休息下。
飞机悄然的出门了,但这次面试题整体回答的还是不错的,面试官决定下次再给他一个机会。
三、Collections 工具类
java.util.Collections,是java集合框架的一个工具类,主要用于Collection提供的通用算法;排序、二分查找、洗牌等算法操作。
从数据结构到具体实现,再到算法,整体的结构如下图;

1. Collections.sort 排序
1.1 初始化集合
List<String> list = new ArrayList<String>();
list.add("7");
list.add("4");
list.add("8");
list.add("3");
list.add("9");1.2 默认排列[正序]
Collections.sort(list);
// 测试结果:[3, 4, 7, 8, 9]1.3 Comparator排序
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.compareTo(o1);
}
});- 我们使用
o2与o1做对比,这样会出来一个倒叙排序。 - 同时,
Comparator还可以对对象类按照某个字段进行排序。 - 测试结果如下;
[9, 8, 7, 4, 3]1.4 reverseOrder倒排
Collections.sort(list, Collections.<String>reverseOrder());
// 测试结果:[9, 8, 7, 4, 3]Collections.<String>reverseOrder()的源码部分就和我们上面把两个对比的类调换过来一样。c2.compareTo(c1);
1.5 源码简述
关于排序方面的知识点并不少,而且有点复杂。本文主要介绍 Collections 集合工具类,后续再深入每一个排序算法进行讲解。
Collections.sort
集合排序,最终使用的方法:Arrays.sort((E[]) elementData, 0, size, c);
public static <T> void sort(T[] a, int fromIndex, int toIndex,
Comparator<? super T> c) {
if (c == null) {
sort(a, fromIndex, toIndex);
} else {
rangeCheck(a.length, fromIndex, toIndex);
if (LegacyMergeSort.userRequested)
legacyMergeSort(a, fromIndex, toIndex, c);
else
TimSort.sort(a, fromIndex, toIndex, c, null, 0, 0);
}
}- 这一部分排序逻辑包括了,旧版的归并排序
legacyMergeSort和TimSort排序。 - 但因为开关的作用,
LegacyMergeSort.userRequested = false,基本都是走到TimSort排序 。 - 同时在排序的过程中还会因为元素的个数是否大于
32,而选择分段排序和二分插入排序。这一部分内容我们后续专门在排序内容讲解
2. Collections.binarySearch 二分查找
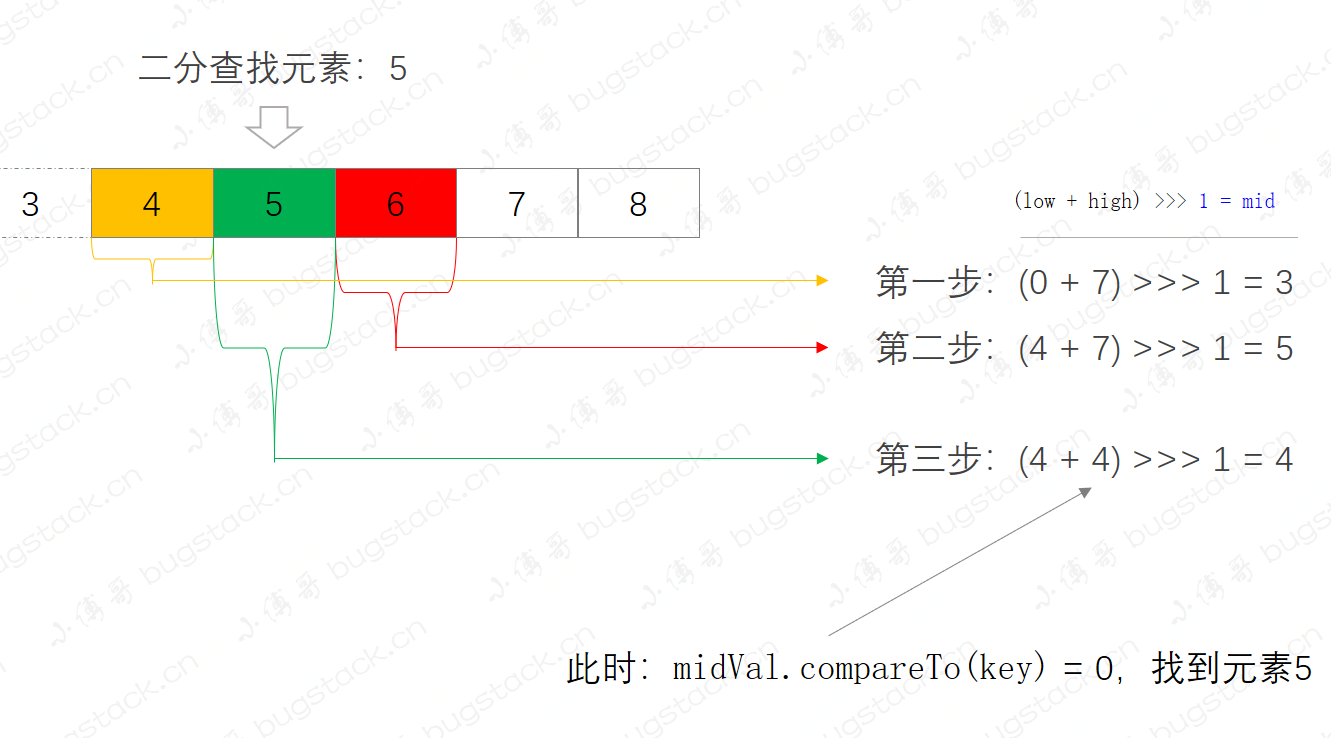
- 看到这张图熟悉吗,这就是集合元素中通过二分查找定位指定元素5。
- 二分查找的前提是集合有序,否则不能满足二分算法的查找过程。
- 查找集合元素5,在这个集合中分了三部;
- 第一步,
(0 + 7) >>> 1 = 3,定位list.get(3) = 4,则继续向右侧二分查找。 - 第二步,
(4 + 7) >>> 1 = 5,定位list.get(5) = 6,则继续向左侧二分查找。 - 第三步,
(4 + 4) >>> 1 = 4,定位list.get(4) = 5,找到元素,返回结果。
- 第一步,
2.1 功能使用
@Test
public void test_binarySearch() {
List<String> list = new ArrayList<String>();
list.add("1");
list.add("2");
list.add("3");
list.add("4");
list.add("5");
list.add("6");
list.add("7");
list.add("8");
int idx = Collections.binarySearch(list, "5");
System.out.println("二分查找:" + idx);
}- 此功能就是上图中的具体实现效果,通过
Collections.binarySearch定位元素。 - 测试结果:
二分查找:4
2.2 源码分析
Collections.binarySearch
public static <T> int binarySearch(List<? extends Comparable<? super T>> list, T key) {
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
return Collections.indexedBinarySearch(list, key);
else
return Collections.iteratorBinarySearch(list, key);
}这段二分查找的代码还是蛮有意思的,list instanceof RandomAccess 这是为什么呢?因为 ArrayList 有实现 RandomAccess,但是 LinkedList 并没有实现这个接口。同时还有元素数量阈值的校验 BINARYSEARCH_THRESHOLD = 5000,小于这个范围的都采用 indexedBinarySearch 进行查找。那么这里其实使用 LinkedList 存储数据,在元素定位的时候,需要get循环获取元素,就会比 ArrayList 更耗时。
Collections.indexedBinarySearch(list, key):
private static <T> int indexedBinarySearch(List<? extends Comparable<? super T>> list, T key) {
int low = 0;
int high = list.size()-1;
while (low <= high) {
int mid = (low + high) >>> 1;
Comparable<? super T> midVal = list.get(mid);
int cmp = midVal.compareTo(key);
if (cmp < 0)
low = mid + 1;
else if (cmp > 0)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found
}以上这段代码就是通过每次折半二分定位元素,而上面所说的耗时点就是list.get(mid),这在我们分析数据结构时已经讲过。《LinkedList插入速度比ArrayList快?你确定吗?》
Collections.iteratorBinarySearch(list, key):
private static <T> int iteratorBinarySearch(List<? extends Comparable<? super T>> list, T key)
{
int low = 0;
int high = list.size()-1;
ListIterator<? extends Comparable<? super T>> i = list.listIterator();
while (low <= high) {
int mid = (low + high) >>> 1;
Comparable<? super T> midVal = get(i, mid);
int cmp = midVal.compareTo(key);
if (cmp < 0)
low = mid + 1;
else if (cmp > 0)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found
}上面这段代码是元素数量大于5000个,同时是 LinkedList 时会使用迭代器 list.listIterator 的方式进行二分查找操作。也算是一个优化,但是对于链表的数据结构,仍然没有数组数据结构,二分处理的速度快,主要在获取元素的时间复杂度上O(1) 和 O(n)。
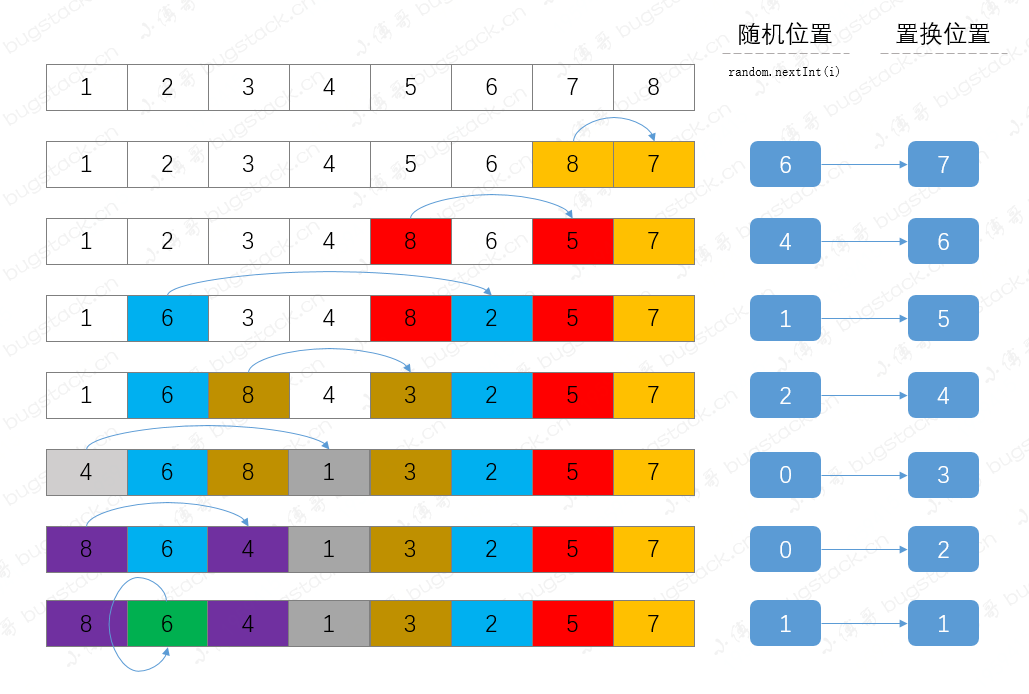
3. Collections.shuffle 洗牌算法
洗牌算法,其实就是将 List 集合中的元素进行打乱,一般可以用在抽奖、摇号、洗牌等各个场景中。
3.1 功能使用
Collections.shuffle(list);
Collections.shuffle(list, new Random(100));它的使用方式非常简单,主要有这么两种方式,一种直接传入集合、另外一种还可以传入固定的随机种子这种方式可以控制洗牌范围范围
3.2 源码分析
按照洗牌的逻辑,我们来实现下具体的核心逻辑代码,如下;
@Test
public void test_shuffle() {
List<String> list = new ArrayList<String>();
list.add("1");
list.add("2");
list.add("3");
list.add("4");
list.add("5");
list.add("6");
list.add("7");
list.add("8");
Random random = new Random();
for (int i = list.size(); i > 1; i--) {
int ri = random.nextInt(i); // 随机位置
int ji = i - 1; // 顺延
System.out.println("ri:" + ri + " ji:" + ji);
list.set(ji, list.set(ri, list.get(ji))); // 元素置换
}
System.out.println(list);
}运行结果:
ri:6 ji:7
ri:4 ji:6
ri:1 ji:5
ri:2 ji:4
ri:0 ji:3
ri:0 ji:2
ri:1 ji:1
[8, 6, 4, 1, 3, 2, 5, 7]这部分代码逻辑主要是通过随机数从逐步缩小范围的集合中找到对应的元素,与递减的下标位置进行元素替换,整体的执行过程如下;
4. Collections.rotate 旋转算法
旋转算法,可以把ArrayList或者Linkedlist,从指定的某个位置开始,进行正旋或者逆旋操作。有点像把集合理解成圆盘,把要的元素转到自己这,其他的元素顺序跟随。
4.1 功能应用
List<String> list = new ArrayList<String>();
list.add("7");
list.add("4");
list.add("8");
list.add("3");
list.add("9");
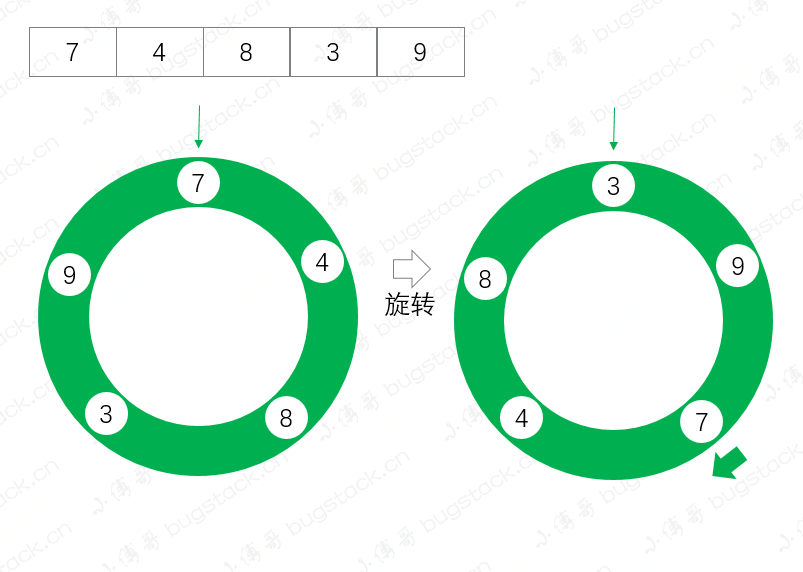
Collections.rotate(list, 2);
System.out.println(list);这里我们将集合顺序;7、4、8、3、9,顺时针旋转2位,测试结果如下;逆时针旋转为负数
测试结果
[3, 9, 7, 4, 8]通过测试结果我们可以看到,从元素7开始,正向旋转了两位,执行效果如下图;
4.2 源码分析
public static void rotate(List<?> list, int distance) {
if (list instanceof RandomAccess || list.size() < ROTATE_THRESHOLD)
rotate1(list, distance);
else
rotate2(list, distance);
}关于旋转算法的实现类分为两部分;
- Arraylist 或者元素数量不多时,
ROTATE_THRESHOLD = 100,则通过算法rotate1实现。 - 如果是 LinkedList 元素数量又超过了 ROTATE_THRESHOLD,则需要使用算法
rotate2实现。
那么,这两个算法有什么不同呢?
4.2.1 旋转算法,rotate1
private static <T> void rotate1(List<T> list, int distance) {
int size = list.size();
if (size == 0)
return;
distance = distance % size;
if (distance < 0)
distance += size;
if (distance == 0)
return;
for (int cycleStart = 0, nMoved = 0; nMoved != size; cycleStart++) {
T displaced = list.get(cycleStart);
int i = cycleStart;
do {
i += distance;
if (i >= size)
i -= size;
displaced = list.set(i, displaced);
nMoved ++;
} while (i != cycleStart);
}
}这部分代码看着稍微多一点,但是数组结构的操作起来并不复杂,基本如上面圆圈图操作,主要包括以下步骤;
distance = distance % size;,获取旋转的位置。- for循环和dowhile,配合每次的旋转操作,比如这里第一次会把0位置元素替换到2位置,接着在dowhile中会判断
i != cycleStart,满足条件继续把替换了2位置的元素继续往下替换。直到一轮循环把所有元素都放置到正确位置。 - 最终list元素被循环替换完成,也就相当从某个位置开始,正序旋转2个位置的操作。
4.2.2 旋转算法,rotate2
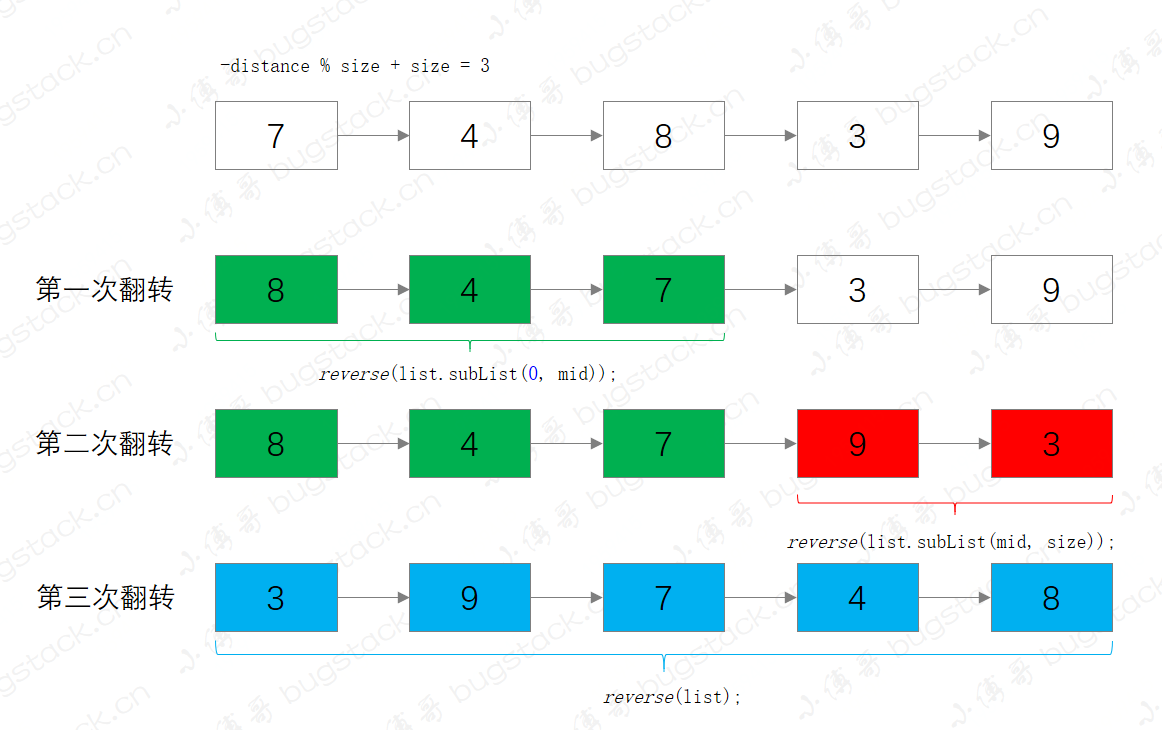
private static void rotate2(List<?> list, int distance) {
int size = list.size();
if (size == 0)
return;
int mid = -distance % size;
if (mid < 0)
mid += size;
if (mid == 0)
return;
reverse(list.subList(0, mid));
reverse(list.subList(mid, size));
reverse(list);
}接下来这部分源码主要是针对大于100个元素的LinkedList进行操作,所以整个算法也更加有意思,它的主要操作包括;
- 定位拆链位置,-distance % size + size,也就是我们要旋转后找到的元素位置
- 第一次翻转,把从位置0到拆链位置
- 第二次翻转,把拆链位置到结尾
- 第三次翻转,翻转整个链表
整体执行过程,可以参考下图,更方便理解;
5. 其他API介绍
这部分API内容,使用和设计上相对比较简单,平时可能用的时候不多,但有的小伙伴还没用过,就当为你扫盲了。
5.1 最大最小值
String min = Collections.min(Arrays.asList("1", "2", "3"));
String max = Collections.max(Arrays.asList("1", "2", "3"));Collections工具包可以进行最值的获取。
5.2 元素替换
List<String> list = new ArrayList<String>();
list.add("7");
list.add("4");
list.add("8");
list.add("8");
Collections.replaceAll(list, "8", "9");
// 测试结果: [7, 4, 9, 9]- 可以把集合中某个元素全部替换成新的元素。
5.3 连续集合位置判断
@Test
public void test_indexOfSubList() {
List<String> list = new ArrayList<String>();
list.add("7");
list.add("4");
list.add("8");
list.add("3");
list.add("9");
int idx = Collections.indexOfSubList(list, Arrays.asList("8", "3"));
System.out.println(idx);
// 测试结果:2
}在使用String操作中,我们知道"74839".indexOf("8");,可以获取某个元素在什么位置。而在ArrayList集合操作中,可以获取连续的元素,在集合中的位置。
5.4 synchronized
List<String> list = Collections.synchronizedList(new ArrayList<String>());
Map<String, String> map = Collections.synchronizedMap(new HashMap<String, String>());- 这个很熟悉吧,甚至经常使用,但可能会忽略这些线程安全的方法来自于
Collections集合工具包。
四、总结
- 本章节基本将
java.util.Collections工具包中的常用方法介绍完了,以及一些算法的讲解。这样在后续需要使用到这些算法逻辑时,就可以直接使用并不需要重复造轮子。 - 学习数据结构、算法、设计模式,这三方面的知识,重点还是能落地到日常的业务开发中,否则空、假、虚,只能适合吹吹牛,并不会给项目研发带来实际的价值。
- 懂了就是真的懂,别让自己太难受。死记硬背谁也受不了,耗费了大量的时间,知识也没有吸收,学习一个知识点最好就从根本学习,不要心浮气躁。
五、系列推荐
一、前言
买房子最重要的是房屋格局!
如果买房子能接受地理位置、平米价格外,最重要的就是房屋格局。什么?丈母娘!你🤦🏻♂,出去! 房屋的格局其实对应的就是程序开发的根本,也就是数据结构。有的土豪可以用钱换空间,房间格局更大,那没钱的就只能选经济小空间节省钱。是不是很像不同的数据结构,直接影响着是空间换时间,还是时间换空间。那么,再细看房间,如;客厅沙发坐人像散列表、去厨房🥣叫进栈「LIFO」、上厕所🚽叫入队列「FIFO」、晚上各回各屋子像进数组。所以你能在这个屋子生活的舒服,很大一部分取决于整个房间的布局。也同样你能把程序写好,很大的原因是因为数据结构定义的合理。
那么决定这程序开发基础数据结构有哪些呢?
程序开发中数据结构可以分为这八类;数组、链表、栈、队列、散列表、树、堆、图。其中,数组、链表、散列表、树是程序开发直接或者间接用到的最多的。相关的对应实现类可以包括如下;
| 类型 | 实现 | 文章 |
|---|---|---|
| 数组 | ArrayList | ArrayList也这么多知识?一个指定位置插入就把谢飞机面晕了! |
| 链表 | LinkedList | LinkedList插入速度比ArrayList快?你确定吗? |
| 树 | 2-3树、红黑树 | 看图说话,讲解2-3平衡树「红黑树的前身」 红黑树操作原理,解析什么时候染色、怎么进行旋转、与2-3树有什么关联 |
| 散列表 | HashMap | HashMap核心知识,扰动函数、负载因子、扩容链表拆分,深度学习 HashMap数据插入、查找、删除、遍历,源码分析 |
| 栈 | Stack |
|
| 队列 | Queue |
- 如上,除了栈和队列外,小傅哥已经编写了非常细致的文章来介绍了其他数据结构的核心知识和具体的实现应用。
- 接下来就把剩下的栈和队列在本章介绍完,其实这部分知识并不难了,有了以上对数组和链表的理解,其他的数据结构基本都从这两方面扩展出来的。
本文涉及了较多的代码和实践验证图稿,欢迎关注公众号:bugstack虫洞栈,回复下载得到一个链接打开后,找到ID:19🤫获取!
二、面试题
谢飞机,飞机你旁边这是?
答:啊,谢坦克,我弟弟。还没毕业,想来看看大公司面试官的容颜。
问:飞机,上次把LinkedList都看了吧,那我问你哈。LinkedList可以当队列用吗?
答:啊?可以,可以吧!
问:那,数组能当队列用吗?不能?对列有啥特点吗?
答:队列先进先出,嗯,嗯。
问:还有吗?了解延时队列吗?双端队列呢?
飞机拉着坦克的手出门了,还带走了面试官送的一本《面经手册》,坦克对飞机说,基础不牢,地动山摇,我要好好学习。
三、数据结构
把我们已经掌握了的数组和链表立起来,就是栈和队列了!
如图,这一章节的数据结构的知识点并不难,只要已经学习过数组和链表,那么对于掌握其他数据结构就已经有了基础,只不过对于数据的存放、读取加了一些限定规则。尤其像链表这样的数据结构,只操作头尾的效率是非常高的。
四、源码学习
1. 先说一个被抛弃Stack
有时候不会反而不会犯错误!怕就怕在只知道一知半解。
抛弃的不是栈这种数据结构,而是Stack实现类,如果你还不了解就用到业务开发中,就很可能会影响系统性能。其实Stack这个栈已经是不建议使用了,但是为什么不建议使用,我们可以通过使用和源码分析了解下根本原因。
在学习之前先大概的了解下这样的数据结构,它很像羽毛球的摆放,是一种后进先出队列,如下;
1.1 功能使用
@Test
public void test_stack() {
Stack<String> s = new Stack<String>();
s.push("aaa");
s.push("bbb");
s.push("ccc");
System.out.println("获取最后一个元素:" + s.peek());
System.out.println("获取最后一个元素:" + s.lastElement());
System.out.println("获取最先放置元素:" + s.firstElement());
System.out.println("弹出一个元素[LIFO]:" + s.pop());
System.out.println("弹出一个元素[LIFO]:" + s.pop());
System.out.println("弹出一个元素[LIFO]:" + s.pop());
}例子是对Stack栈的使用,如果不运行你能知道它的输出结果吗?
测试结果:
获取最后一个元素:ccc
获取最后一个元素:ccc
获取最先放置元素:aaa
弹出一个元素[LIFO]:ccc
弹出一个元素[LIFO]:bbb
弹出一个元素[LIFO]:aaa
Process finished with exit code 0看到测试结果,与你想的答案是否一致?
- peek,是偷看的意思,就是看一下,不会弹出元素。满足后进先出的规则,它看的是最后放进去的元素
ccc。 - lastElement、firstElement,字面意思的方法,获取最后一个和获取第一个元素。
- pop,是队列中弹出元素,弹出后也代表着要把属于这个位置都元素清空,删掉。
1.2 源码分析
我们说Stack栈,这个实现类已经不推荐使用了,需要从它的源码上看。
/**
*
* <p>A more complete and consistent set of LIFO stack operations is
* provided by the {@link Deque} interface and its implementations, which
* should be used in preference to this class. For example:
* <pre> {@code
* Deque<Integer> stack = new ArrayDeque<Integer>();}</pre>
*
* @author Jonathan Payne
* @since JDK1.0
*/
public class Stack<E> extends Vector<E> s.push("aaa");
public synchronized void addElement(E obj) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = obj;
}Stack栈是在JDK1.0时代时,基于继承Vector,实现的。本身Vector就是一个不推荐使用的类,主要在于它的一些操作方法锁🔒(synchronized)的力度太粗,都是放到方法上。Stack栈底层是使用Vector数组实现,在学习ArrayList时候我们知道,数组结构在元素添加和擅长需要通过System.arraycopy,进行扩容操作。而本身栈的特点是首尾元素的操作,也不需要遍历,使用数组结构其实并不太理想。- 同时在这个方法的注释上也明确标出来,推荐使用
Deque<Integer> stack = new ArrayDeque<Integer>();,虽然这也是数组结构,但是它没有粗粒度的锁,同时可以申请指定空间并且在扩容时操作时也要优于Stack。并且它还是一个双端队列,使用起来更灵活。
2. 双端队列ArrayDeque
ArrayDeque 是基于数组实现的可动态扩容的双端队列,也就是说你可以在队列的头和尾同时插入和弹出元素。当元素数量超过数组初始化长度时,则需要扩容和迁移数据。
数据结构和操作,如下;
从上图我们可以了解到如下几个知识点;
- 双端队列是基于数组实现,所以扩容迁移数据操作。
push,像结尾插入、offerLast,向头部插入,这样两端都满足后进先出。- 整体来看,双端队列,就是一个环形。所以扩容后继续插入元素也满足后进先出。
2.1 功能使用
@Test
public void test_ArrayDeque() {
Deque<String> deque = new ArrayDeque<String>(1);
deque.push("a");
deque.push("b");
deque.push("c");
deque.push("d");
deque.offerLast("e");
deque.offerLast("f");
deque.offerLast("g");
deque.offerLast("h"); // 这时候扩容了
deque.push("i");
deque.offerLast("j");
System.out.println("数据出栈:");
while (!deque.isEmpty()) {
System.out.print(deque.pop() + " ");
}
}以上这部分代码就是与上图的展现是一致的,按照图中的分析我们看下输出结果,如下;
数据出栈:
i d c b a e f g h j
Process finished with exit code 0i d c b a e f g h j,正好满足了我们的说的数据出栈顺序。可以参考上图再进行理解
2.2 源码分析
ArrayDeque 这种双端队列是基于数组实现的,所以源码上从初始化到数据入栈扩容,都会有数组操作的痕迹。接下来我们就依次分析下。
2.2.1 初始化
new ArrayDeque<String>(1);,其实它的构造函数初始化默认也提供了几个方法,比如你可以指定大小以及提供默认元素。
private static int calculateSize(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
// Find the best power of two to hold elements.
// Tests "<=" because arrays aren't kept full.
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0) // Too many elements, must back off
initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 element
}
return initialCapacity;
}- 在初始化的过程中,它需要找到你当前传输值最小的2的倍数的一个容量。这与HashMap的初始化过程相似。
2.2.2 数据入栈
deque.push("a");,ArrayDeque,提供了一个 push 方法,这个方法与deque.offerFirst(“a”),一致,因为它们的底层源码是一样的,如下;
addFirst:
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
doubleCapacity();
}addLast:
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
}这部分入栈元素,其实就是给数组赋值,知识点如下;
- 在
addFirst()中,定位下标,head = (head - 1) & (elements.length - 1),因为我们的数组长度是2^n的倍数,所以2^n - 1就是一个全是1的二进制数,可以用于与运算得出数组下标。 - 同样
addLast()中,也使用了相同的方式定位下标,只不过它是从0开始,往上增加。 - 最后,当头(head)与尾(tile),数组则需要两倍扩容
doubleCapacity。
下标计算:head = (head - 1) & (elements.length - 1):
- (0 - 1) & (8 - 1) = 7
- (7 - 1) & (8 - 1) = 6
- (6 - 1) & (8 - 1) = 5
- ...
2.2.3 两倍扩容,数据迁移
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p; // number of elements to the right of p
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
System.arraycopy(elements, p, a, 0, r);
System.arraycopy(elements, 0, a, r, p);
elements = a;
head = 0;
tail = n;
}其实以上这部分源码,就是进行两倍n << 1扩容,同时把两端数据迁移进新的数组,整个操作过程也与我们上图对应。为了更好的理解,我们单独把这部分代码做一些测试。
测试代码:
@Test
public void test_arraycopy() {
int head = 0, tail = 0;
Object[] elements = new Object[8];
elements[head = (head - 1) & (elements.length - 1)] = "a";
elements[head = (head - 1) & (elements.length - 1)] = "b";
elements[head = (head - 1) & (elements.length - 1)] = "c";
elements[head = (head - 1) & (elements.length - 1)] = "d";
elements[tail] = "e";
tail = (tail + 1) & (elements.length - 1);
elements[tail] = "f";
tail = (tail + 1) & (elements.length - 1);
elements[tail] = "g";
tail = (tail + 1) & (elements.length - 1);
elements[tail] = "h";
tail = (tail + 1) & (elements.length - 1);
System.out.println("head:" + head);
System.out.println("tail:" + tail);
int p = head;
int n = elements.length;
int r = n - p; // number of elements to the right of p
// 输出当前的元素
System.out.println(JSON.toJSONString(elements));
// head == tail 扩容
Object[] a = new Object[8 << 1];
System.arraycopy(elements, p, a, 0, r);
System.out.println(JSON.toJSONString(a));
System.arraycopy(elements, 0, a, r, p);
System.out.println(JSON.toJSONString(a));
elements = a;
head = 0;
tail = n;
a[head = (head - 1) & (a.length - 1)] = "i";
System.out.println(JSON.toJSONString(a));
}以上的测试过程主要模拟了8个长度的空间的数组,在进行双端队列操作时数组扩容,数据迁移操作,可以单独运行,测试结果如下;
head:4
tail:4
["e","f","g","h","d","c","b","a"]
["d","c","b","a",null,null,null,null,null,null,null,null,null,null,null,null]
["d","c","b","a","e","f","g","h",null,null,null,null,null,null,null,null]
["d","c","b","a","e","f","g","h","j",null,null,null,null,null,null,"i"]
Process finished with exit code 0从测试结果可以看到;
- 当head与tail相等时,进行扩容操作。
- 第一次数据迁移,
System.arraycopy(elements, p, a, 0, r);,d、c、b、a,落入新数组。 - 第二次数据迁移,
System.arraycopy(elements, 0, a, r, p);,e、f、g、h,落入新数组。 - 最后再尝试添加新的元素,i和j。每一次的输出结果都可以看到整个双端链路的变化。
3. 双端队列LinkedList
Linkedlist天生就可以支持双端队列,而且从头尾取数据也是它时间复杂度O(1)的。同时数据的插入和删除也不需要像数组队列那样拷贝数据,虽然Linkedlist有这些优点,但不能说ArrayDeque因为有数组复制性能比它低。
Linkedlist,数据结构:
3.1 功能使用
@Test
public void test_Deque_LinkedList(){
Deque<String> deque = new LinkedList<>();
deque.push("a");
deque.push("b");
deque.push("c");
deque.push("d");
deque.offerLast("e");
deque.offerLast("f");
deque.offerLast("g");
deque.offerLast("h");
deque.push("i");
deque.offerLast("j");
System.out.println("数据出栈:");
while (!deque.isEmpty()) {
System.out.print(deque.pop() + " ");
}
}测试结果:
数据出栈:
i d c b a e f g h j
Process finished with exit code 0- 测试结果上看与使用
ArrayDeque是一样的,功能上没有差异。
3.2 源码分析
压栈:deque.push("a");、deque.offerFirst("a");
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}压栈:deque.offerLast("e");
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}linkFirst、linkLast,两个方法分别是给链表的首尾节点插入元素,因为这是链表结构,所以也不存在扩容,只需要把双向链路链接上即可。
4. 延时队列DelayQueue
你是否有时候需要把一些数据存起来,倒计时到某个时刻在使用?
在Java的队列数据结构中,还有一种队列是延时队列,可以通过设定存放时间,依次轮训获取。
4.1 功能使用
先写一个Delayed的实现类:
public class TestDelayed implements Delayed {
private String str;
private long time;
public TestDelayed(String str, long time, TimeUnit unit) {
this.str = str;
this.time = System.currentTimeMillis() + (time > 0 ? unit.toMillis(time) : 0);
}
@Override
public long getDelay(TimeUnit unit) {
return time - System.currentTimeMillis();
}
@Override
public int compareTo(Delayed o) {
TestDelayed work = (TestDelayed) o;
long diff = this.time - work.time;
if (diff <= 0) {
return -1;
} else {
return 1;
}
}
public String getStr() {
return str;
}
}- 这个相当于延时队列的一个固定模版方法,通过这种方式来控制延时。
案例测试:
@Test
public void test_DelayQueue() throws InterruptedException {
DelayQueue<TestDelayed> delayQueue = new DelayQueue<TestDelayed>();
delayQueue.offer(new TestDelayed("aaa", 5, TimeUnit.SECONDS));
delayQueue.offer(new TestDelayed("ccc", 1, TimeUnit.SECONDS));
delayQueue.offer(new TestDelayed("bbb", 3, TimeUnit.SECONDS));
logger.info(((TestDelayed) delayQueue.take()).getStr());
logger.info(((TestDelayed) delayQueue.take()).getStr());
logger.info(((TestDelayed) delayQueue.take()).getStr());
}测试结果:
01:44:21.000 [main] INFO org.itstack.interview.test.ApiTest - ccc
01:44:22.997 [main] INFO org.itstack.interview.test.ApiTest - bbb
01:44:24.997 [main] INFO org.itstack.interview.test.ApiTest - aaa
Process finished with exit code 0- 在案例测试中我们分别设定不同的休眠时间,1、3、5,TimeUnit.SECONDS。
- 测试结果分别在21、22、24,输出了我们要的队列结果。
- 队列中的元素不会因为存放的先后顺序而导致输出顺序,它们是依赖于休眠时长决定。
4.2 源码分析
4.2.1 元素入栈
入栈::delayQueue.offer(new TestDelayed("aaa", 5, TimeUnit.SECONDS));
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
size = i + 1;
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}
private void siftUpUsingComparator(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}- 关于数据存放还有
ReentrantLock可重入锁🔒,但暂时不是我们本章节数据结构的重点,后面章节会介绍到。 DelayQueue是基于数组实现的,所以可以动态扩容,另外它插入元素的顺序并不影响最终的输出顺序。- 而元素的排序依赖于compareTo方法进行排序,也就是休眠的时间长短决定的。
- 同时只有实现了
Delayed接口,才能存放元素。
4.2.2 元素出栈
出栈:delayQueue.take()
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek();
if (first == null)
available.await();
else {
long delay = first.getDelay(NANOSECONDS
if (delay <= 0)
return q.poll();
first = null; // don't retain ref while
if (leader != null)
available.await();
else {
Thread thisThread = Thread.currentT
leader = thisThread;
try {
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
}- 这部分的代码有点长,主要是元素的获取。
DelayQueue是Leader-Followr模式的变种,消费者线程处于等待await时,总是等待最先休眠完成的元素。 - 这里会最小化的空等时间,提高线程利用率。数据结构讲完后,后面会有专门章节介绍
5. 还有哪些队列?
5.1 队列类结构
| 类型 | 实现 | 描述 |
|---|---|---|
| Queue | LinkedBlockingQueue | 由链表结构组成的有界阻塞队列 |
| Queue | ArrayBlockingQueue | 由数组结构组成的有界阻塞队列 |
| Queue | PriorityBlockingQueue | 支持优先级排序的无界阻塞队列 |
| Queue | SynchronousQueue | 不存储元素的阻塞队列 |
| Queue | LinkedTransferQueue | 由链表结构组成的无界阻塞队列 |
| Deque | LinkedBlockingDeque | 由链表结构组成的双向阻塞队列 |
| Deque | ConcurrentLinkedDeque | 由链表结构组成的线程安全的双向阻塞队列 |
- 除了我们已经讲过的队列以外,剩余的基本都是阻塞队列,也就是上面这些。
- 在数据结构方面基本没有差异,只不过添加了相应的阻塞功能和锁的机制。
5.2 使用案例
public class DataQueueStack {
private BlockingQueue<DataBean> dataQueue = null;
public DataQueueStack(){
//实例化队列
dataQueue = new LinkedBlockingQueue<DataBean>(100);
}
/**
* 添加数据到队列
* @param dataBean
* @return
*/
public boolean doOfferData(DataBean dataBean){
try {
return dataQueue.offer(dataBean, 2, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
return false;
}
}
/**
* 弹出队列数据
* @return
*/
public DataBean doPollData(){
try {
return dataQueue.poll(2, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
return null;
}
}
/**
* 获得队列数据个数
* @return
*/
public int doGetQueueCount(){
return dataQueue.size();
}
}- 这是一个
LinkedBlockingQueue队列使用案例,一方面存储数据,一方面从队列中获取进行消费。 - 因为这是一个阻塞队列,所以在获取元素的时候,如果队列为空,会进行阻塞。
LinkedBlockingQueue是一个阻塞队列,内部由两个ReentrantLock来实现出入队列的线程安全,由各自的Condition对象的await和signal来实现等待和唤醒功能。
五、总结
- 关于栈和队列的数据结构方面到这里就介绍完了,另外这里还有一些关于阻塞队列锁🔒的应用过程,到我们后面讲锁相关知识点,再重点介绍。
- 队列结构的设计非常适合某些需要
LIFO或者FIFO的应用场景,同时在队列的数据结构中也有双端、延时和组合的功能类,使用起来也非常方便。 - 数据结构方面的知识到本章节算是告一段落,如果有优秀的内容,后面还会继续补充。再下一章节小傅哥(bugstack.cn)准备给大家介绍,关于数据结构中涉及的算法部分,这些主要来自于
Collections类的实现部分。