
前面,我们完成了spring boot开发的基本项目骨架的搭建,在进一步学习实践spring boot应用开发之前,我们先来设计下数据库部分。
我们将采用一个“小卷生鲜”的电商项目来贯穿整个spring boot的学习。首先我们来设计这个电商项目的表结构,我们采用的是powerdesigner数据库建模软件。
PowerDesigner基本使用
为了更好的维护数据库表结构,我们将采用数据库建模工具来代替手写ddl的方式,因为前者可以更直观的展示数据库表的信息以及表与表之间的关系,将设计做成物理模型后,也便于后期的维护(管理好不同版本的pdm文件即可),而要对比不同版本之间的差异,只要从pdm导出ddl内容用对比软件即可发现差异。
创建pdm
File | New Model | Physical Data Model
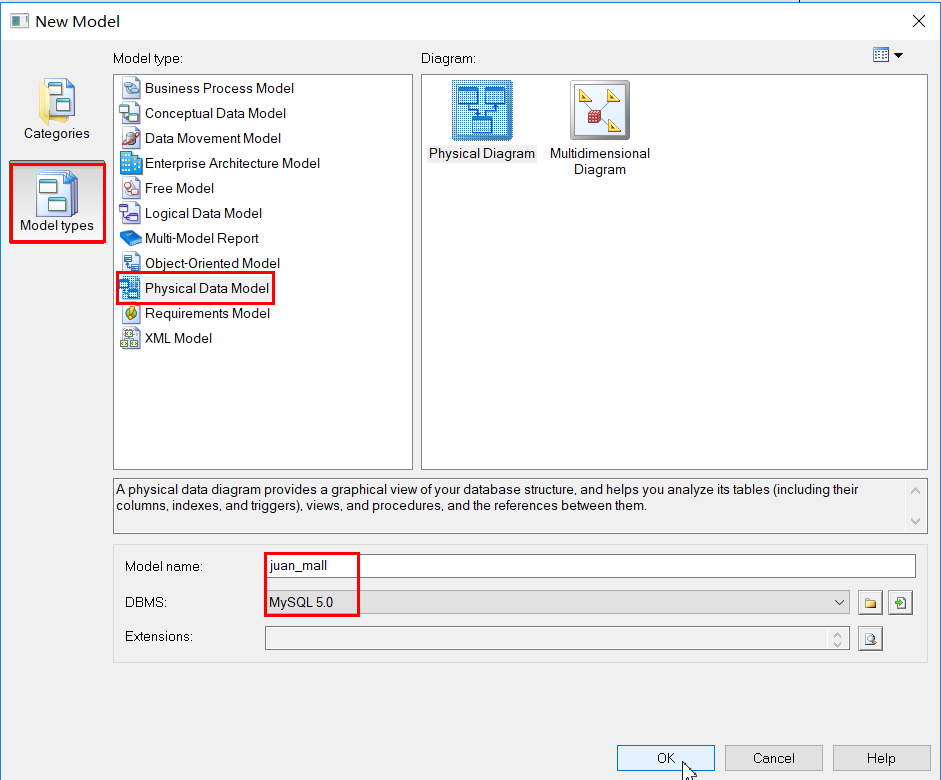
这里我们建立的物理模型所对应的数据库为MySQL。
创建表
创建表很简单,只要在右侧工具箱里选择代表Table的图标,在绘图区点一下就生成了一张待编辑的表。
定义表的信息:
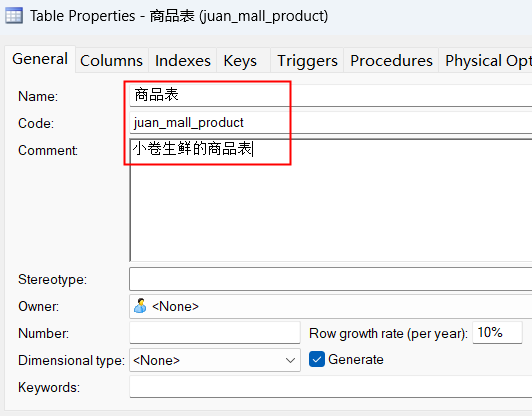
注意这里的表名命名规范为:项目名称_表名称。
接下来切换到Columns选项卡来定义表中的列信息。要定义的列的属性可以点如下的过滤图标:

在弹出的界面中勾选,然后点ok,这样勾选上的属性就会显示出来:
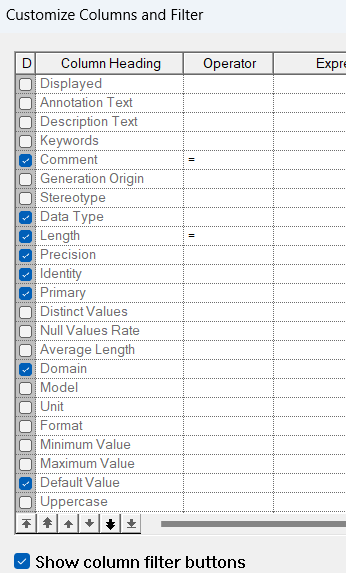

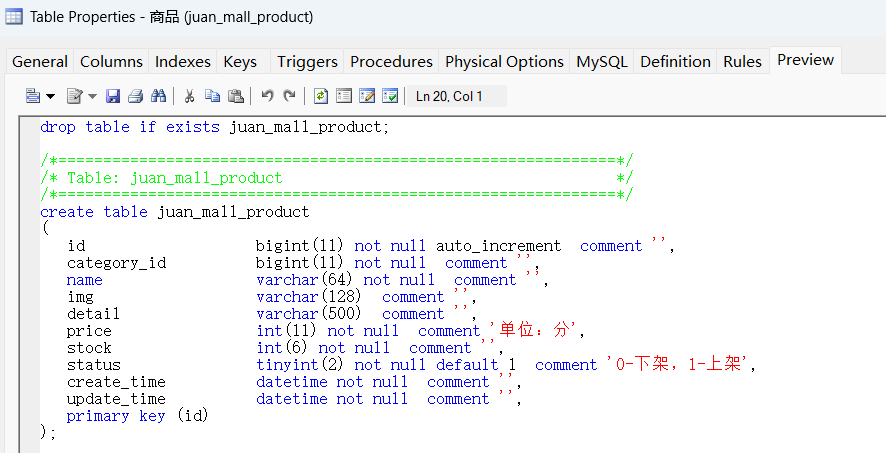
然后定义每一列的信息。
定义好后,可以点预览进行查看:
创建key
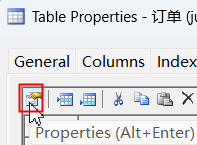
比如订单表中的订单号我们可以添加唯一约束,具体操作,点到Keys选项卡,看到默认生成一个主键的key,新点一行,然后点Properties:
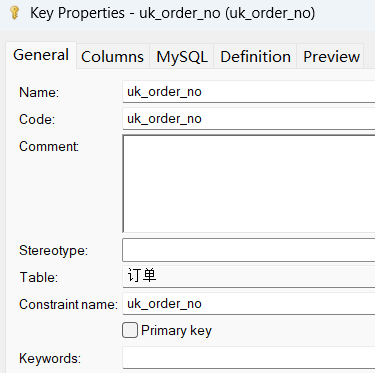
设置约束的名称:
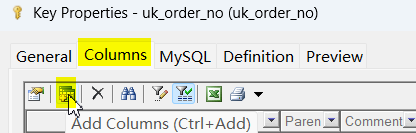
再点到Columns选项卡,选择要创建key的列:
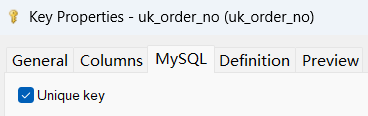
再点到MySQL选项卡,勾选唯一约束,最后点确定,完成创建。
创建index
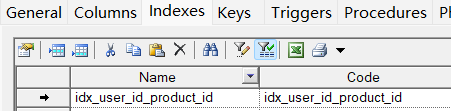
假如数据库中设计了一张购物车表来存储用户添加到购物车中的商品,因为用户规模庞大,这张表的数据量很大,要查询某个用户选购的商品,可以用用户id、商品id的联合索引来提高检索效率。

创建步骤:
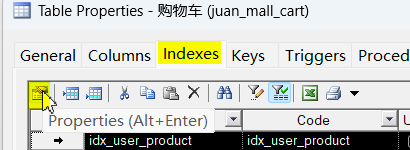
按索引中列的顺序逐一添加,最后点确定。
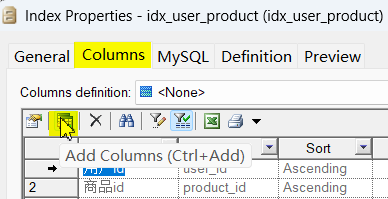
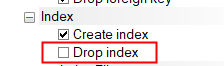
在ddl生成选项中取消drop index选项,这样第一次执行时,脚本不会报错。因为表被drop了,在上面建立的索引都会被删除,也就不用再单独drop索引了
添加关联关系
为了更好的展示表与表之间的关联关系,我们还可以添加外键,注意这里我们只是想在模型视图上体现出关系,而实际的ddl中不会生成外键。具体操作如下:
先点关系图标:
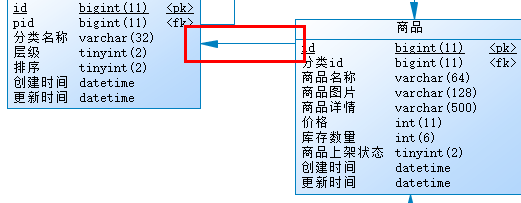
然后在绘图区域,鼠标点从表将箭头拖到主表,这样外键关系就建立了。比如商品表与分类表之间通过分类id建立的关系:
双击,编辑关系,注意,这里要把外键生成关系的选项取消勾选:
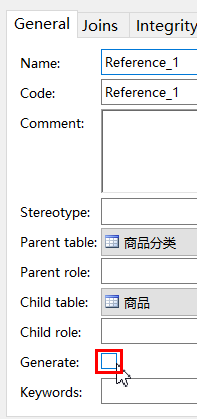
然后指定子表的哪个字段和主表的主键(一般都是主键)建立关系:
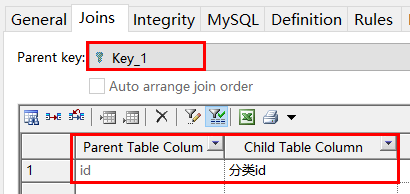
如果关联的主表不是主键,比如订单项表和订单表是订单号关联的,只要在Parent key下拉框中选None即可,然后可以选择主表的字段了。
践行数据库设计规范
命名规范
所有数据库对象和表字段、key、index的命名都统一用小写。
数据库命名
现在我们做的spring boot单体应用,可以命名为db_juan_mall。后面拆成微服务模块后,可以命名为db_juan_mall_user。我们定的规范如下:
db_项目名
db_项目名_模块名表命名
单体应用对应的订单项表命名为tb_order_item,如果是微服务项目,且各个微服务模块共用一个库,用户模块的身份校验表可以命名为tb_user_auth;否则,加上库名的命名为:db_juan_mall_user.tb_auth。我们定的规范如下:
单体应用:
db_项目名.tb_表名
微服务模块:
db_项目名.tb_模块名_表名 db_juan_mall.tb_order_main
db_项目名_模块名.tb_表名 db_juan_mall_order.tb_order_main实践
在第一部分创建表时没考虑表要以
tb_开头,现在补上。
key和index命名
普通key -> k_字段名
主键 -> pk_字段名
联合主键 -> pk_字段1_字段2
唯一键 -> uk_字段名
外键 -> fk_字段名 (很少用)
普通索引 -> idx_字段名
组合索引 -> idx_字段1_字段2实践
在第一部分创建key和index时考虑命名规范,现补上
字段命名
所有主键都命名为id。其他命名单词之间都用_连接,尽量做到见名知意。在当前表中,没有歧义的情况下可以省略实体名,如下:

类型选择
在选择类型时要遵循以下几点:
选择存储空间最小的
这里又涉及到几点:
存储字符串的值时,除非长度是固定的可以选择
char(n)来存储,其他则用varchar(n)使用
varchar(n)时,要考虑n的值的存储上限能用数值型的就不要用字符串了,比如存订单的状态,状态值能存为整型,就不要用
varchar(2)
这里我们没有用
int(2),而是tinyint(2),因为后者存储的空间更小。
少用enum类型
不好维护,可以用字典表代替
少用text、blob类型
可以用
varchar(2000)这种可以存储大文本值的类型代替,如果非要用,单独分出一张子表来存涉及金额或者带小数值的存储一般用
decimal(m, n)对于金额巨大的存储场景可以用
bigint(11)这样的类型,单位精确到分,这样既可以满足存储空间和精度,又能避免decimal类型的计算代价。日期类型如果有时区时差的特别要求,用
timestamp,一般的系统创建时间、更新时间用datetime即可。
反范式适当冗余
适当冗余的好处:保留历史快照信息、减少表关联。比如订单项表中冗余的商品信息:

合理使用索引
通常在数据库表中数据量比较大并且作为查询条件比较频繁的字段上,我们都建议加上索引。作为主键的字段默认会加索引,还有添加了唯一键约束的字段也会走索引。这里我们看实际的例子:
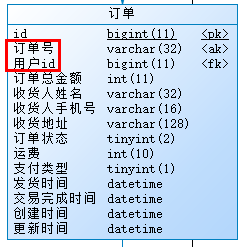
这里的订单表中,显而易见,数据量会非常的大,而订单状态字段查询不会那么频繁,因此不用管。而订单号每个订单都一样,这里我们可以加唯一键约束(unique key),而用户id作为关联用户的外键(当然我们不会建外键)也会经常被作为条件使用,因此我们可以为其建立普通key索引。
再比如购物车表和订单项表,也有经常用到的关联字段:
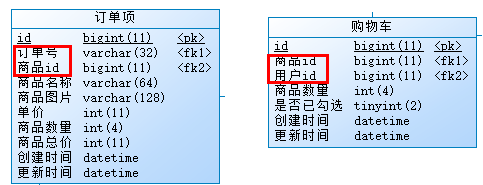
要注意查询的维度,这里订单号或者用户id会查出一批数据,然后再由商品id字段进一步查询确定一条记录。而这两个表我们都不会直接用商品id字段来查询。因此,经过分析,这里我们将为这两张表都建立一个组合索引(注意顺序)。
最终我们的小卷生鲜数据库表结构设计如下:
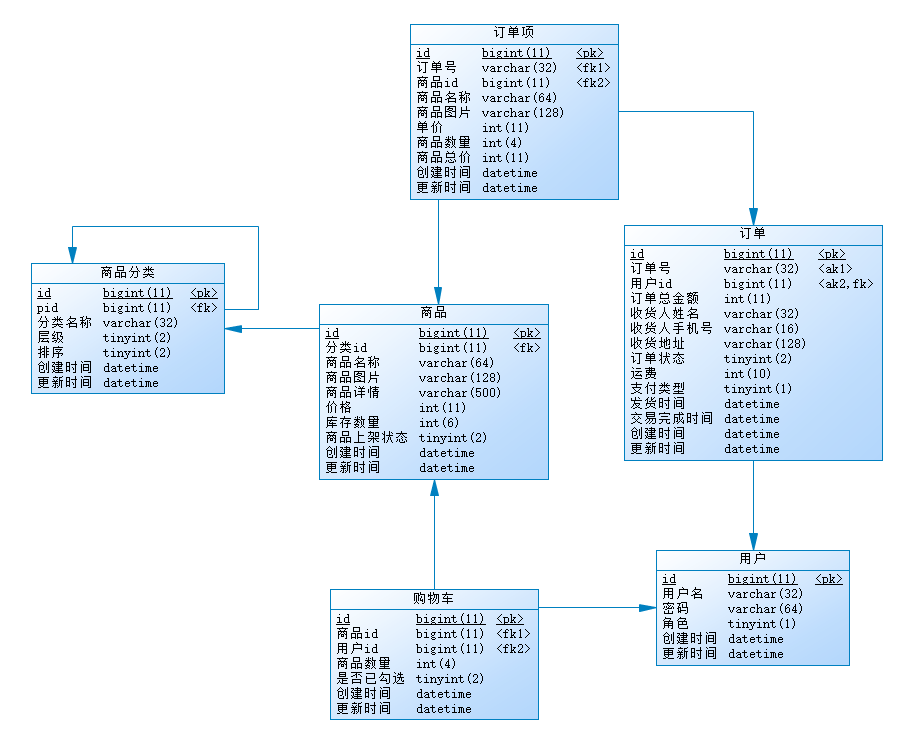
好了,我们的数据库表设计的也差不多了,下一节,我们将pdm导出ddl,然后基于它来建库建表,把我们的数据库环境在本地搭建好,方便后面连库开发。