大家好,我是皮皮。
一、前言
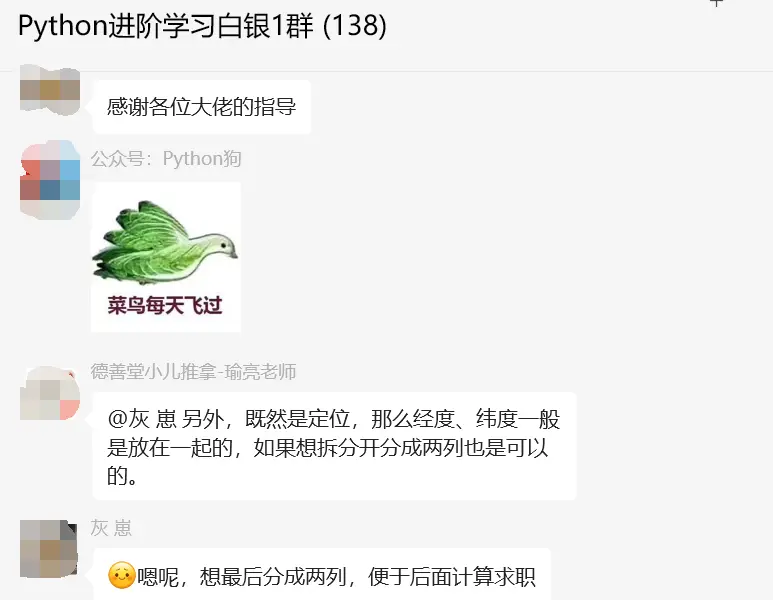
上一篇文章我们使用了Python来实现数据的导入和分列处理,最终可以得到符合预期的结果,不过还可以继续深挖优化下,这一篇文章一起来看看吧。优化的背景如下图所示:
二、实现过程
这里【瑜亮老师】继续给了一个优化指导,如下图所示:
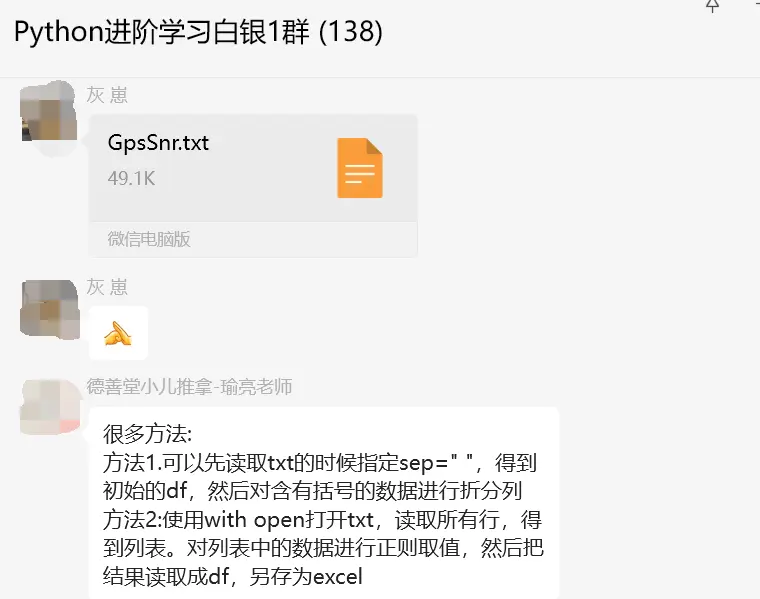
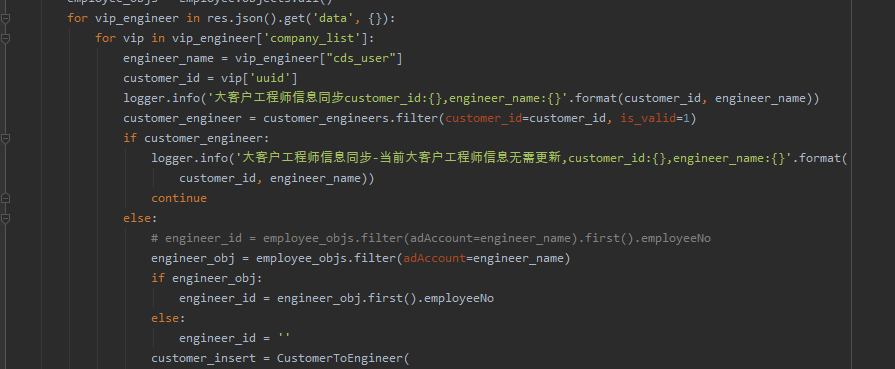
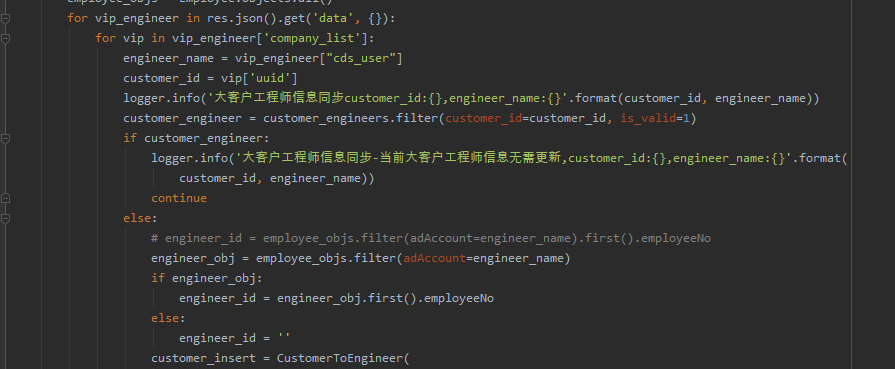
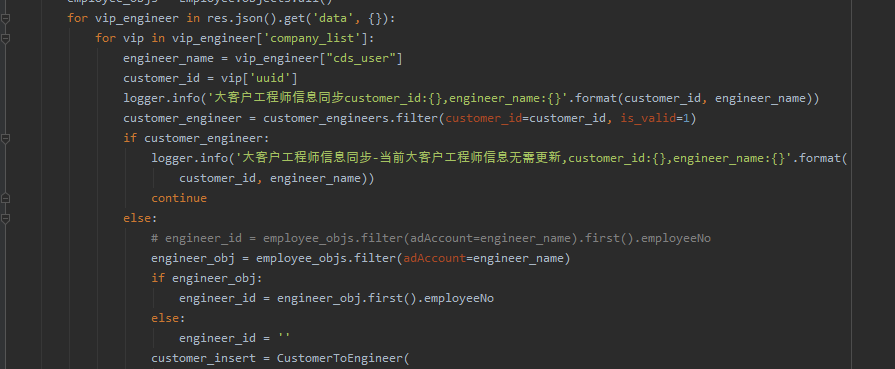
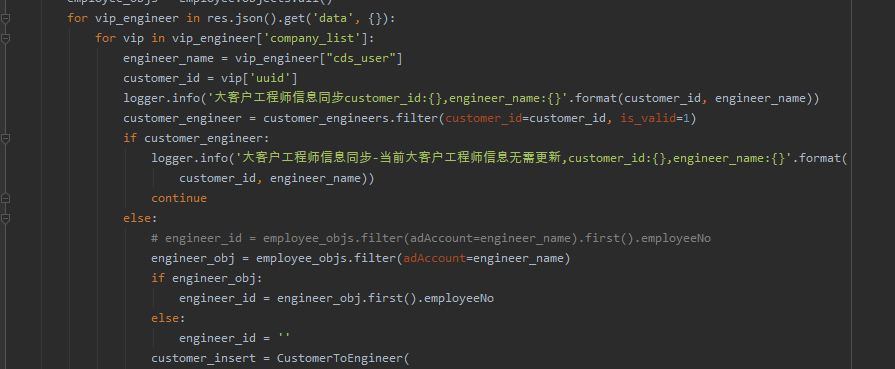
并且给出的代码如下:
with open("./GpsSnr.txt", "r", encoding="utf-8") as f:
txt = f.readlines()
regex =r"\((\d+,\d+\.\d+)\)"
temp = [re.findall(regex, x) for x in txt]
df = pd.DataFrame(temp)
# 这样保存下来的就是经纬度在一起的
# df.to_excel('GpsSnr1.xlsx', index=False)
# 下面是把经纬度分开
data = []
for i in df.columns:
data.append(df[i].str.split(',', expand=True))
df = pd.concat(data, axis=1)
df.columns = [a+str(b) for a in ['gps','glnoss','beidou'] for b in range(10)]
# print(df.head())
df.to_excel('GpsSnr2.xlsx', index=False)下图是部分指导:
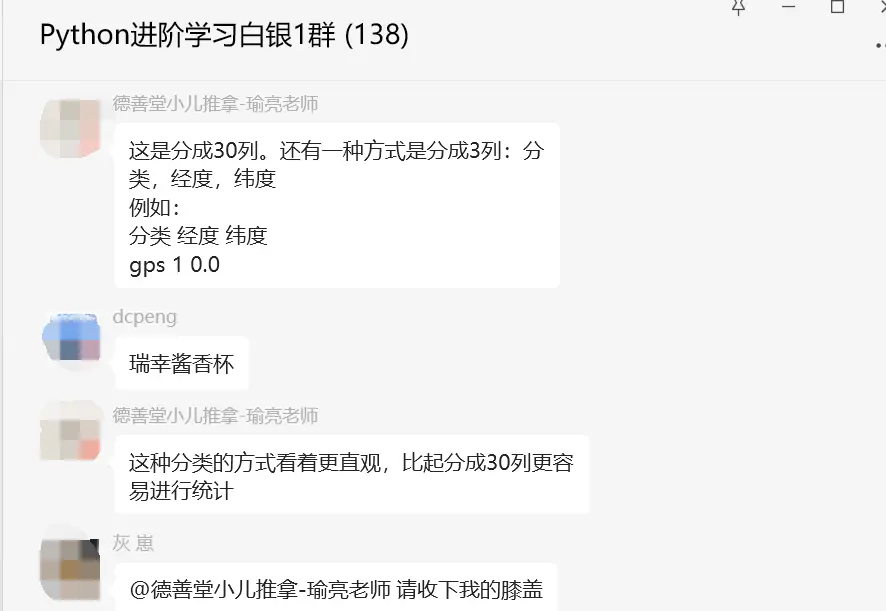
顺利地解决了粉丝的问题。
其实分成3列更容易进行研究,比如需要对分类为beidou,经纬度在某个范围内的数据进行研究,分成3列这种只需要进行简单的筛选就可以提取出来数据。而分成30列的,就需要对columns进行提取,再处理经纬度,比较麻烦。后来【瑜亮老师】还继续推演,感兴趣的小伙伴们也可以尝试下哦。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python自动化办公的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【灰崽】提问,感谢【瑜亮老师】、【王者级混子】给出的思路和代码解析,感谢【甯同学】、【莫生气】、【kim】、【🐯厚德载物🍀】、【FANG.J】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。