

2020年下半年的主要任务,就是从0到1搭建了数据传输服务平台产品。平稳上线后,基本达到预期,实现了最初的产品规划目标。
这里做个复盘,记录下从0到1的过程,包括:
产品设计
整体技术架构
核心模块的技术选型、原理与改造适配
总结与展望
1.什么是数据传输服务
数据传输服务DTS(Data Transmission System)的目标是支持RDBMS、NoSQL、OLAP等数据源间的数据交互,集数据迁移/订阅/同步于一体,帮助构建安全、可扩展、高可用的数据架构。
当然,目前我们的核心存储还是以MySQL为主,因此,自研的数据传输服务的首要数据源是MySQL。
为什么不直接采用公有云产品呢,比如阿里云DTS?
主要原因是为了能更好地对接内部其他系统,支持许多内部系统数据迁移/同步的自动化流程需求。同时,业内相关开源技术非常丰富且成熟,有很多现成的轮子可以使用,可以大大降低云服务使用成本。
2.产品设计
对于DTS的最强烈需求来源,是正在推进的多云架构,需要能够构建多云数据库镜像。同时,我们又深入调研了其他业务需求,得到了众多用户场景。
包括但不限于:
数据库多云同步
分库分表数据同步
ES 索引构建
压测数据、线下导入/同步
缓存刷新,Local cache/Redis cache等刷新
业务数据变更订阅
CQRS模式实现
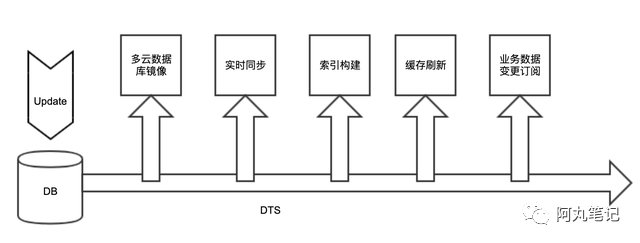
这些场景经过归纳整理,得到了DTS的三大产品功能模块。
数据订阅模块:支持ES索引构建 、缓存刷新、业务数据变更订阅、CQRS模式实现
数据迁移模块:支持数据库多云同步、分库分表数据同步、压测数据、线下导入
数据同步模块:支持数据库多云同步、分库分表数据同步、压测数据、线下导入/同步
3.整体技术架构
整个DTS系统分为三个 逻辑层次,交互层、控制层、引擎层。
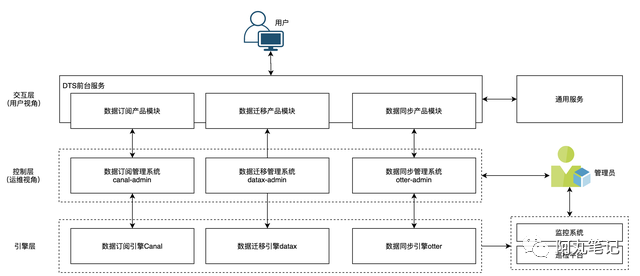
3.1 交互层
交互层就是用户可见的前台DTS产品,是用户视角的DTS系统。
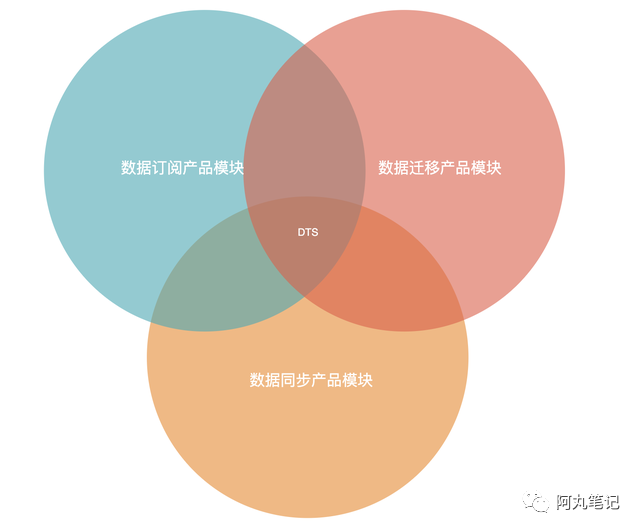
1)产品模块
系统中包含了数据订阅产品模块、数据迁移产品模块、数据同步产品模块。
用户通过与各个产品模块交互,直接获取对应产品模块任务信息,实现对模块任务的管理,包括创建、启动、停止、释放、任务监控信息等。
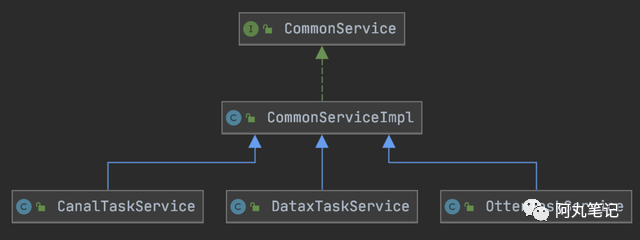
2)通用服务
交互层除了产品模块之外,用户能够感知到的交互能力还包括了用户管理、权限管理、变更管理、基本任务信息管理等 通用服务能力。
这些通用服务能力可以来自于其他内部系统,也可以是独立设计的。
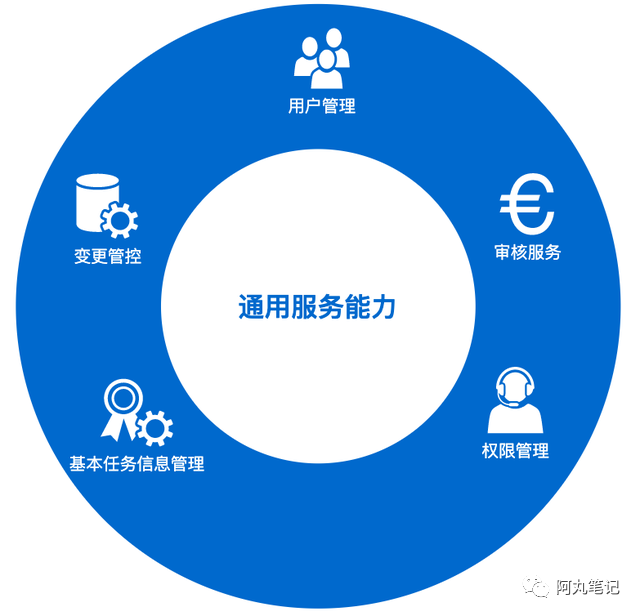
最重要的是,这些通用服务可以复用于DTS未来的产品扩展,包括Redis的数据同步、HBase数据同步。
3)核心设计
正如一开始提到,虽然目前我们以MySQL为主,但是未来肯定会扩展到其他数据源的数据迁移与同步。
因此交互层的核心实现采用 模板模式 ,实现了基础任务的创建、启动、停止、释放、审核、鉴权等流程。
将基础任务流程中的特定动作,如启动引擎任务、停止引擎任务等具体实现放在各个模块的实现类中进行实现。
实现了DTS模块化设计和极高的可扩展性,为未来接入其他 迁移/同步引擎(Redis/Hbase) 打下基础。
3.2 控制层
控制层是面向管理员的操作平台。
这一层主要面向运维视角,实现对引擎层的监控、启停、扩容等能力。
对比交互层产品模块,这一层次的控制台会有更复杂的任务控制选项,同时,也会具备很多运维层面的操作,比如引擎层的服务器管理能力等。
Canal、otter等开源产品都已经自带了相关控制台,可以直接使用。

3.3 引擎层
引擎层是整个系统的核心部分,目前的架构设计下,引擎层的引擎都是支持扩展、支持替换的。
目前全部采用开源项目,包括:
数据迁移引擎采用Datax:https://github.com/alibaba/DataX
数据订阅引擎采用canal: https://github.com/alibaba/canal
数据同步引擎采用otter: https://github.com/alibaba/otter
对于引擎层,最核心的在于技术选型。需要结合业务需求、开源项目稳定性、开源项目功能特点综合分析,下文我们会仔细展开说明。
另外,对于生产环境使用的项目,必须做好配套的监控告警措施,保证线上的稳定性。
otter/canal都有现成的监控指标,我们需要将 同步延迟 等关键指标进行采集,并设置合理的告警阈值。
同时,对于一些没有现成的监控指标,比如 任务存活状态 等,我们可以通过 巡检 进行定时检查,避免由于同步任务挂起而影响上层业务。
4.数据订阅模块
4.1 技术选型
数据订阅实际上就是一种CDC(Change Data Capture)工具,目前开源产品中比较成熟的有Canal、DataX、DataBus、Debezium等。
整体而言,Canal、DataX、Debezium的使用人数多,社区活跃,框架也比较成熟。在满足应用场景的前提下,优先选择,代价适中。
DataX支持丰富,使用简单,但延迟较大(依赖获取频率),只需要手写规则文件,对复杂同步自定义性不强。
Debezium虽然比Canal支持更多类型的数据源,但是我们实际上只需要mysql,并不需要PostgreSQL这些的支持。
而Canal有几点特性我们非常需要,让我们决定使用Canal作为数据订阅引擎:
对阿里云RDS有特殊定制优化,可以自动下载备份到oss的binlog文件然后指定位点开始同步
有非常友好的控制台
支持投递到Rocketmq
新版本的Canal-Adapter可以支持多种客户端消费,包括mysql、es等
4.2 基本原理
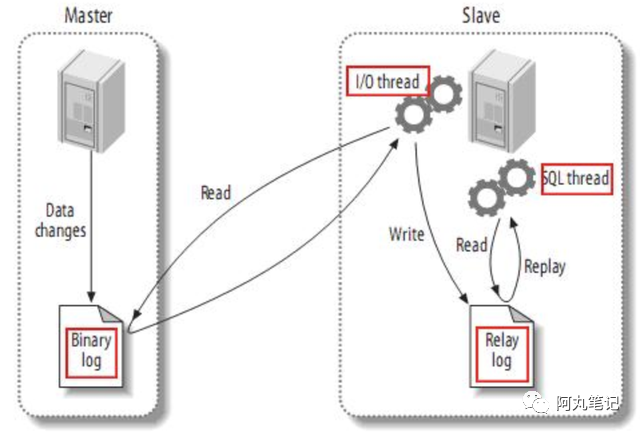
数据订阅的原理基本一样,都是基于MySQL的主从复制原理实现。
MySQL的主从复制分成三步:
master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);
slave将master的binary log events拷贝到它的中继日志(relay log);
slave重做中继日志中的事件,将改变反映它自己的数据。
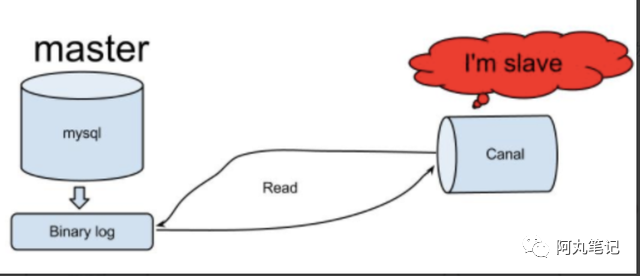
Canal 就是模拟了这个过程。
Canal模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议;
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal );
Canal 解析 binary log 对象(原始为 byte 流);
4.3 部署架构
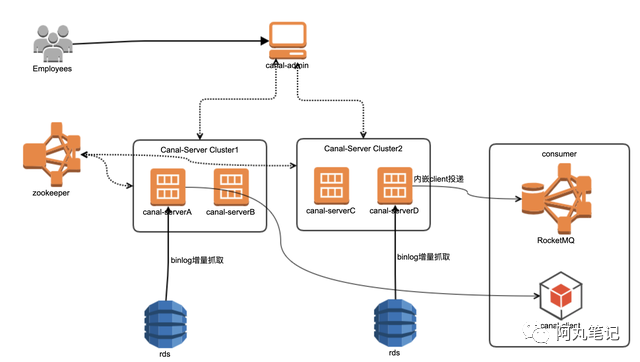
核心组件:
zookeeper:使用已有的zookeeper集群,实现订阅任务的HA
canal-admin:数据订阅的控制层的控制台,管理canal-server上的订阅任务状态与配置
canal-server:用于运行数据订阅任务,抓取数据库binlog,投递到MQ或者下游client。
4.4 使用方式
Canal支持TCP直接消费、MQ消费两种模式。
为了支持多个下游消费,减少上游数据库订阅压力,我们使用了MQ消费模式。
将数据库订阅binlog投递到Rocketmq,下游用户可以利用Rocketmq的Consumer _Group_,多次、重复消费对应数据,实现业务解耦、缓存一致性等场景。
4.5 改造适配
1)控制台api封装
由于canal-admin的技术栈还是比较新的,有比较成熟的分层结构和独立的rpc接口,因此,在DTS服务中,包装相关canal-admin的接口,即可实现产品化的前台接口逻辑。
2)云原生改造
计划中,改造为k8s部署,支持快速扩缩容
5.数据迁移模块
5.1 技术选型
跟数据订阅不同,Mysql的数据迁移五花八门,实现原理也都各不相同。
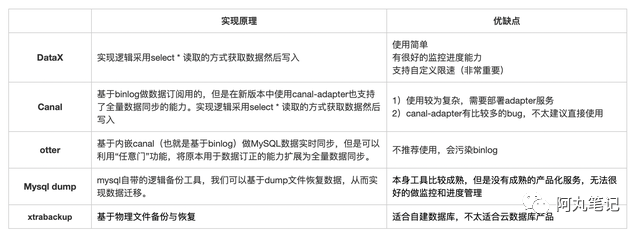
综合来看,我们选择了DataX作为数据迁移引擎。
5.2 基本原理
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
我们主要使用了MySQL的数据同步,它的实现原理比较简单,就是通过
select * from table;
获取全量数据,然后写入到目标库中。
当然,这里利用了JDBC的流式查询,避免OOM。同时,datax也支持自定义限速。
5.3 部署架构与使用方式
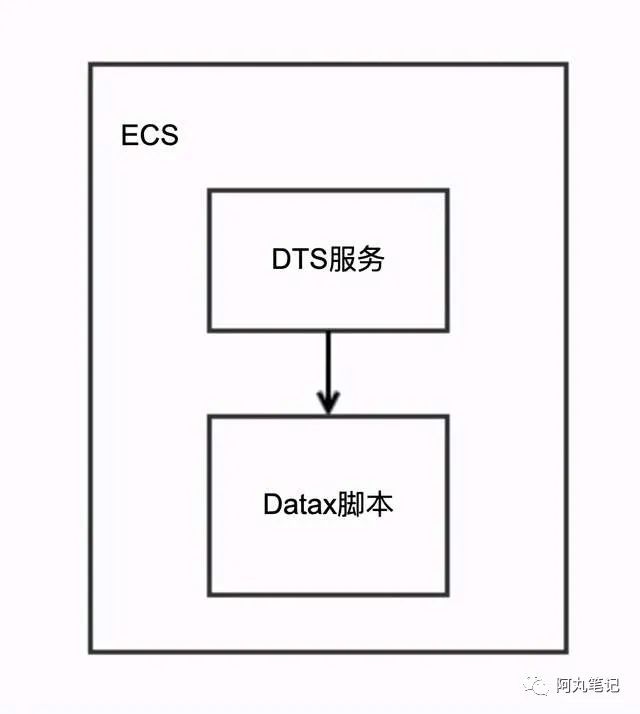
Datax的使用方式比较简单,通过配置任务Json,执行脚本即可。
由于数据迁移使用不多,且基本是一次性使用,所以暂时是直接部署在DTS的服务中,通过Java的Process类进行相关处理。
创建Datax所需的conf文件,并返回地址
使用Runtime.getRuntime().exec()执行 Datax的python脚本
根据返回的Process对象,处理成功/失败、执行输出日志等
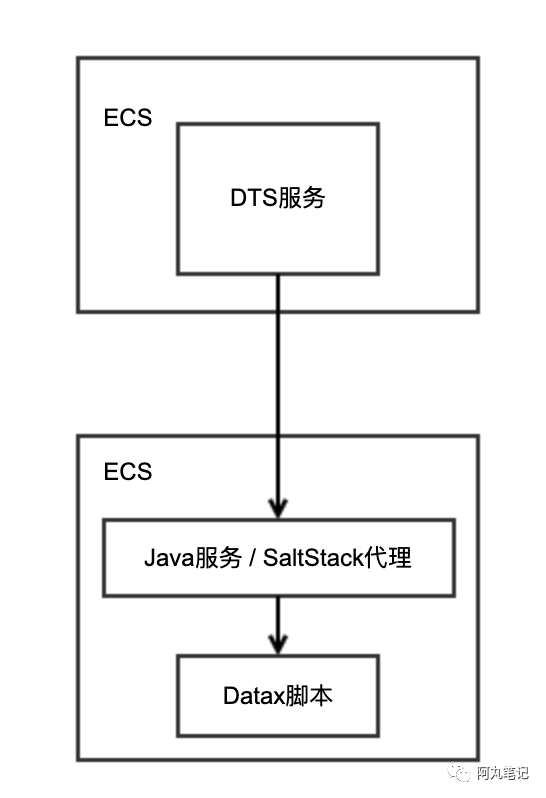
后面会考虑进一步迭代,采用独立服务器部署Datax,然后通过自定义Java服务或者使用Saltstack实现远程调用脚本。
6.数据同步模块
6.1 技术选型
数据同步的方案主要有三种

综合实施性、技术成熟度、双向同步需求的考虑,我们选择了otter作为数据同步引擎。
6.2 基本原理
基于Canal开源产品,获取数据库增量日志数据。Canal原理参考 数据订阅 的基本原理。
典型管理系统架构,manager(web管理)+node(工作节点)。
6.3 部署架构
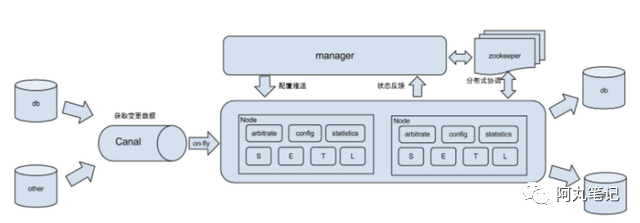
核心组件:
zookeeper:解决分布式状态调度的,允许多node节点之间协同工作
manager: 运行时推送同步配置到node节点
node: 内嵌canal,负责binlog订阅,并把事件同步到目标数据库;同时,将同步状态反馈到manager上
6.4 改造适配
1)控制台api封装
由于otter-admin的技术栈比较旧,采用webx框架实现,没有前后端分离。
因此,需要根据已有代码,重新封装独立的rpc接口,然后才能对接到DTS服务中,包装相关otter-admin的接口,实现产品化的前台接口逻辑。
2)云原生改造
改造为k8s部署,支持快速扩缩容,具体可以参考我上一篇文章 拥抱云原生,如何将开源项目用k8s部署?
7.总结与展望
从产品设计、技术调研、架构设计到最后研发上线,历时半年左右。最终功夫不负有心人,项目顺利上线,通过前台产品的简单交互与审核,就能秒级快速创建DTS任务。
目前已经支持数十个DTS任务(包括数据订阅、数据迁移、数据同步),落地了多云数据库镜像、ES索引构建、数据实时同步、业务数据订阅等多个业务场景。
未来,还需要做进一步的技术迭代,包括:
1)扩展数据传输引擎
目前已经在尝试接入Redis-shake做Redis的迁移与同步。
后面还会继续尝试HBase-replication的接入,做HBase相关的任务迁移与同步。
这些都可以通过复用 通用服务能力 和 模版流程,实现快速接入。
2)增加调度模块
后续还需要增加任务调度模块,主要实现两方面的能力:
根据实例负载进行任务的调度,保证资源的合理使用
根据业务特性、重要程度做任务调度,保证资源隔离
3)完成云原生化改造
目前只有otter引擎实现了k8s部署,后面还需要对canal-server、Datax实现k8s部署,满足快速扩缩容,提高资源使用率。
如果有任何疑问或者建议,欢迎 写留言 或者微信和我联系哦~
往期热门笔记合集推荐:
原创:阿丸笔记(微信公众号:aone_note),欢迎 分享,转载请保留出处。
扫描下方二维码可以关注我哦~

觉得不错,就点个 再看 吧👇
写留言
本文分享自微信公众号 - 阿丸笔记(aone_note)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












