
事情还得从ChatGPT说起。
2022年12月OpenAI发布了自然语言生成模型ChatGPT,一个可以基于用户输入文本自动生成回答的人工智能体。它有着赶超人类的自然对话程度以及逆天的学识。一时间引爆了整个人工智能界,各大巨头也纷纷跟进发布了自家的大模型,如:百度-文心一言、科大讯飞-星火大模型、Meta-LLama等
那么到底多大的模型算大模型呢?截至目前仍没有明确的标准,但从目前各家所发布的模型来看,模型参数至少要在B(十亿)级别才能算作入门级大模型,理论上还可以更大,没有上限。以上只是个人理解,目前还没有人对大模型进行详细的定义。
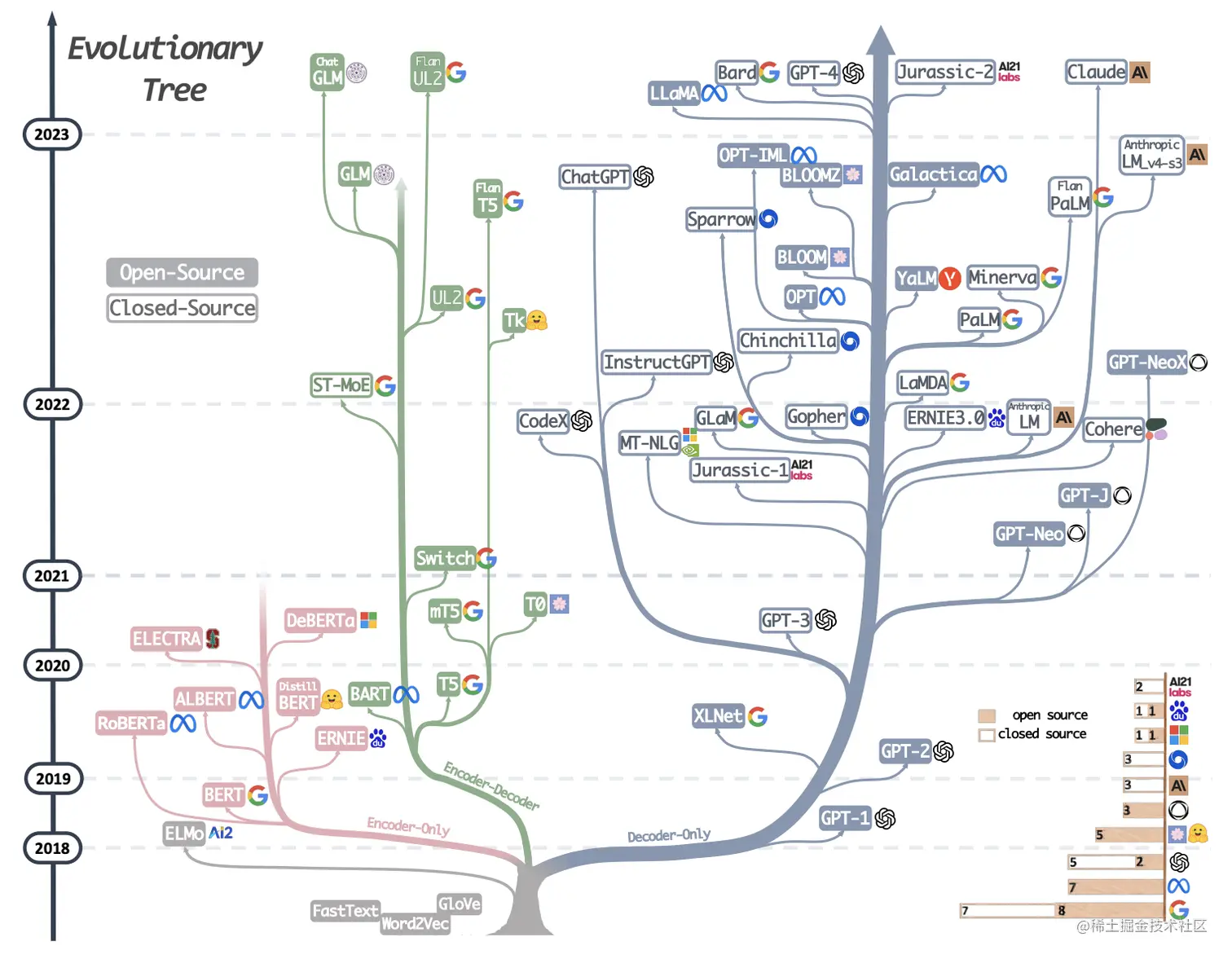
来一张图我们了解一下大模型的发展历程,从图中可以看到所谓大模型家族都有同一个根(elmo这一支除外)即Transformer,我们知道transformer由encoder-decoder两部分组成,encoder部分负责编码,更侧重于信息理解;而decoder部分负责解码,更侧重于文本生成;这样在模型选型方面就会有3种不同的选型,即:【only-encoder】这部分以大名鼎鼎的Bert为代表、【only-decoder】这部分的代表就是我们的当红炸子鸡GPT系列、【encoder-decoder】这部分相比于其他两个部分就显得略微暗淡一些,但同样也有一些相当不错的成果,其中尤以T5为代表。个人理解T5更像一个过渡产品,通过添加一些prefix或者prompt将几乎所有NLP任务都可以转换为Text-to-Text的任务,这样就使得原本仅适合encoder的任务(classification)也可以使用decoder的模式来处理。
图中时间节点可以看到是从2018年开始,2018年应该算是NLP领域的中兴之年,这一年诞生了大名鼎鼎的Bert(仅使用Transformer的Encoder部分),一举革了以RNN/LSTM/GRU等为代表的老牌编码器的命。Bert确立了一种新的范式,在Bert之前我们的模型是与任务强相关的,一个模型绑定一个任务,迁移性差。而Bert将NLP任务划分为预训练+微调的两阶段模式:预训练阶段使用大量的无标记数据训练一个Mask Language Model,而具体的下游任务只需要少量的数据在预训练的基础上微调即可。这样带来两个好处:(a)不需要针对专门的任务设计模型,只需要在预训练模型上稍作调整即可,迁移性好,真的方便。(b)效果是真的好,毕竟预训练学了那么多的知识。所以在接下来的几年内几乎所有的工作都是在围绕Bert来展看,又好用又有效果,谁能不爱呢?如下图就是Bert家族的明星们。
Transformer解决了哪些问题?
在没出现Transformer之前,NLP领域几乎都是以RNN模型为主导,RNN有两个比较明显的缺陷:(a)RNN模型是一个串行模型,只能一个时序一个时序的依次来处理信息,后一个时序需要依赖前一个时序的输出,这样就导致不能并行,时序越长性能越低同时也会造成一定的信息丢失。(b)RNN模型是一个单向模型,只能从左到右或者从右到左进行处理,无法实现真正的双向编码。

Transformer摒弃了RNN的顺序编码方式,完全使用注意力机制来对信息进行编码,如上图所示,Transformer的计算过程是完全并行的,可以同时计算所有时序的注意力得分。另外Transformer是真正的双向编码,如上图所示,在计算input#2的注意力得分时,input#2是可以同时看见input#1、input#3的且对于input#2而言input#1、input#3、甚至input#n都是同等距离的,没有所谓距离的概念,真正的天涯若比邻的感觉。
Tranformer的庐山真面目。
接下来我们从头更加深入的剖析一下Transformer结构,以及为什么大模型都要基于Transformer架构。以及在大模型时代我们都对Transformer做了哪些调整及修改。
同样来一张图,下面这张图就是我们Transformer的架构图,从图中可以看出,Transformer由左右两部分组成,左边这部分是Encoder,右边这部分就是Decoder了。Encoder负责对信息进行编码而Decoder则负责对信息解码 。下面我们从下往上对下图的每个部分进行解读。
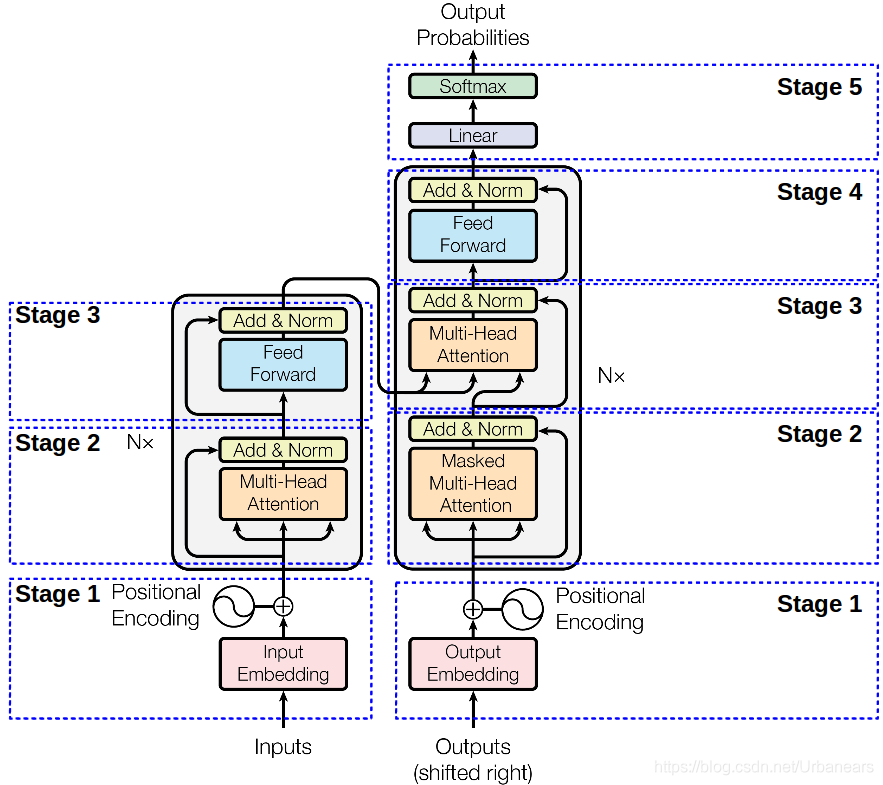
Stage-1部分就做两件事:对输入的文本进行编码、对文本位置进行编码。
Token Embedding
这部分主要是对文本进行编码,其核心部分为如何切分Token。典型的做法有Sentence Piece、Word Picece、BPE、甚至UniGram切词等。切词方式没有定数,个人理解切词的一个原则是:在能够覆盖到你的数据集的同时词汇表尽可能的小。故对切词方式不在赘述。下面啰嗦一下如何得到Token Embedding:

Positional Encoding
位置编码,前面我们有提到过在计算注意力的时候是没有所谓位置的概念的(见图-3),而对于任何一门语言,单词在句子中的位置以及排列顺序是非常重要的,它们不仅是一个句子的语法结构的组成部分,更是表达语义的重要概念。一个单词在句子的位置或排列顺序不同,可能整个句子的意思就发生了偏差,比如:”_我喜欢你_“和”你喜欢我“对于self attention来说可能会被处理为同一个意思,但真实意思却不尽相同。再比如下面这句话“_天上飞来一只鸟,它的头上插着一支旗子;地上躺着一只狗,它的颜色是黑色的。_”,当我们在计算”鸟“的注意力分值的时候,第一个“它”与第二个“它”理论上对“鸟”的贡献程度是不一样的,同样若没有位置信息则这两个”它“对于”鸟“来说就会有同样的贡献度,这显然是不合理的。为了消除上述这些问题,Transformer里引入了Position Encoding的概念。那么如何对位置进行编码?
用整数值编辑位置。一种很朴素的做法是按照token序列依次进行编码,即:0,1,2,3,……_n_。这种方式会有一些缺陷如:(a)无法处理更长的序列,外推性差。(b)模型的位置表示是无界的,随着序列长度的增加,位置值会越来越大。这种和Bert的可学习的编码方式原理一致,不再赘述。
用[0,1]范围标记位置。为了解决整数值带来的问题,我们可以考虑将范围编码限制在[0,1]之间,0表示第一个token,1表示最后一个token,然后按照token的多少平均划分[0,1]区间,这样一来我们的编码就是有界的。举个例子:当有3个token时位置信息就表示为
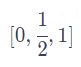
4个token时则表示为
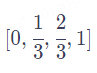
等以此类推。但这样同样会遇到一些问题,比如当序列长度不一样时,token之间的相对距离就会不同。比如当token数为3时,token之间的相对值为
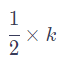
若token数为4时则相对值变为
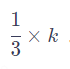

1.它能为每个时间步骤输出一个独一无二的编码,即编码是唯一且确定的;
2.在序列长度不同的情况下,不同序列中token的相对位置/距离也要保持一致;
3.模型应该能毫不费力地泛化到更长的句子,它的值应该是有界的;


大模型时代常用的位置编码方式。
大模型时代如何编码能够获得更好的外推性显得尤为重要,那么为什么要强调外推性?一个很现实的原因是在随着模型不断的变大,动辄几千张卡甚至几万张卡的计算资源就把绝大部分的从业者挡在了门外,而我们面临的问题也越来越复杂,输入越来越长。我们没办法根据不同的问题去调整模型,这样就需要一个全能的基座模型,它能够处理比训练长度更长的输入。以下面两种编码方式为代表。




具体操作流程如下图所示:
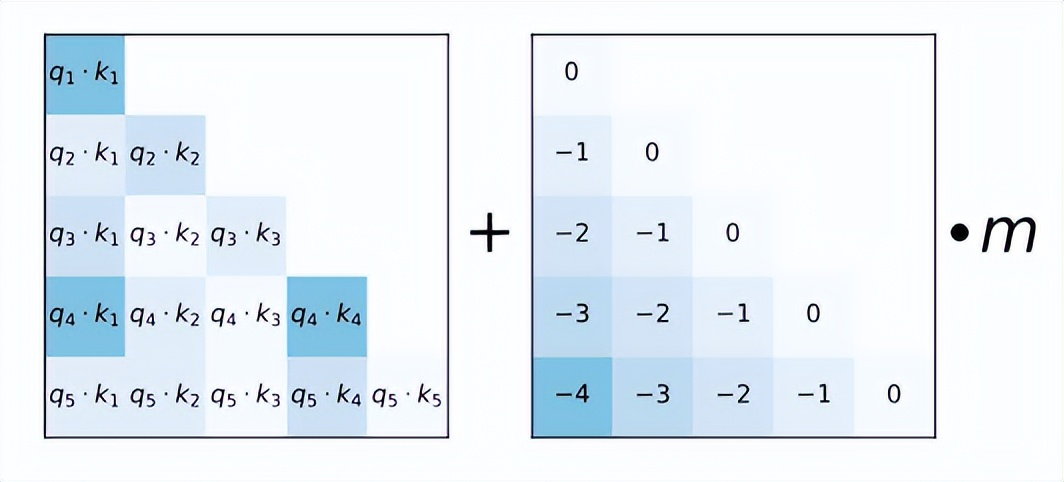
AliBi。AliBi的做法相较于正弦波或RoPE编码来的简单粗暴,与传统方法不同,ALiBi不会向token embedding中添加position embedding,取而代之的是直接将token的相对距离直接加到了AttentionScore矩阵上,比如_q_和_k_相对位置差 1 就加上一个 -1 的偏置,两个 token 距离越远这个负数就越大,代表他们的相互贡献越低。如下图,左侧的矩阵展示了每一对query-key的注意力得分,右侧的矩阵展示了每一对query-key之间的距离,m是固定的参数,每个注意头对应一个标量。原有注意力矩阵_A_,叠加了位置偏移矩阵_B_之后为 A+B×m
Attention注意力机制

公式-5就是Self Attention的核心,只要理解了这个公式也就理解了Transformer。
我们仔细看一下图-4中的Stage-2部分会发现Encoder和Decoder这部分是不太一样的,Encoder这部分叫做Multi Head Attention而Decoder部分叫做Masked Multi Head Attention。多了个Masked,先记下来后面我们来对这部分做解释。
在【那么为什么要提出Transformer架构?】部分我们讲到了,Transformer摒弃了RNN的顺序编码方式,采用了一种叫做注意力机制的方法来进行编码,那么什么是注意力机制?如下:
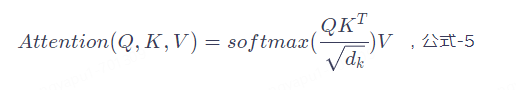
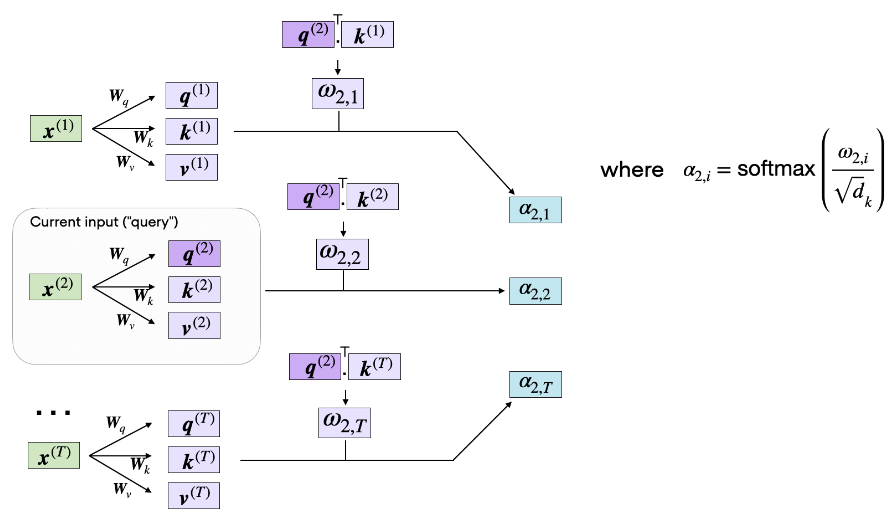
这个公式的输出就是注意力得分,怎么来理解这个式子,我们用一个例子来类比。想象一下我们在百度进行搜索的一个场景,_Q_就相当于我们在输入框输入的关键词,当我们输入关键词之后搜索引擎会根据我们的关键词与文档的相似度输出一个快照列表,_K_就是这个快照列表,每个文档与我们输入的关键词的相似度不同,所以排在第一个的是搜索引擎认为最重要的文档,打分就高,其他依次降序排列;然后你点进去阅读了这篇文章,那么这篇文章的内容我们就可以类比为_V_。这是一个搜索引擎的检索过程,而Attention的计算过程与搜索的过程几乎完全相同,我们结合下面这张图来详细的说明一下注意力的计算过程。


Multi Head Attention(MHA)
先来看一下Multi Head Attention的计算方法,很清晰是吧。前面说到的Attention就是在一个头里的计算,那么多头就是把这个计算多跑几次,分别得到每个头的输出,然后将所有的头输出进行连结,最后再乘一个矩阵_WO_将输出拉回到某个维度空间(Transformer里为512维),如下图有8个注意力头。


为什么要使用多头注意力?多头注意力机制提供了多个表示子空间,每个头独享不同得_Q_,K,_V_权重矩阵,这些权重矩阵每一个都是随机初始化,在训练之后,每个头都将输入投影到不同的表示空间,多个head学习得注意力侧重点可能略微不同,这样给了模型更大的容量。(可以想象一下CNN中不同的滤波器分别关注着不同的特征一样)。
这里说一下Multi Query Attention(MQA),这也是在一些大模型中使用的对MHA进行改造的手段,比如:Falcon、PaLM等。MQA就是在所有的注意力头上共享_K_,V,提升推理性能、减少显存占用。就这么简单。
残差链接、Norm、FFN、激活函数。
在深度神经网络中,当网络的深度增加时,模型过拟合以及梯度消失、爆炸的问题发生的概率也会随之增加,导致浅层网路参数无法更新,残差链接正是为了解决这些问题;Norm可以将每一层的输出通过归一化到符合某个分布,可以使模型更加稳定。常见的Norm的方法有BatchNorm、LayerNorm。NLP任务中由于输入长度不一致的问题一般都是用LayerNorm来做归一化。在大模型时代,很多模型都使用RMSNorm来替代LayerNorm,比如LLaMA、ChatGLM等,只不过大家在使用Norm的时候位置不同罢了。有些模型可能会将Norm放在残差之前(LLaMA)、有些可能会在残差之后(ChatGLM)、甚至Embedding之后甚至放在整个Transformer之后等,至于哪个效果好,仁者见仁。
下面是LayerNorm和RMSNorm的计算公式,RMSNorm想相较于LayerNorm去除了计算均值平移的部分,计算速度更快,且效果与LayerNorm相当。公式如下所示。

激活函数如果非要提的话那就提一下SwiGLU,在很多大模型中都有用到,比如LLaMA2、ChatGLM2等,扔个公式,体会一下。

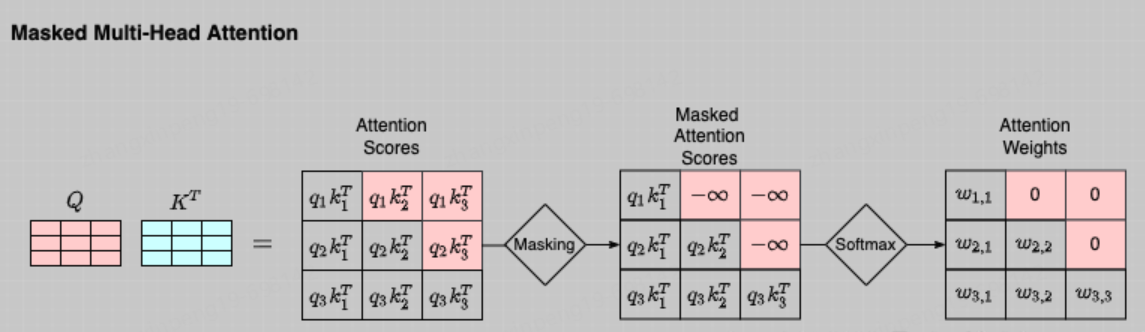
至此我们几乎已经聊完了Transformer的核心部分。图-4中Stage-2(左)部分与Stage-3(右)完全相同,Stage-3(左)与Stage-4(右)完全相同,Stage-2(右)部分几乎与Stage-2(左)部分完全相同,只不过右侧部分的Attention需要掩码,这是因为右侧是一个Decoder的过程,而Decoder是一个从左到右的自回归的过程,想象一下我们在写下一句话【今天的天很蓝】,你是从左到右依次写出的这几个字,当你在写“今”的时候这时候还没“天”所以“天”这个位置对于“今”这个位置的注意力应该为0,以此类推。这时候就要对t+1时刻做掩码。即计算t时刻的注意力分值的时候将t+1时刻对t时刻的注意力设为0即可。如下图所示,将查询矩阵的上三角设置为一个极小值即可,不再赘述。
接下来说一下在大模型时代我们对Attention部分有哪些改造。常见的改造方法即Flash Attention
Flash Attention。
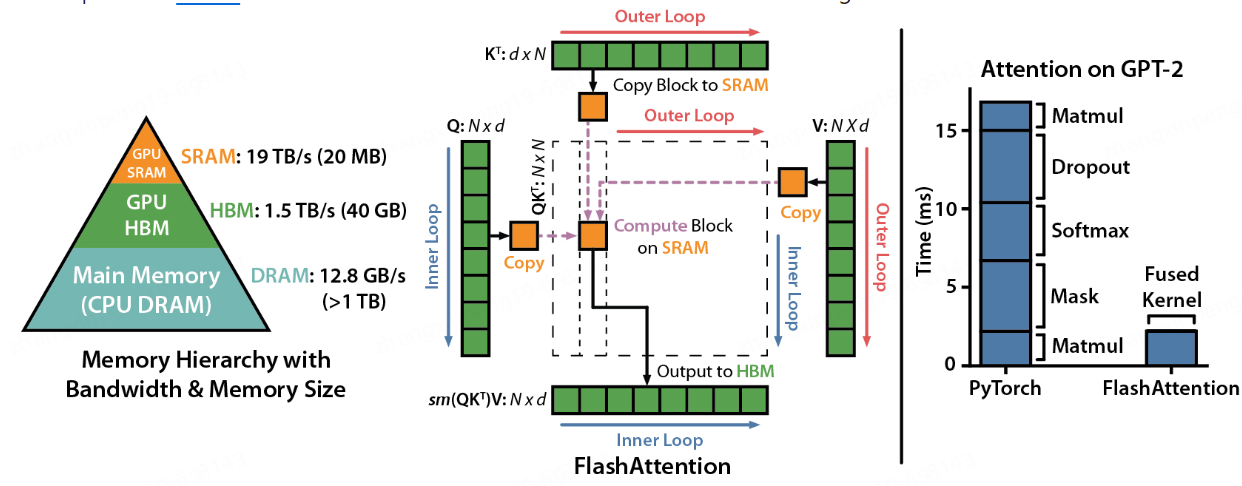




3.依次迭代,直至计算完毕。因整个计算全部在GPU SRAM中进行仅有个别中间值的保存需要与HBM进行交互,减少了与HBM的交互,提升计算性能。
预训练及微调方法
介绍完了Transformer的原理以及大模型时代针对于Transformer的每个组件都做了哪些修改。接下来我们聊一下如何训练以及如何微调大模型。
前面我们说到Bert时代将所有的NLP任务统一划分为了预训练+微调两阶段,预训练负责从大量无标记的数据中学习语言特征,微调使用有标记的数据调整模型适应具体的下游任务。这个模式同样适用于大模型。
预训练。市面上绝大部分的大模型都是only-decoder的自回归模型,即用前n个token预测第n+1个token的值得概率。这是一个语言模型,不再赘述。但也有比较特殊的,比如ChatGLM,如下图,它既有Encoder部分也有Decoder部分。稍微复杂一点,首先它会在输入中随机Mask一些span,然后将Mask后的span随机的拼接在原始输入的后边。训练的时候分两步:(1)对[S]后进行续写,这部分是个Decoder的部分,单向的。(2)对Mask掉的部分进行预测,使用第(1)步的生成结果进行调整。从而使模型达到收敛。
总之预训练的任务就是从大量无标号得数据中学习到某些知识,因为是很自然得语言模型,所以不需要人工打标,只要能收集到大量得文本数据就可以训练,前提是算力够,理论上预训练得数据越多越好。大模型时代几乎都是几十亿token的数据。

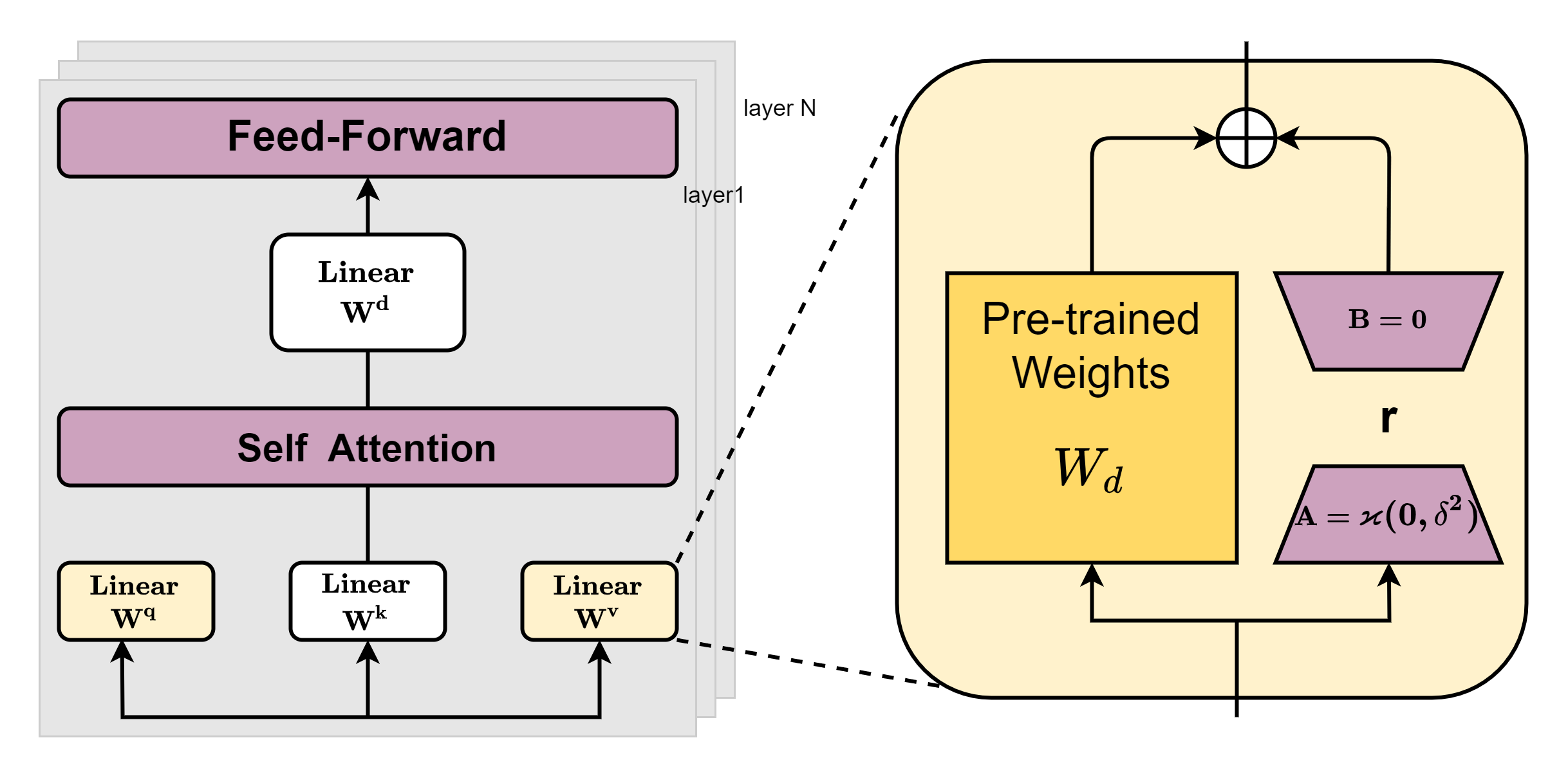
微调(Fine Tuning)。微调是为了适应具体得下游任务,使用特定的有标记的数据集对模型进行进一步调整从而往模型中注入某些知识的手段。如果你有足够的资源全参数微调是个不错的选择,它可以更加充分的学习到你的特定数据的特性,理论上效果应该是最好的。但大模型动辄几十个G,训练起来存储至少还要再翻一倍,非常耗费资源。那么有没有别的方法也能往模型中注入特定域的知识呢?还是有一些方法的,既然全参数跑不动那么我们就调整部分参数,这就是参数高效微调(Parameter-Efficient Fine-Tuning)这一类方法的思想。下面我们说一些几种参数高效微调的方法。
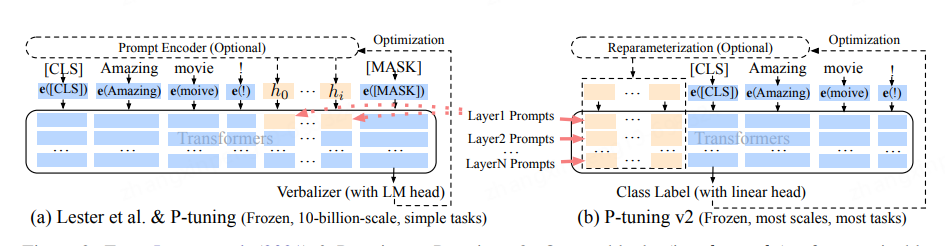
P-Tuning。这是一类方法(prompt tuning、prefix tuning、p-tuning、p-tuning v2),虽然实现不同但思路大同小异,至于那个名字对应到那个方法我也记不清,所以这块我们把这些放在一块来说。p-tuning这一类方法的做法是在模型原有结构上增加一部分参数,比如:在原输入上硬编码增加一些提示词、在原始Embedding前面拼接上一些可训练的张量等。当然这些张量的生成上也有不同,有些是跟模型一起训练的、有些是专门针对这部分搞个编码器;其次拼接位置也有所不同,有的是拼接在Embedding上,有的可能每个层都拼接。总之就是搞了一部分可学习的参数然后放在模型里面一起训练,只更新这部分参数的权重,从而达到往模型中注入知识的目的。来张图体验一下。这一类的方法的缺陷是会占用原有模型的一部分空间,这样可能会降低原有模型能够处理的文本长度的上限。
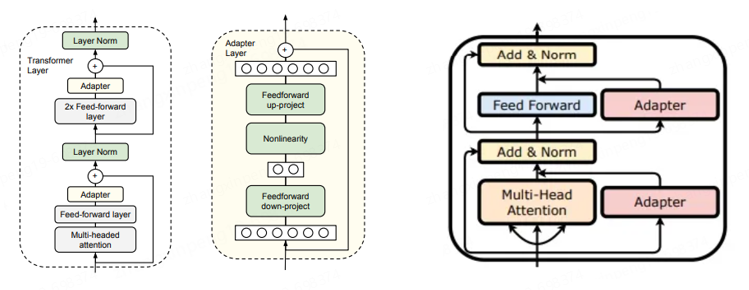
Adapter。Adapter的做法是在预训练模型的某些层中间添加Adapter块(如下图中间部分所示),微调的时候主体模型冻结,只更新Adapter块的权重,由Adapter块学习特定的下游任务。每个Adapter由两个前馈层组成,第一个前馈层将输入从原始维度投影到一个相对较小的维度,然后再经过一层非线性转换,第二个前馈层再还原到原始输入维度,作为Adapter的输出,与预训练其他模型进行连接。与前面提到的P-Tuning系列不同,P-Tuning是在预训练模型的某些层上增加一些可训练的参数,而Adapter是在预训练模型的层之间添加可训练参数。一个更形象的说法P-Tuning使模型变胖了(实际上是压缩了一部分原有空间),Adapter使模型变高了。Adapter的插入可以分为串行和并行两种,如下图左右两图所示,很好理解。

训练方式。
最后我们再聊一下在现有算力下如何训练一个大模型。大模型训练是一个复杂的任务,随着模型和数据规模的增大意味着训练时间的增长。 传统的单卡训练几乎无法来完成这个事情,于是就要借助于分布式训练来大规模的训练模型。分布式的思想其实也很简单,总结一句话就是:化繁为简、化整为零。将整个训练拆解到不同的卡上,各卡之间协作来完成训练。那么如何来拆解整个训练过程?大提升可以分为以下几种:
数据并行:所谓数据并行就是将样本数据切分成不同的更小的输入,每张卡只需要处理更小的一部分数据,最终在合并计算梯度,然后将梯度分别更新到每个节点上。数据并行的前提是单卡能够吃得下整个模型。
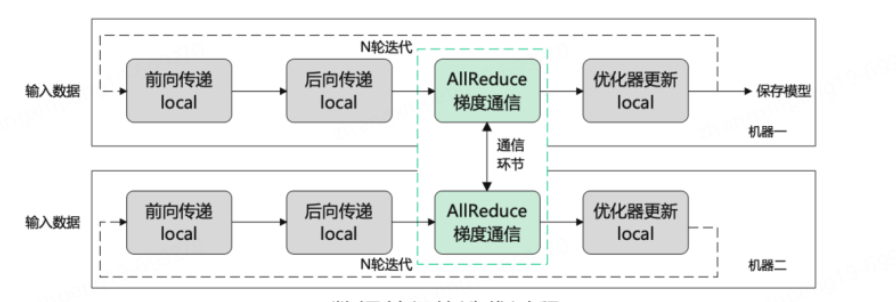
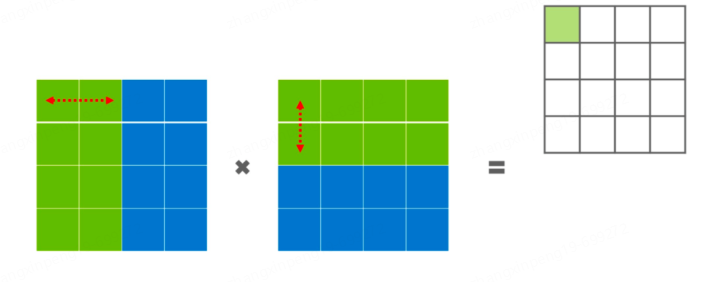
模型并行:模型并行可细分为流水线并行和张量并行。流水线并行是将模型的不同层分发到不同的机器上,每个机器负责某些层的计算。比如:03层由gpu0来处理、48层由gpu1来处理等最终再汇总计算梯度进行更新。张量并行相对于流水线并行切分的更细,流水线并行是对层进行切分,但每个层仍然是完整的分在一张卡上,而张量并行是对层内进行切分,将一个层切分为由多个张量组成的部分,每个张量由不同的机器进行运算。如下图所示,可能绿色部分在一张卡上,蓝色部分在另一张卡上进行计算。
在模型训练这块也有很多现成的框架以供使用,如:DeepSpeed、Megatron-LM等,本次介绍主要已模型框架及原理为主,相关训练框架不在本次介绍范围之内,后续我们再针对训练框架做一些专门的介绍。
总结:
本文对大模型从原理及结构上做了简单的介绍,希望能给各位在了解大模型的路上提供一些帮助。个人经验有限,说的不对的地方还请及时提出宝贵的意见,也可以联系本人线下讨论。下期会结合我们在财富领域训练大模型的经验写一篇偏实践的文章出来。
参考文献:
1.Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
2.Fast Transformer Decoding: One Write-Head is All You Need
3.GLU Variants Improve Transformer
4.GAUSSIAN ERROR LINEAR UNITS (GELUs)
5.Root Mean Square Layer Normalization
6.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
7.Language Models are Few-Shot Learners
8.Attention Is All You Need
9.TRAIN SHORT, TEST LONG: ATTENTION WITH LINEAR BIASES ENABLES INPUT LENGTH EXTRAPOLATION
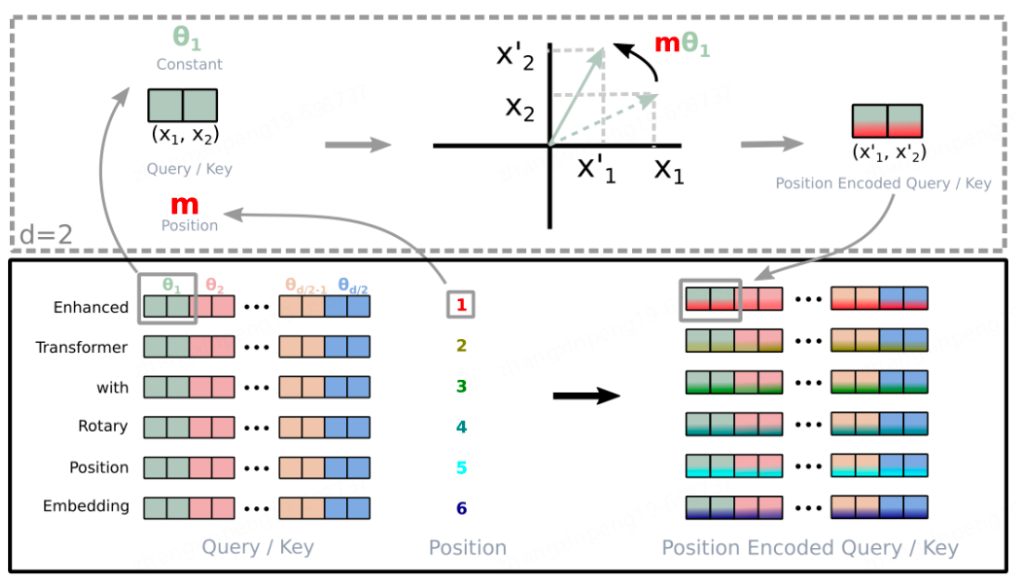
10.ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING
11.GLM: General Language Model Pretraining with Autoregressive Blank Infilling
12.FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
13.Parameter-Efficient Transfer Learning for NLP
14.The Power of Scale for Parameter-Efficient Prompt Tuning
15.Prefix-Tuning: Optimizing Continuous Prompts for Generation
16.P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
17.LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
18.Training language models to follow instructions with human feedback
19.https://spaces.ac.cn/archives/8265
作者:京东科技 张新朋
来源:京东云开发者社区 转载请注明来源




