
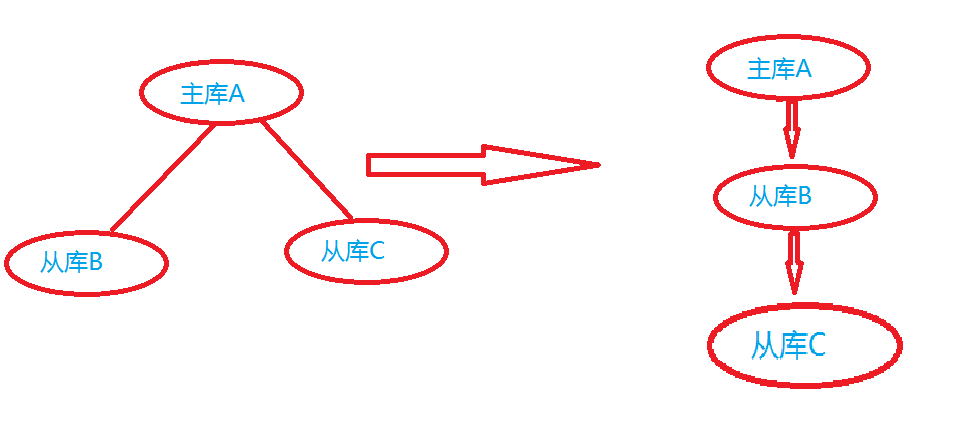
因为最近公司服务器要迁移;原来的数据库架构是一主一从的架构(主库A---从库C);增加多一台从库服务器B。
现在要把从库B替换主库A;从库C继续作为B的从库。
一主2从简单说一下步骤;具体步骤省略。
首先搭建好从库B,配置好my.cnf 的server_id
1,先停掉从库C.stop slave
2,记住从库C的同步状态。 show slave status\G 记住Master_Log_File 和Read_Master_Log_Pos 的位置和点。
3,备份从库C,备份完成后导入从库B。
4,主库A授权用户从库B。
5,从库B change master 做主从复制。(用从库C的 位置和点)
以上操作完成后,现在的架构是 一主两从的架构;现在要把从库B升级为从库c的主库变为级联架构。
首先从库B要开启二进制日志。并且还要加上参数 log_slave_updates = 1 在授权一个复制用的帐号给从库C。
当从库log_slave_updates参数没有开启时,从库的binlog不会记录来源于主库的操作记录。只有开启log_slave_updates,从库binlog才会记录主库同步的操作日志。
先在从库C上执行STOP SLAVE。show slave status \G查看从库C复制主库A的位置Exec_Master_Log_Pos。
在从库B上执行show slave status \G;查看从库B上的Exec_Master_Log_Pos是否已经大于从库C上的Exec_Master_Log_Pos,如果大于,则执行stop slave停掉从库B的复制,这时需要记下从库B上的 Relay_Master_Log_File: tex-bin.003882 ,Exec_Master_Log_Pos: 322474479 两个值,在从库B上执行show master status,记下BINLOG文件名字File(B)以及位置Position(B),然后start slave开启复制。
在从库C上执行start slave until master_log_file='tex-bin.003882',master_log_pos=322474479; 让从库C复制到从库B的位置。 show slave status \G 查看从库C上的Until_Log_Pos与Exec_Master_Log_Pos是否相等,如果相等则stop slave关闭复制。然后把从库C的主库指向从库B,change master to
master_host='B_ip',
master_port=3306,
master_user='rep',
master_password='xxxx',
master_log_file=File(B),
master_log_pos=Position(B),
master_connect_retry=3;
然后start slave开启复制。OK,结束了,就是这样!












