
一、背景介绍
传统的电商平台通常依靠人工拍摄和编辑产品图片,这需要大量的时间和资源。AI数字模特可以根据需要调整模特的外貌、体型和风格。这样,电商平台可以快速、高效地生成大量的产品展示图片,同时可以根据消费者的需求和喜好进行个性化定制。
1.1 初始想法
最初我们主要聚焦到两个具体的业务场景:
•人台图或真人图生成真人模特图,适用于服装商家、批发商,需要进行服装商拍的场景

•基于真人模特进行换装、场景和姿态等,适用于服装品牌商、出海商家,用于产品展示的场景

1.2 市场初步调研
SD、MJ卷起新一轮AI绘画的浪潮之后,有很多创新型公司尤其是电商相关,都开始尝试这个赛道(在SD、MJ之前,已经有数字/虚拟/电商模特相关赛道的公司,但是由于技术限制实现效果不太理想,类比于ChatGPT之前和之后的智能聊天机器人的差别),以下是AI模特相关的一些市场案例,可见其火爆程度:
•阿里妈妈80位AI模特天团首次出道,助力品牌AI上新货品,商家朋友快来pick!
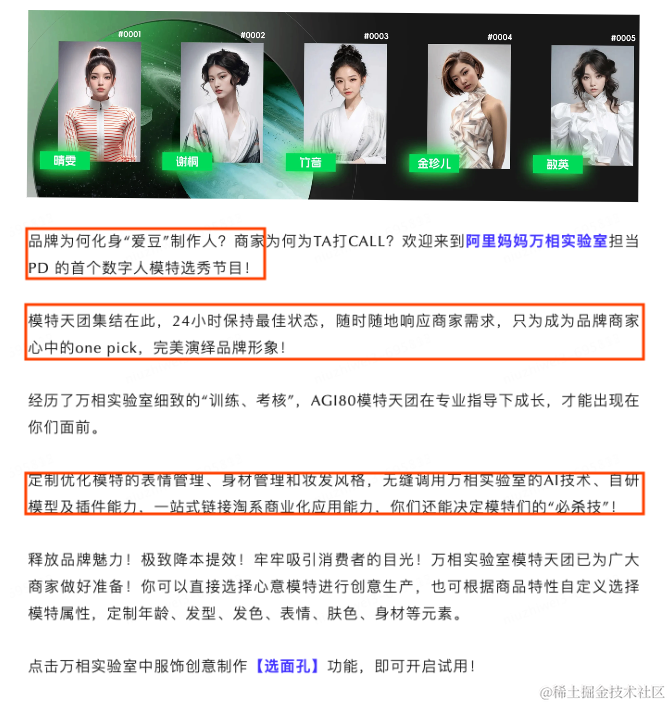
•AI模特进军时尚摄影,Levi 等大品牌已开始广泛采用

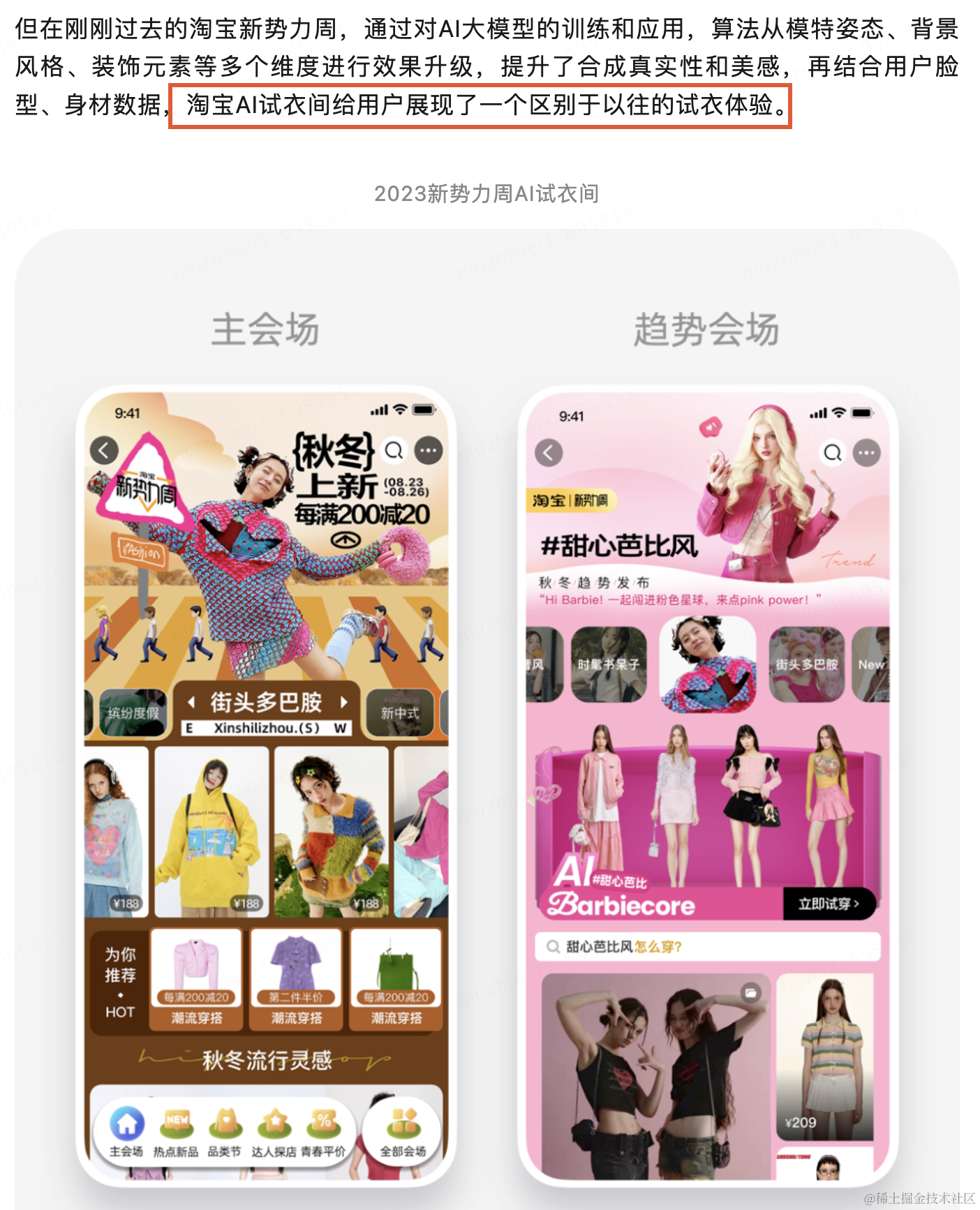
二、实现过程
2.0 关键路径探索
前期我们主要使用Stable Diffusion Web UI,分别调研了
•不同CHECKPOINT、LORA模型下生成稳定形象或风格的正向提示词以及负向提示词
•借助sd-webui-inpaint-anything插件能力,对图像进行分割,并生成对应部位的蒙版mask
•使用SD图生图功能,结合生成的蒙版图,观察生成的最终效果。通过调试各个不同的参数,生成的效果依然不理想,最后结合ControlNet插件能力,才算生成比较稳定的最终效果。
经过上千次的尝试,主要路径走通后,我们分别通过三方面来落地实现:
1.前端界面原型设计和实现
2.服务端实现
3.Lora模型训练方向
2.1 前端设计与实现
2.1.1 原型设计
原型设计通过一个形象的界面展示,可以在项目初期,帮助团队成员更好地理解和验证设计概念,让团队成员之间的目标快速达成一致。
初期我们使用了Webflow进行高保真的原型设计。Webflow可以像写样式一样配置相关的属性比如Flex布局、盒子模型等;可以自定义样式名和组件;同时也可以一键部署到外网。
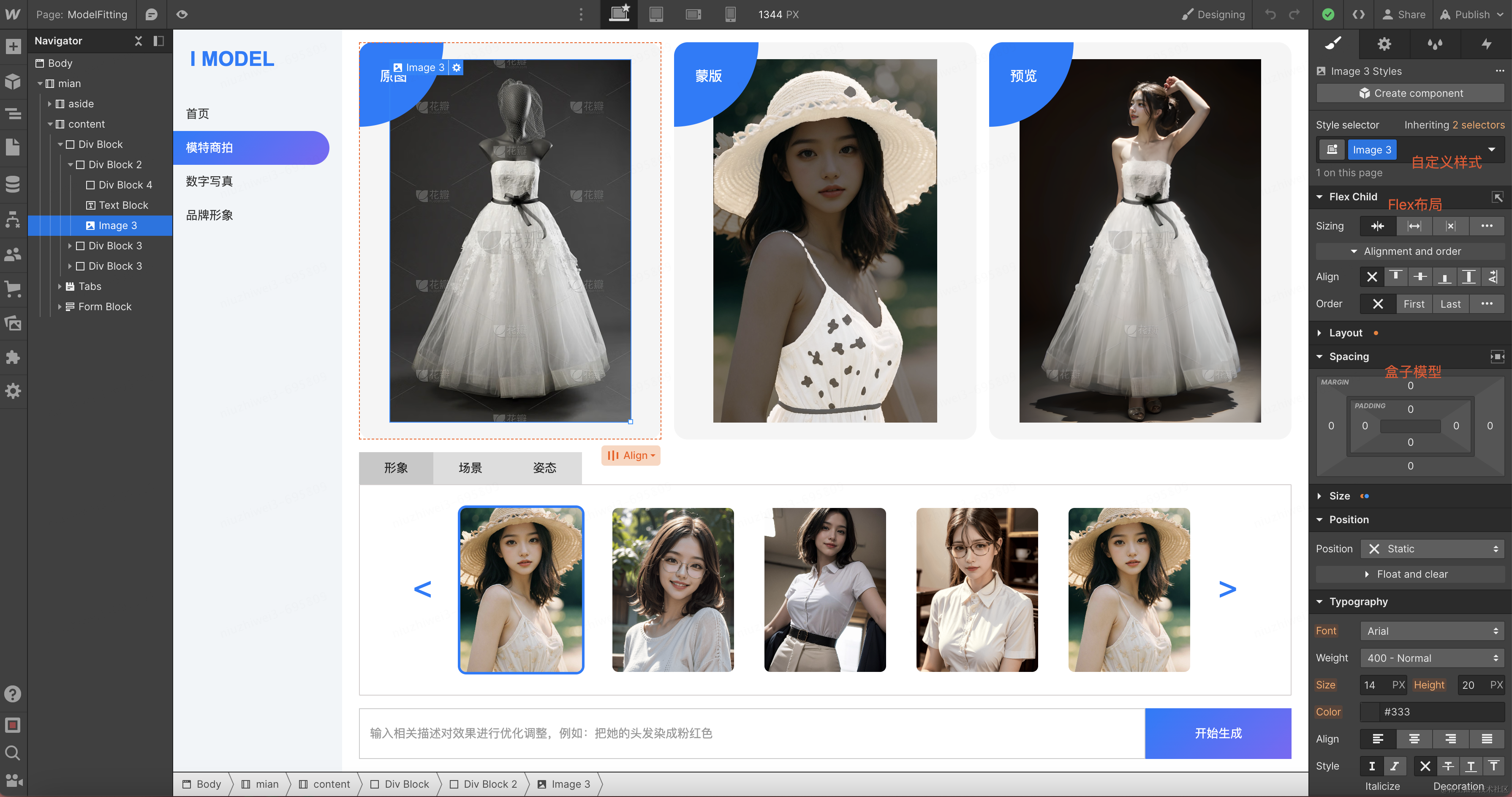
一键部署后自动生成外网可访问的域名:https://imodel.webflow.io/
2.1.2 项目架构思路
前端主要基于Astro岛屿架构,Astro是一个现代化的前端岛屿架构框架,具有很高的灵活性和可扩展性。在Astro中,你可以使用任何被支持的UI框架(比如 React, Svelte, Vue)来在浏览器中呈现群岛。你可以在一个页面中混合或拼接许多不同的框架,或者仅仅使用自己最喜欢的。同时支持SSG(静态站点生成)、SSR(服务端渲染)、CSR(客户端渲染)等不同类型的混合渲染方式;
主要设计思路如下:

•页面中和用户无交互或弱交互的地方(比如左侧菜单、布局组件等)使用Astro+SSR实现。Astro可以生成静态页面(利于SEO),同时支持服务端渲染(SSR),大幅提升页面加载性能。
•页面中和用户强交互的地方使用SolidJS+CSR实现,与其他流行的前端框架(如React和Vue.js)相比,SolidJS在性能方面表现出色,并且具有更小的体积。它的设计理念和使用方式也与传统的模板引擎有所不同,更加注重函数式编程和响应式思想。如果你追求极致的性能和灵活性,并且喜欢函数式编程的方式,那么SolidJS可能是一个很好的选择。
•当然如果你的组件是基于Vue或者React框架,也可以无缝集成到Astro项目中。
此外,我们还引入了UnoCSS,UnoCSS是一个基于CSS的轻量级框架,它旨在简化和加速前端开发过程。UnoCSS使用简单的CSS类来定义样式和布局,无需编写大量的CSS代码。只需将所需的类应用于HTML元素即可实现相应的效果。
2.1.3 状态共享方案
Astro推荐使用 Nano Stores 共享组件之间的状态,主要原因有:
•轻量级:Nano Stores 提供了你所需要的最低限度的 JS(不到 1KB),并且零依赖。
•框架无关:这意味着在框架之间(React\RN\Vue\SolidJS等)共享状态将是无缝的!Astro 是建立在灵活性之上的,所以我们喜欢那些无论你的偏好如何都能提供类似开发者体验的解决方案。
但是本项目中,只有在SolidJS组件中有状态交互,因此使用了Solid内置的状态方案Solid signals,如果后期涉及到跨框架交互,会引入Nano Stores方案。
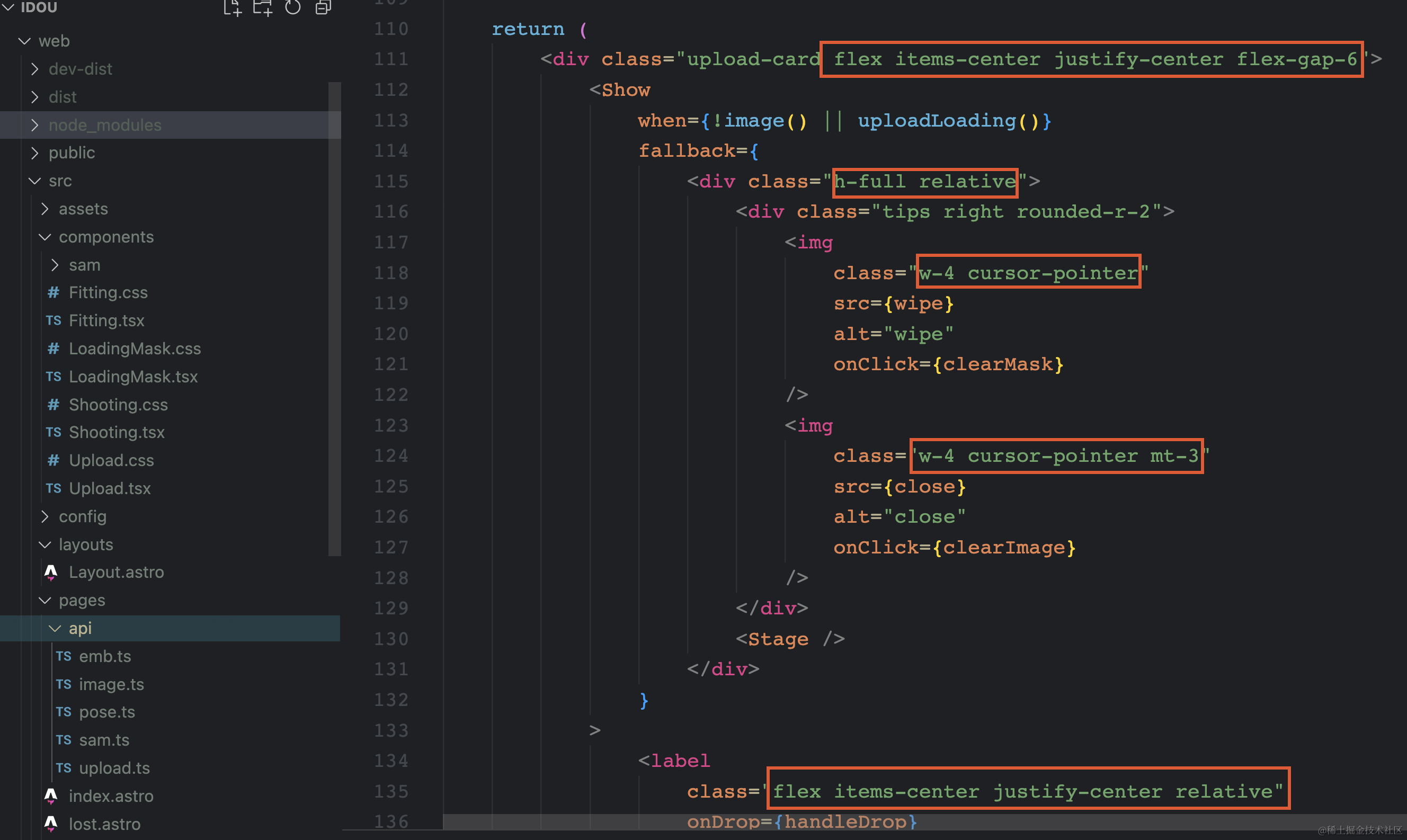
2.1.4 服务器端点(API 路由)
我们开启了服务端渲染模式,API端点请求时将在Node或Deno层构建,因此不需要设置proxy代理,也不会产生跨域问题。自定义API端点需要遵守Astro的约定,在page目录下添加.js或.ts文件(与Next类似)
定义upload接口:page/api/upload.ts
import type { APIRoute } from 'astro';
import { BASE_URL } from '~/config';
export const post: APIRoute = async (context) => {
try {
const body = await context.request.json();
const { input_image } = body as {
input_image: string;
};
if (!BASE_URL) {
throw new Error('请设置API_BASE_URL');
}
const res = await fetch(`https://${BASE_URL}/sam/upload`, {
headers: {
'Content-Type': 'application/json',
},
method: 'POST',
body: JSON.stringify({
input_image,
}),
}).catch((err) => {
return new Response(
JSON.stringify({
error: {
message: err.message,
},
}),
{ status: 500 },
);
});
if (!res.ok) {
return new Response(res.body, {
status: res.status,
statusText: res.statusText,
});
}
return new Response(res.body);
} catch (err) {
return new Response(
JSON.stringify({
error: {
message: err.message,
},
}),
{ status: 400 },
);
}
};在页面中使用:
...
const response = await fetch('/api/upload', {
method: 'POST',
body: JSON.stringify({
input_image: image().src,
}),
});
...2.1.5 项目部署
最开始我们使用了Vercel平台进行部署,使用步骤非常简单而且免费,同时支持Serverless Functions(无服务部署)和Edge Functions(边缘函数部署)。主要步骤:
1.Gihub仓库授权,一键导入对应项目的代码仓库
2.设置环境变量以及构建启动命令等,一键部署
3.部署完成后,会自动生成几个.app后缀的域名,可惜.app域名国内无法访问
4.自己申请一个域名,并将DNS解析到Vercel(注意:生效时间有延迟,一般要等10分钟以上才生效)
5.在Vercel平台进行自定义域名配置
但是在访问线上页面时,发现调用接口时都报超时的错误,查阅官方文档发现平台代理请求超时时间限制为10s(现在为30s),解决方案是接口改造为支持流式传输数据,比如使用Web Streams API或Remix流式传输,由于改动较大,不得选择其他部署平台。
最后我们选择了Deno平台进部署项目,Deno Deploy结合Github Actions中的workflow,可以实现项目的一键部署,主要步骤:
1.部署配置文件deploy.yml编写
name: Idou Deploy
on: [pull_request, push, workflow_dispatch] # 触发部署的方式
defaults:
run:
working-directory: web # 根目录设置
jobs:
deploy:
name: Deploy
runs-on: ubuntu-latest
permissions:
id-token: write # 用于 Deno Deploy 身份认证
contents: read # 用于克隆仓库
steps:
- name: Clone repository
uses: actions/checkout@v3
- name: Install pnpm # 使用pnpm需要先安装
run: npm install -g pnpm
# 没有使用 npm?请将 `npm ci` 修改为 `yarn install` 或 `pnpm i`
- name: Install dependencies
run: pnpm i
# 没有使用 npm?请将 `npm run build` 修改为 `yarn build` 或 `pnpm run build`
- name: Build Astro
run: pnpm run build
- name: Upload to Deno Deploy
uses: denoland/deployctl@v1
with:
project: idou # Deno Deploy 项目的名称
entrypoint: server/entry.mjs # 入口文件
root: web/dist1.Gihub仓库授权,一键导入对应项目的代码仓库
2.部署完成后,会自动生成[项目名].deno.dev域名,可以直接访问
2.2 服务端实现
Stable Diffusion通过FastAPI的方式提供API接口,通过配合源码查看每个参数代表的含义。通过云端服务器-> 内网穿透 -> API形式运行SD -> 前端发送API请求的Pipeline进行前后端交互。
以下是图像全分割服务中一个实现将图片生成image embedding的方法,并提供给前端API接口调用:
...
def sam_upload(input_image):
print("Start SAM convert Processing")
sam_model_name = "sam_vit_h_4b8939.pth"
if sam_model_name is None:
return [], "SAM model not found. Please download SAM model from extension README."
if input_image is None:
return [], "SAM requires an input image. Please upload an image first."
image_np = np.array(input_image)
image_np_rgb = image_np[..., :3]
sam = init_sam_model(sam_model_name)
print(f"Running SAM Inference {image_np_rgb.shape}")
predictor = SamPredictorHQ(sam, 'hq' in sam_model_name)
predictor.set_image(image_np_rgb)
image_embedding = predictor.get_image_embedding().cpu().numpy()
np.save("/root/stable-diffusion-webui/outputs/uploadFile/output.npy", image_embedding)
return {"path":"/root/stable-diffusion-webui/outputs/uploadFile"}
...
@app.post("/sam/upload")
async def api_sam_upload(payload: SamUploadRequest = Body(...)) -> Any:
print(f"SAM upload /sam/upload received request")
payload.input_image = decode_to_pil(payload.input_image).convert('RGBA')
path = sam_upload(payload.input_image)
return path2.2.1 文生图接口
接口名:/sdapi/v1/txt2img
常用参数含义
| 参数名 | 类型 | 代表含义 |
|---|---|---|
| prompt | string | 正向提示词 |
| negative_prompt | string | 反向提示词 |
| seed | int | 随机种子 |
| batch_size | int | 每次生成的图片数量 |
| n_iter | int | 生成批次 |
| steps | int | 生成步数 |
| cfg_scale | int | 关键词相关性 |
| width | int | 宽度 |
| height | int | 高度 |
| restore_faces | boolean | 脸部修复 |
| override_settings | object | 本次生成图片的底模 |
| script_args | array | 一般用于lora模型或者其他插件阐述 |
| sampler_index | string | 采样方法 |
2.2.2 图生图接口
接口名:/sdapi/v1/img2img
常用参数含义
| 参数名 | 类型 | 代表含义 |
|---|---|---|
| prompt | string | 正向提示词 |
| negative_prompt | string | 反向提示词 |
| seed | int | 随机种子 |
| batch_size | int | 每次生成的图片数量 |
| n_iter | int | 生成批次 |
| steps | int | 生成步数 |
| cfg_scale | int | 关键词相关性 |
| width | int | 宽度 |
| height | int | 高度 |
| restore_faces | boolean | 脸部修复 |
| override_settings | object | 本次生成图片的底模 |
| script_args | list | 一般用于lora模型或者其他插件阐述 |
| sampler_index | string | 采样方法 |
| init_images | string | 输入图片,base64格式 |
| mask | string | 蒙版区域,base64格式 |
| denoising_strength | float | 重绘幅度 |
| inpainting_fill | int | 蒙版遮住的内容,0 填充 1原图 2 空间噪声 3空间数值0 |
| inpainting_mask_invert | int | 蒙版模式 0重绘蒙版内容 1 重绘非蒙版内容 |
| alwayson_scripts | dict | 存放controlNet相关插件参数 |
2.2.1 sam分割接口
接口名:/sam/sam-predict
传参含义
| 参数名 | 类型 | 代表含义 |
|---|---|---|
| sam_model_name | string | 选用的sam模型名称 |
| sam_positive_points | string | 需要分割的图片,base64格式 |
| sam_positive_points | list | 需要分割的坐标区域 |
| sam_negative_points | int | 不希望分割的坐标区域,一般不传 |
2.3 Lora模型训练(联合作者:曹倚宾)
在这次比赛里,由于时间关系,我们使用了秋叶大神的初版”炼丹炉“——一个集成了各种用于模型训练的组件的工作台,来训练我们的衣服品类的Lora模型。训练Lora模型跟训练其他模型的大体步骤基本一样,主要步骤都是:准备训练集 -> 打标签 -> 模型参数调整 -> 模型训练 -> 测试评估 -> 模型迭代。
2.3.1 准备训练集
我们使用的是一组马面裙模特图片,总共七张图片,特点都是背景简单,穿衣姿态较好分辨,至少要包含正面、背面、侧面等主要不同方位的图片,不同姿态或方位的图片越多,生成的最终效果越好。
2.3.2 打标签
由于七张图片里有两张是双人图,因此为了不影响后续模型训练,我们将这两张图片拆分成四张图片,达到我们要训练的每张图片都有且仅有一种服饰和姿态,然后我们开始给每张图片进行打标,我们先通过集成的打标插件统一给每张图片生成相应的txt文档,然后依据每个图片的服饰细节进行精细化关建词标注,最后检查图片大小。虽然原则上最好控制每张图片大小一样,但是由于图片拍照角度问题,为了尽量展示细节让模型学习到位,因此在本次Lora训练中并没有严格控制图片大小,而是选择将大小控制在一定范围内。
2.3.3 模型参数调整
这一部分我们主要根据网上的建议,从专栏文章到各路大神发表的调参实验结果,为了训练效率,最后快速挑选了符合我们硬件配置的参数进行模型训练。
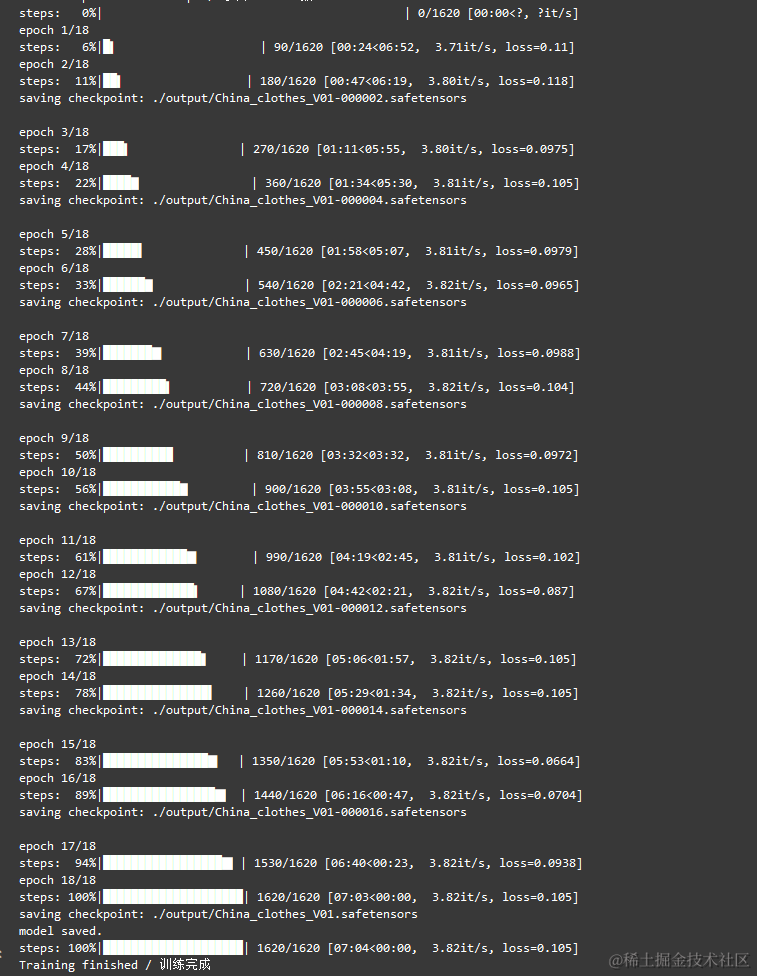
2.3.4 模型训练
模型训练过程如下图所示
2.3.5 测试评估
这一块由于当时比赛时间紧迫,就没有来得及做严格的模型测试评估,不过我们也根据经验选用了LOSS值在0.07及其以下的模型作为最终Lora模型。

2.3.6 模型迭代
这一块虽然当时也没来得及做,但后续我们的项目还会继续,关于为商家训练效果更好的Lora模型,我们会不断地调试参数,并启用SD里的XYZ plot脚本,用不同的权重来生成一系列图进行对比测试,以此来找到最好的能够生成商家服装的Lora模型。
2.4 整体技术路线(联合作者:苟晓攀)
通过局部重绘生成效果更加逼真,保留商品细节具备接近真实图片的观感,进行多样化场景、姿态、风格的模特展示。

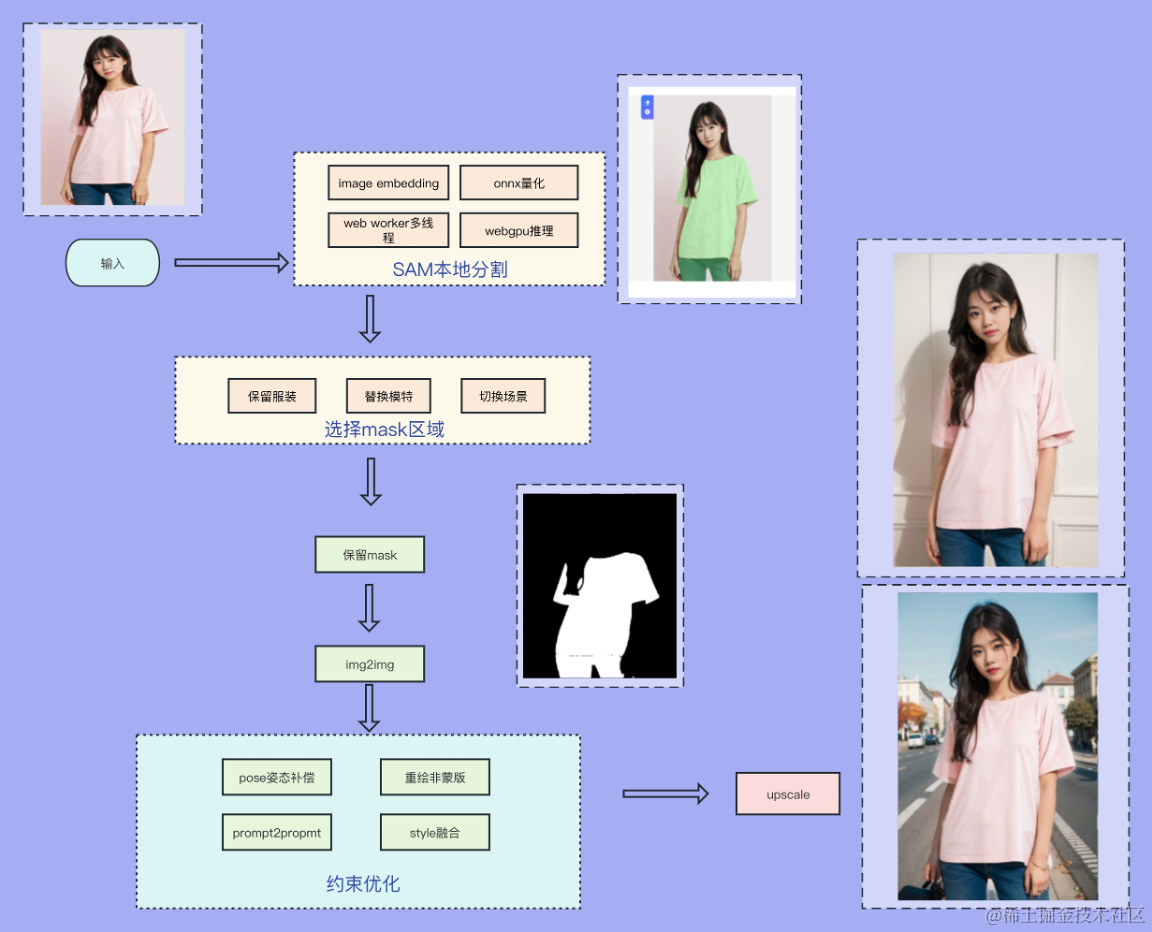
2.4.1 模特商拍
通过真人模特、人台图到真人模特等功能,完成多种场景的切换展示,通过自研的姿态补全算法进行半身人台的补全。
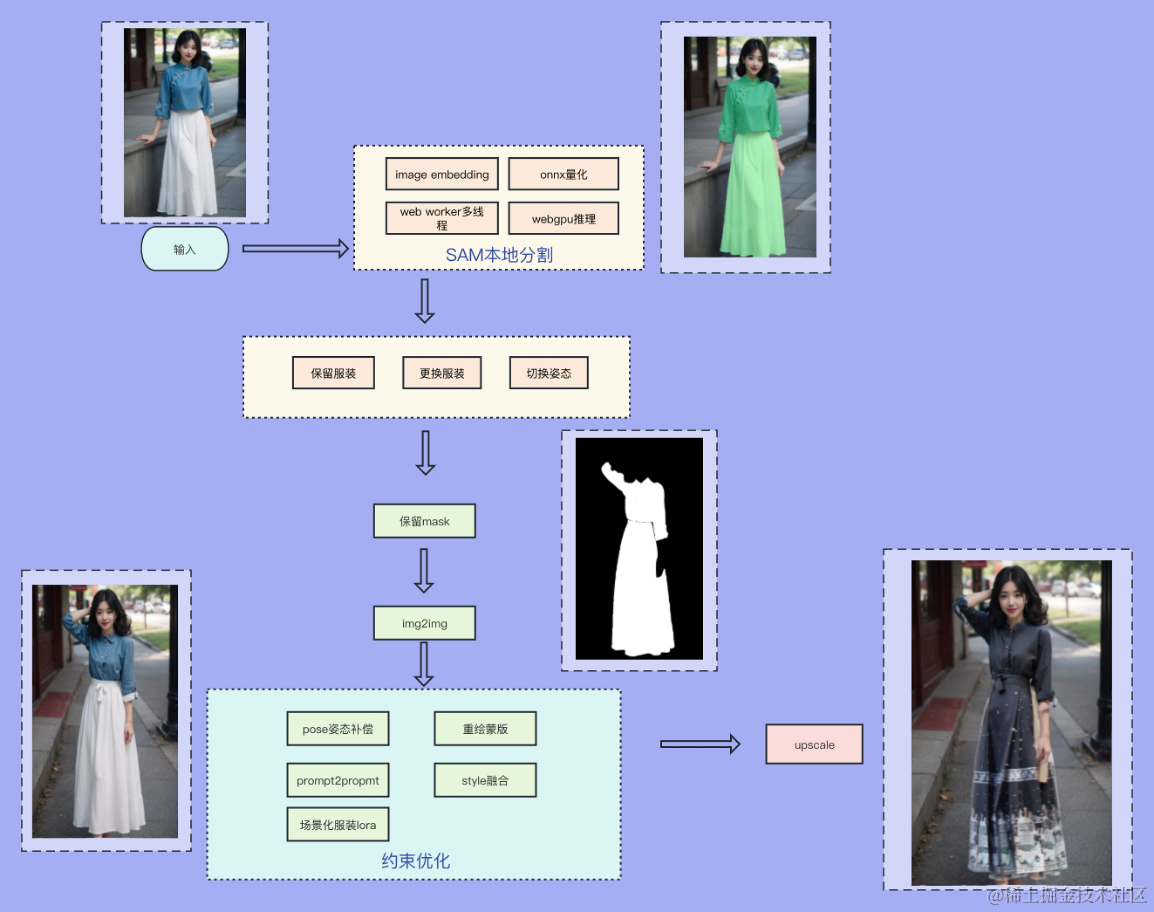
2.4.2 模特换装
通过场景化的服装lora,完成基于商家服装的定制化服装更换,同时可以切换多种姿态用于进行不同长度和姿态的服装展示。
2.5 追求极致体验
2.5.1 基于浏览器的图像分割

我们调研了竞品关于图像分割的页面交互方案,主要有2种实现方式:
1.用户点击图片时,前端计算当前点击坐标(要考虑到图片缩放),多次点击需要记录多个坐标,服务端拿到对应坐标点后生成对应的蒙版图,返回给前端。这种方案需要用户多次点击以生成合适的蒙版图,如果图片比较复杂效果不稳定,且每次点击都需要和后端交互等待loading。
2.用户上传图片后,服务端对图片进行一次全分割,返回分割后所有的图片片段区域(透明背景),用户通过点击可以选择和组合相应的图片区域,前端将组合后的图片合并成一场蒙版图。这种方案服务端在全分割时有个比较长的时间等待,而且全分割比较浪费GPU计算资源。
我们最后尝试了一种新的实现方式:使用ONNX Runtime Web技术,将用户交互分割图像的整个过程,完全由浏览器端实现。这样不仅可以减少服务器与客户端的通信、降低服务端GPU的计算成本,同时还可以保护用户隐私。主要步骤:
1.将全分割模型sam_vit_h_4b8939.pth转换为onnx量化模型
2.服务端将用户上传的图片生成一个image embedding(图片嵌入信息)并保存
3.前端使用onnx模型以及图片对应image embedding,并结合ONNX Runtime Web能力实现图像的实时分割(通过用户点击交互)
4.前端合并多个分割后的图片生成一张蒙版图
补充:ONNX Runtime Web 采用了 WebAssembly 和 WebGL 技术,为 CPU 和 GPU 提供优化的 ONNX 模型推理运行时。
以下是部分代码实现:
...
// 将Numpy文件转换为一个张量
const loadNpyTensor = async (tensorFile: string, dType: any) => {
const npLoader = new npyjs();
const npArray = await npLoader.load(tensorFile);
const tensor = new ort.Tensor(dType, npArray.data, npArray.shape);
return tensor;
};
...
// 解析远程image embedding文件的张量信息并保存
Promise.resolve(loadNpyTensor(`${IMAGE_EMBEDDING}?t=${Date.now()}`, 'float32')).then(
(embedding) => setTensor(embedding),
);
...
// 获取ONNX model结果
const feeds = modelData({
points: points(), //点击区域坐标
tensor: tensor(), //张量信息
modelScale: modelScale(), //缩放信息
});
if (feeds === undefined) return;
const results = await model().run(feeds);
const output = results[model().outputNames[0]];
const mask = onnxMaskToImage(output.data, output.dims[2], output.dims[3]); // 生成蒙版图
setMaskImg([...maskImg(), mask]);
...2.5.2 Service Workers离线缓存技术实现页面秒渲染
上线后我们发现2个比较致命的体验问题:
1.Deno.deploy平台部署后,前端强、弱缓存都没有生效,导致页面加载比较慢,尤其是使用了大量图片的地方,每次都要重新加载不可忍受。查阅官方文档并经过多次尝试,强弱缓存依然不生效。
2.使用ONNX Runtime Web在浏览器端实现图像实时分割虽然优点很多,但是其中的onnx模型、npy文件、wasm文件等都比较大(平均在5M左右),同时又由于强弱缓存无法生效,导致线上基本是无法使用的情况。
最后我们引入Service Workers缓存以及PWA相关技术,实现页面访问的毫秒级渲染(非首次),同时支持安装到本地和离线访问(离线状态下服务不可用)
PWA相关配置:
{
base: '/',
scope: '/',
includeAssets: ['favicon.svg'],
registerType: 'autoUpdate',
manifest: {
name: 'Idou',
lang: 'zh-cn',
short_name: 'Idou',
background_color: '#f6f8fa',
icons: [
{
src: '192.png',
sizes: '192x192',
type: 'image/png',
},
{
src: '256.png',
sizes: '256x256',
type: 'image/png',
},
{
src: '512.png',
sizes: '512x512',
type: 'image/png',
},
{
src: 'apple-touch-icon.png',
sizes: '192x192',
type: 'image/png',
},
],
},
disable: !!process.env.NETLIFY,
workbox: {
navigateFallback: '/lost',
globPatterns: ['**/*.{css,js,html,svg,png,jpeg,ico,txt,wasm,onnx}'], //缓存文件类型
maximumFileSizeToCacheInBytes: 12 * 1024 * 1024, //缓存文件最大12M
},
devOptions: {
enabled: true,
navigateFallbackAllowlist: [/^/lost$/],
},
}
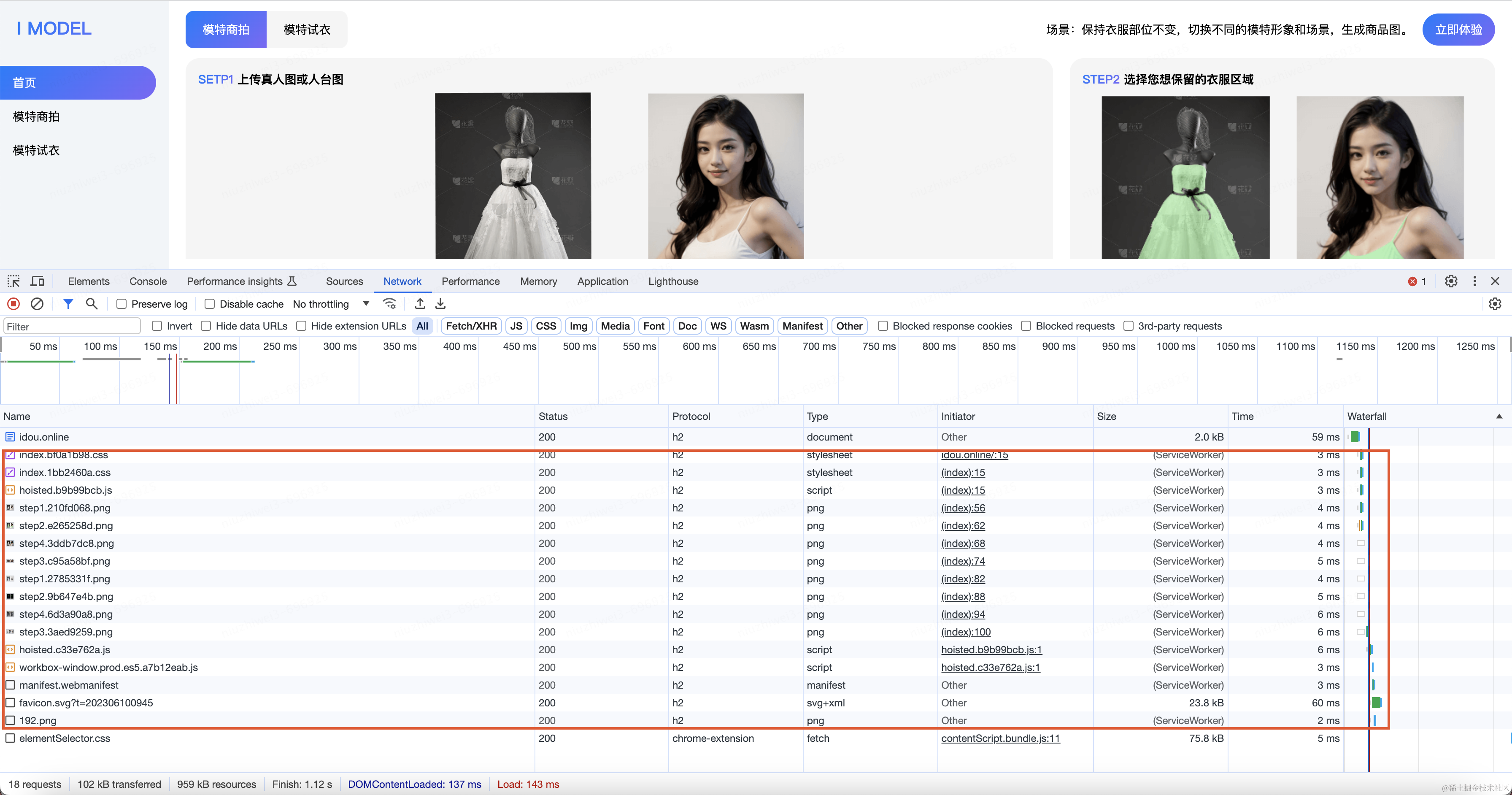
2.5.3 姿态补全算法
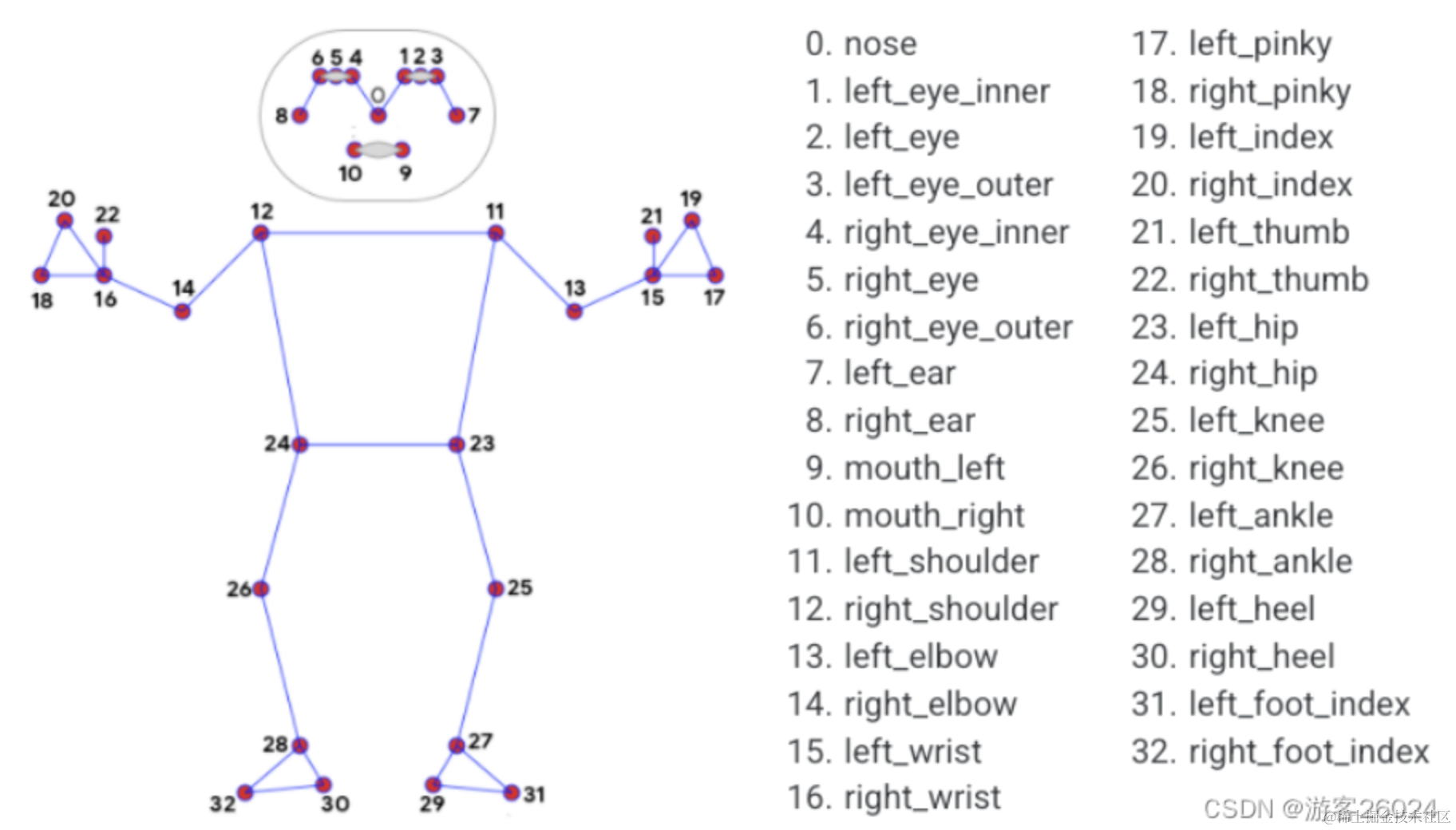
MediaPipe是一款由Google Research 开发并开源的多媒体机器学习模型应用框架,可以通过端侧设备或者直接使用CPU进行推理。
MediaPipe通过33个坐标点,通过关键点坐标构建人体骨架图,关键点包括人体姿势的关键位置,比如头部、肩膀、手臂、腿部等,骨架图可以从连接姿势关键点之间的关系形成骨架,如果包含的关键点和连接的骨架,如果某些关键点缺失或者骨架中断,那么姿态就不会完整。
实现步骤如下图:
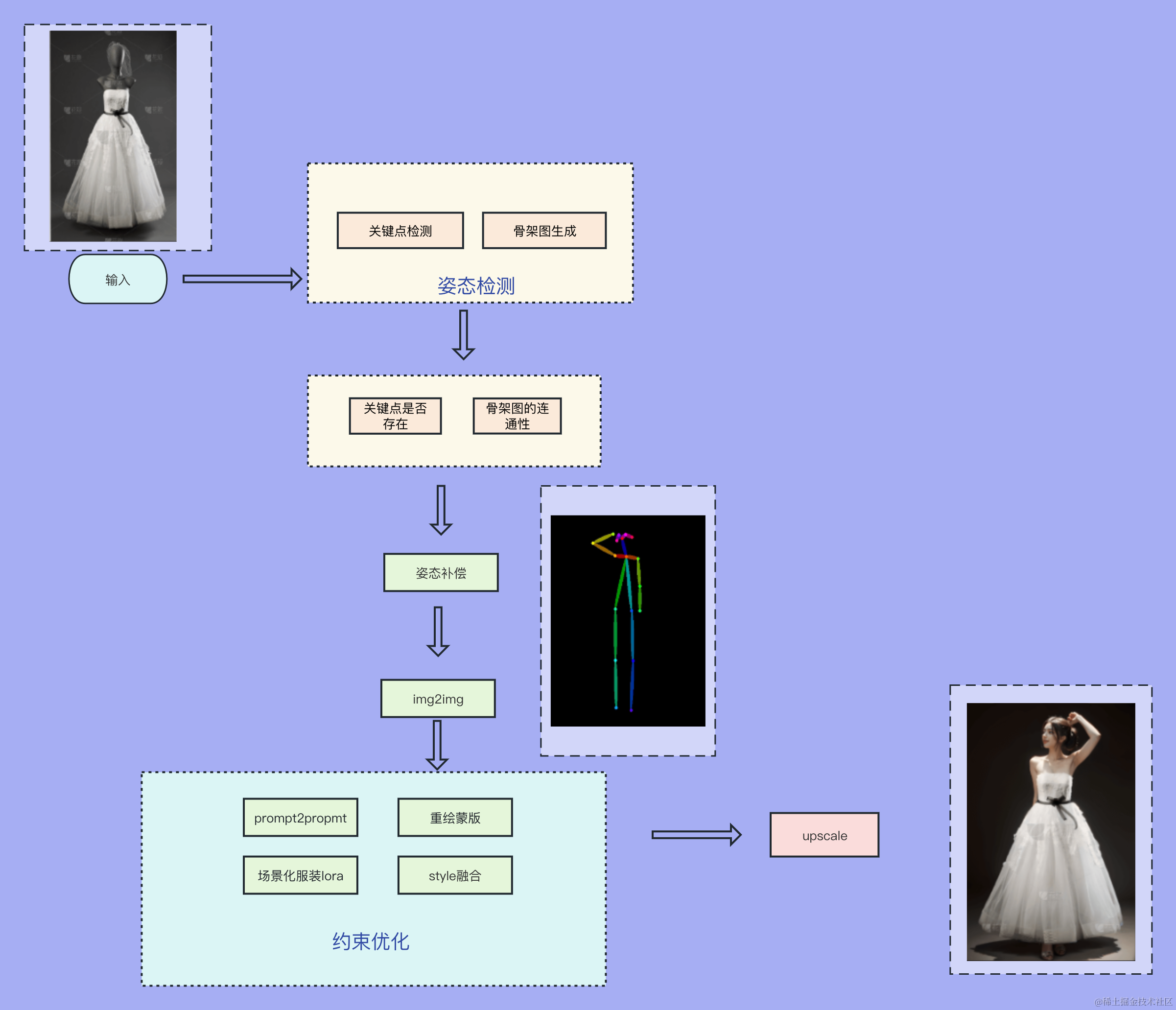
三、最终实现效果
下图是模特商拍中的一个生成案例:只需简单几步,无需用户任何输入,20秒内即可出图,不得不感叹AI强大的生产力。

四、未来展望
感谢数字模特项目的小伙伴们:@曹倚宾、@苟晓攀、@付佳龙的努力付出,未来我们会继续在2个方向进行深耕和尝试。
4.1 难点攻克
以下两类问题,也是所有相关竞品团队都需要解决的两个难题:
一致性问题:
•切换不同模特形象时,不能100%还原原时装;
•切换不同服装或姿态时,不能100%还原原图中的人物形象特征等;
准确性问题:
•切换不同姿态时,有时候人物肢体部位显示异常等;
•衣服部位有时候会有变换,比错位或新增等问题,
4.2 产品功能外延
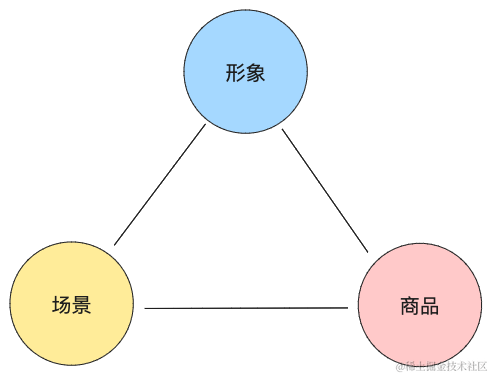
以数字模特为主体,围绕形象、场景、商品三个基本要素,可以延展出很多其他场景,包含但不限于
•数字写真:用户上传8-12张自拍照,生成自己的模特形象,然后可以换装、场景等生成写真照
•品牌IP:用户上传商品或形象图片,生成品牌IP形象或者商品模型,比如各种少数民族的服饰模型等,结合模特形象,生成最终的商品营销图
•创意设计:形象或品牌IP结合多种个性化场景,生成大促会场营销图等
•音/视频:数字模特结合音/视频,生成相关的短视频内容等
•社区+区块链等方向的探索
•3D方向的探索











