
2019阿里云峰会·上海开发者大会于7月24日盛大开幕,本次峰会与未来世界的开发者们分享开源大数据、IT基础设施云化、数据库、云原生、物联网等领域的技术干货,共同探讨前沿科技趋势。本文整理自数据库专场中阿里云智能高级技术专家南仙的精彩演讲,本文为分享了阿里云PB级云数据仓库AnalyticDB for MySQL的核心技术以及其应用场景。
数据库专场PPT下载
本文内容整理自演讲视频以及PPT。
From “BigData”to “FastData”
如今有一种说法“From BigData to FastData”,这是为什么呢?其实,BigData已经发展了很多年了,已经或者即将成为所有行业、所有开发者都能够拥有的能力。但是对于BigData厂商而言,慢慢地发现自身的发展遇到了一些瓶颈,比如Cloudera和HORTONWORKS合并之后在股价方面存在一定的压力,而像MAPR这样资深的Hadoop玩家也在寻求买家。
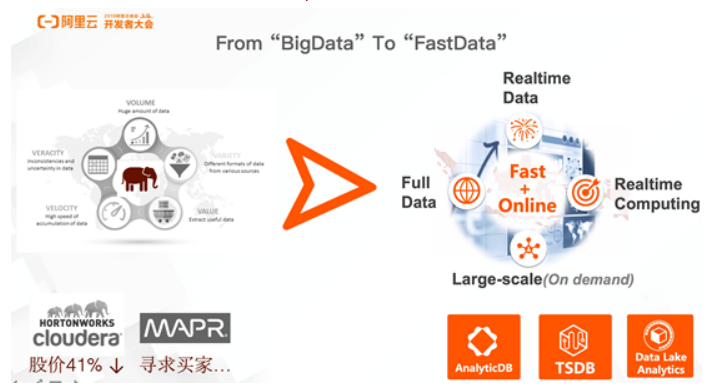
出现以上这类问题的原因在于需求正在发生变化,对于数据本身的价值探索也在发生变化。最重要的一点就是原来只需要面对大量的数据,但是如今面对全量的数据,需要更加实时和更加智能地进行计算和分析。因此,阿里云AnalyticDB的定位就是能够实现实时计算,实现数据价值在线化的数据仓库产品。
AnalyticDB for MySQL介绍:PB级实时数据仓库
AnalyticDB for MySQL(简称ADB)这样一个PB级实时数据仓库的核心理念是实现极致性价比和数据价值的在线化。AnalyticDB的作用就是实现千亿、万亿级的多表复杂关联分析和毫秒级的检索,在全球官方组织TPC的10TB规模的Benchmark的测评环境中,AnalyticDB性能做到了世界第一,并且比国内的其他厂商领先至少5倍以上,相比开源的Spark,性能则高出10倍以上。与此同时,关于AnalyticDB核心技术的论文也发表在了数据库领域的世界顶级学术会议上。

AnalyticDB for MySQL在阿里巴巴集团内部孵化多年,在阿里云上也积累了大量的用户。在如此强悍性能的背后,AnalyticDB更是拥有诸多核心能力:
兼容&超越MySQL:首先,AnalyticDB兼容MySQL并且超越了MySQL。因为MySQL更多地是能够在TP场景下解决很多业务问题,非常稳定并且非常流行,但是在分析场景下,仅仅兼容MySQL是远远不够的,还需要对于窗口函数、CTE等功能以及OLAP标准的支持,而AnalyticDB完全支持这些功能和标准。
云原生,实时按需极致弹性:AnalyticDB是云原生数据库,并且可以做到实时按需极致弹性。AnalyticDB的磁盘可以弹性扩展,单个用户集群的节点数则可以从最小的3台最大可以扩展到2000台的规模,并且可以实现混合负载。
非结构化和结构化融合分析:AnalyticDB可以实现非结构化和结构化融合分析,这里的非结构化数据不仅包括JSON、MySQL里面BLOB以及数组类型,还支持用于人脸识别等AI技术的检索向量,AnalyticDB总共支持5种向量类型和5种向量检索算法。
完备的企业级特性:AnalyticDB具有完备的企业特性,比如备份恢复以及回收站等大数据工具都不具备的能力。与此同时,AnalyticDB还提供跨AZ和跨Region的高可靠保证。
AnalyticDB核心技术: 分层存储+存储计算分离架构 带来极致弹性和开放性
如下图所示,AnalyticDB整体的技术模块最前面是接口层,其对于MySQL协议具有很强的兼容性,能够提供JDBC、ODBC以及UDF、AI的接口。下面一层是优化器,众所周知,在复杂分析场景下,优化器会面临很大的挑战。而AnalyticDB同时支持了基于规则的优化器RBO以及基于成本的优化器CBO和基于历史学习的优化器HBO。再下面一层是超大规模的分布式计算引擎——羲和,它是基于开源代码在阿里内部经过研发团队多年的优化和改造之后打造的具有强劲性能的计算引擎。再往下一层是AnalyticDB行列混合的存储引擎,具有强大的存储和检索能力。目前,AnalyticDB完全基于云上的基础设施构建,包括ECS、GPU、FPGA、OSS等云上的基础能力。
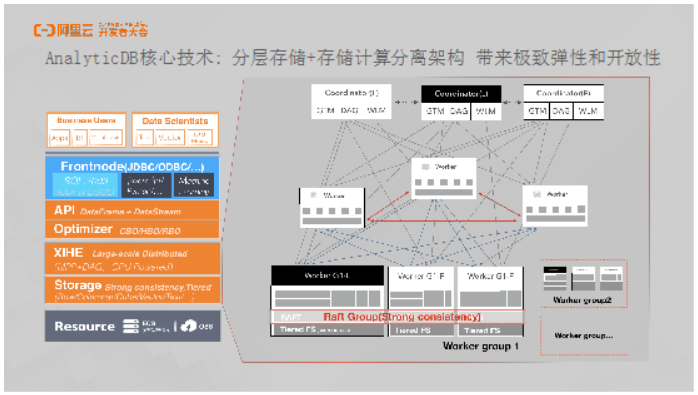
对于AnalyticDB的技术架构而言,从上到下可以分为三种角色。最上层是Frontnode,内部也称为Coordinator协调器,其支持多Master线性扩展,当写入和查询并发过来的时候可以实现线性扩展,最多可以支持扩展到几百个Frontnode。Frontnode会在写入流程下进行数据分发,将数据写入到底下不同的存储节点。中间层的Worker是计算节点,其可以进行弹性伸缩,也是计算存储分离的核心所在。当负载到来的时候,会对于上层解析器所做的物理执行计划进行计算。源头节点读取的就是底层存储。存储部分有一个很重要的概念就是Group,这里解释一下,比如MySQL的主备或者三副本就是一个Group。对于AnalyticDB而言,因为是分布式的,因此有多个Group。可以认为数据水平分区到每个Group上面,Group之间通过Raft协议保证数据的强一致和实时性。在超大规模集群下,成本也是一个非常重要的考虑因素,因此AnalyticDB在底层实现了分层存储,也就是当数据需要进行冷热分离的时候,可以将热数据放在SSD上,而将冷数据实时地通过分层存储系统换入或者换出到OSS上面去。
AnalyticDB核心技术-智能的“行列混存+全索引”带来极致性能
极致性能的提供除了依靠前面所提到的分布式优化器和超大规模高性能的执行引擎之外,还需要依靠存储引擎本身能为计算做多少压缩。对于数据库系统而言,之所以AnalyticDB能够做到性能全球第一,最重要的就是对于存储层的优化。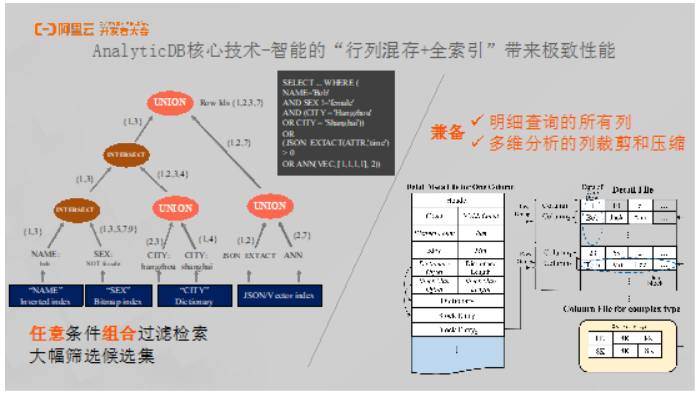
这里为大家介绍AnalyticDB在存储层优化方面的两个技术点,全索引和行列混存。AnalyticDB实现了一整套的索引框架来兼容各种不同的场景,AnalyticDB的索引框架具有多路渐进流式归并的能力,它能够将很多索引条件以及单表位置条件进行多路归并,并生成一个行号。当拿到这个行号之后就能够将大量的数据在存储层过滤掉,数据过滤完成之后就只需要交给计算引擎来进行聚合等计算任务了。AnalyticDB支持很多不同类型的索引,对于字符串类型数据,支持倒排索引、哈希索引;对于数字类型,支持多维KD树索引;此外,还支持JSON索引、bitmap索引以及非结构化的向量索引。
AnalyticDB具有高性能的另外一个原因是其采用了行列混合存储。大家都知道,MySQL等数据库所采用的行存储比较适合更新,但是缺点是不适合进行分析计算,因为分析计算通常是对于一个拥有百余列的大表的部分列进行统计分析或者聚合运算,行存储需要对于每行的百余列数据全部读取出来,对于列的放大非常明显。而列存储的优点在于,除了对于相同Schema的列压缩率较高之外,在计算方面其天生就适合筛选。
AnalyticDB所设计的行列混合存储如上图所示。头文件中包含了一些元数据,比如Sum、Count和Max、Min等,这些统计值用于对于索引、条件和Block的过滤。在每个文件内部有很多不同的Block,每个Block可以看做Row Group,其内部按照Column进行存储。因此,当需要扫描的时候,一旦定位到在哪个Row Group里面就可以很快将数据取出来。之所以设计成Row Group而非整列文件的原因在于很多时候需要取明细数据,如果按列存储,需要拼出所有行的数据,这样做开销会非常大,而可以通过动态调节不同的Row Group的大小来动态地兼容这两种场景。
AnalyticDB核心技术:一个系统一套存储兼顾多种场景
AnalyticDB之所以具有强大的性能,除了架构弹性之外,还具有一套能够兼顾多种场景的存储系统,可以兼容多维分析、明细查询、实时写入等场景。其背后有三个关键技术,包括上述提到的行列混存,还有混合负载。AnalyticDB支持高并发、低延迟的混合负载的管理,此外,还支持超大规模的融合计算引擎。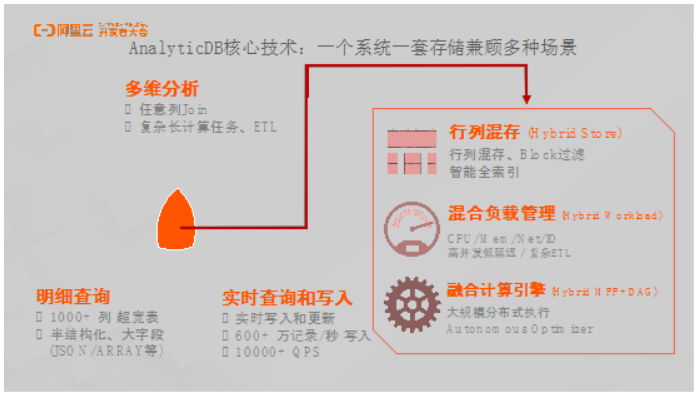
AnalyticDB for MySQL:典型场景和客户价值
AnalyticDB支持将大数据、应用队列、MySQL、Oracle中的数据通过DTS等数据同步工具同步到AnalyticDB做数据分析。而在上层可以接入不同的可视化报表以及用户APP。举一个内部案例,阿里妈妈内部有一个定向营销平台叫做达摩盘。达摩盘有一万多张表,总数据量超过100TB,平均每条查询大小为10个表的Join。借助AnalyticDB,达摩盘可以支持上千个列维度的筛选,可以做到峰值每秒120万的写入速度,10个以上表进行Join的QPS能够达到50。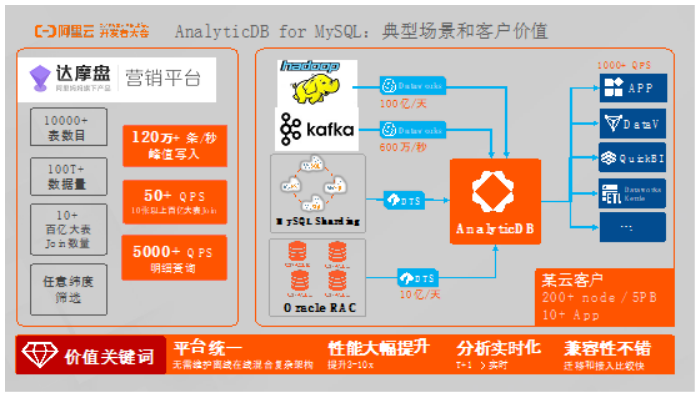
Data Lake Analytics:全域数据、开放分析
阿里云的Data Lake Analytics是Serverless的开放分析产品,没有数据存储,因此成本也非常低。如果用户的数据在OSS或者某个存储引擎里面,无需搬动数据就可以直接计算。因为采用了Serverless的设计理念,因此本身具有很强的弹性,同时成本也非常低。
Data Lake Analytics和AnalyticDB是互补的关系,AnalyticDB属于数据仓库,而Data Lake Analytics则可以进行融合分析。Data Lake Analytics除了继承了AnalyticDB的羲和计算引擎之外,还集成了Spark,并且其底层基于K8S实现了Serverless。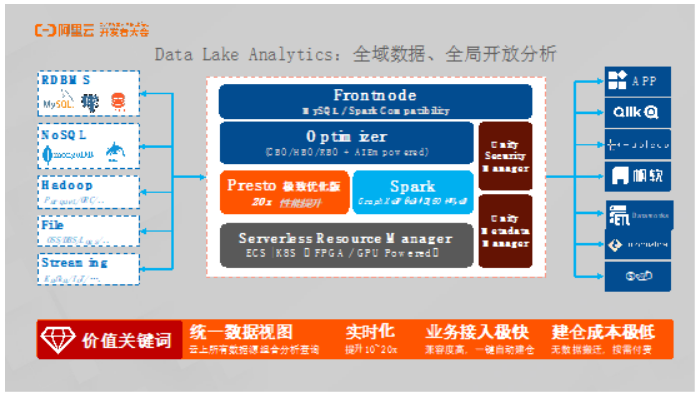
接下来为大家分享两个具体案例
客户案例1:移动运营APP解决方案
这里以无他相机为例为大家分享移动运营APP解决方案。无他相机的上百亿数据都存储在MySQL里面,之前使用MongoDB这样的NoSQL数据库进行数据存储,但是发现分析性能根本无法接受,当时每个报表需要至少40分钟才能完成。使用AnalyticDB改造系统架构之后,从用户统计、活动效果以及行为分析等方面能够发现明显提升,实现的报表构造从40分钟到秒级的跨越。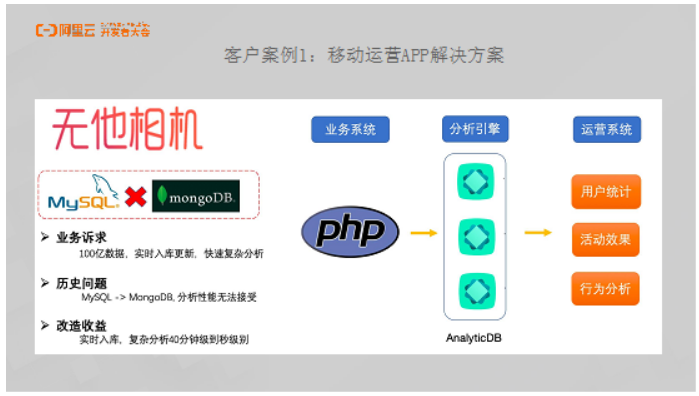
客户案例2:物流行业实时数仓
第二个案例以跨境物流的公司递四方为例分享物流行业实时数仓方案。对于递四方的数据架构而言,通过MySQL实现业务处理,并将数据通过DTS同步到AnalyticDB。对于日志数据而言,通过Agent实现打点,通过消息队列Kafka收集数据,并通过内部程序将所收集的数据注入到AnalyticDB里面去,前端连接了阿里云的QuickBI和DataV实现数据大屏和报表。仅仅用了一个半月的时间,递四方就完成整个数据实时数仓的构建。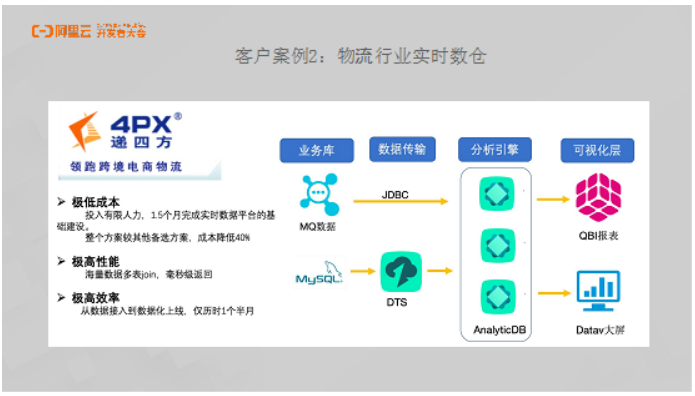
AnalyticDB for MySQL:客户遍布各行各业
AnalyticDB for MySQL的客户遍布各行各业,比如互联网、新零售、数字政府、金融以及公安、税务、电网、政法等,这些行业都在广泛地使用阿里云的AnalyticDB。

AnalyticDB for MySQL 3.0版本:下一代云原生OLAP产品
阿里云数据库团队匠心打造的全新的AnalyticDB for MySQL 3.0版本已经研发完成了,目前正处于公测中。
相比之前的版本,AnalyticDB for MySQL 3.0版本主要在以下四个方面进行了改进
更易用:相比于2.0版本,用户能够感受到更多数据库的特性。AnalyticDB 3.0版本融合了大数据超大规模的计算能力、分析能力以及数据库的使用体验。用户能够感受到AnalyticDB 3.0是一个拥有超强计算能力、特别快的计算速度的MySQL。其支持最多256个DB,并且大幅度提升了兼容性,在阿里巴巴内部测试中,兼容性高达99.99%,并且能够做到写入数据的立即可见。
更高性能:AnalyticDB 3.0版本的实时写入性能提升了1.5倍,查询性能在原本全球第一的基础之上又提升了40%,并且预计未来还会继续刷新榜单。AnalyticDB支持从MaxCompute、Hadoop、OSS以及MySQL数据库批量向AnalyticDB导入数据,并且能够实现每小时TB级别的数据导入速度。
更弹性:AnalyticDB 3.0版本拥有更高的弹性,磁盘存储空间可以弹性伸缩,比如一个节点可以从100G扩展到1TB甚至更大,同时可以伸缩磁盘空间,实现纵向升降级,节点数目也可以实现任意节点的扩缩。
更可靠:AnalyticDB 3.0版本具备与MySQL完全对齐的权限体系,其支持库级权限、表级权限以及列级权限。并且数据存储采用了三副本,达到了工业级别的安全等级,还拥有完备的数据备份恢复能力。
原文链接
本文为云栖社区原创内容,未经允许不得转载。











