

Capped CRF编码是一种单通道编码方法,与双通道VBR相比,可以节省编码成本。Capped CRF也是一种简单的per-title编码方法,可以降低带宽成本并且提高观众的体验质量。本文来自资深多媒体技术咨询师Jan Oze,LiveVideoStack对原文进行了摘译。
文 / Jan Ozer
译 / 王月美
审校 / Ant
原文:
https://streaminglearningcenter.com/blogs/saving-encoding-streaming-deploy-capped-crf.html
Per-title编码为每个编码定制视频素材的复杂性。难以编码的视频剪辑用以比普通阶梯更高的数据速率进行编码,而较容易编码的视频剪辑则是以较低的数据速率来进行编码。由于大多数编码阶梯都较为保守,因此,在大多数情况下,部署per-title编码将会导致大部分视频剪辑的数据速率降低。
你可以从许多不同的供应商处以多种形式访问per-title编码。例如,你可以从Beamr,Crunch Media,Euclid IQ和ZPEG获得优化技术许可;部署来自Capella Systems,Harmonic,Elemental和其他具有per-title编码功能的公司的内部编码器;又或者从Bitmovin,Brightcove,JWPlayer和Mux,或者访问云中的per-title编码。根据你的编码平台,你可以通过名为Capped CRF的技术来自行推广。
节省带宽,或提高服务质量还是二者兼顾?
对于某些公司来说,部署Capped CRF将降低带宽成本。对于另一些公司来说,它将改善观众的服务质量。而对其他一些公司来说,以上二者兼有。而这完全取决于你向现有客户交付编码阶梯中的哪些视频流。
为了解释说明,请查阅表1,其显示了编码阶梯和三种不同的流分布模式A、B和C。每种模式显示了实际从自适应组传递的每个流的百分比,它正如你能够从日志文件中派生而出的一样。
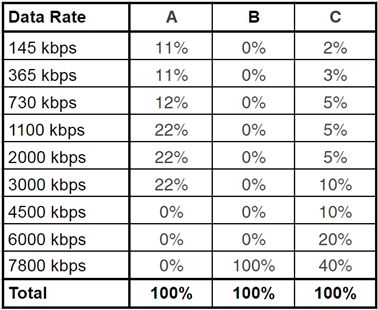
表1:三种流分布模式
在模式A中,所有的传输流的数据速率均是3000Kbps或更低,这或许是在第三世界国家中分布的代表。这种情况下,切换到Capped CRF对带宽成本没有什么影响,因为你只是将一个3000 kbps的流(或更低)转换为另一个。当然,质量体验可能会得到改善。但是,与此同时你将分配相同的带宽流,因此带宽节省是会不明显的。
在分布模式B中,100%的传输流的数据速率是7800Kbps,这可能是如Scandinavia通过光纤到家分布的代表。在这里,部署Capped CRF可能会降低大多数最高带宽流的带宽,这将直接转化为带宽节省。对于特别难以编码的视频剪辑,它还可以改善观众的体验质量。
模式C则显示顶部梯级的高度集中和其他梯级的适宜传播,这可能是移动和宽带的混合。同样,部署Capped CRF会降低梯形图中大多数流的数据速率,从而降低传输带宽。而且,它还可以提高客户观看的一些视频流的质量,从而提高用户的体验质量。
显而易见的是,带宽节省取决于你的分布模式,即必须从日志文件中挖掘的数据。当然,这也取决于你对现有阶梯的攻击力。如果你的1080p视频的最高比特率是6000 Kbps或更高,而你分发了很多这样的视频流,那么你可能会节省较多的带宽。如果它的速率是4200 Kbps,那么你再发布很多视频流就相当激进了,而节省的带宽会更加缓和。
注意,所有这些观察结果都适用于任何一项per-title技术,而不仅仅是Capped CRF。同时,它们也适用于实现如HEVC或AV1这样的新编解码器。
什么是Capped CRF
固定码率系数(CRF)是一种编码模式,可以向上或向下调整文件的数据速率,以实现选定的质量级别而不是特定的数据速率。CRF的取值范围从0到51,较低的数字将提供更高的视觉质量分数。多种编解码器均支持CRF,其中包括x264,x265以及VP9。
就其自身而言,CRF无法用于自适应比特率流,其中在梯级梯级中的数据速率需要受到限制。但是,通过向CRF添加“上限”,你可以将此数据速率限制为该上限值。实现上限 CRF的FFmpeg参数如下所示:
ffmpeg -i input_file -crf 23 -maxrate 6750k -bufsize 6750k output_file
这告知FFmpeg以23的质量等级进行编码,但是使用4500kbps的VBV缓冲器将数据速率限制在6750kbps。对于易于编码的视频剪辑,CRF值将限制数据速率,因为可以在低于上限的数据速率下实现所需的质量。而对于难以编码的视频剪辑,上限值将启动以控制数据速率。
Capped CRF缺乏了更复杂的per-title技术中的一些功能,例如能够改变阶梯中的梯级数或是改变某些梯级的分辨率的能力。尽管如此,在与其他技术相比时,总能更胜一筹。而且,如果你的编码工具支,那么它基本上是免费的。
对于Streaming Media East,我将Capped CRF与来自Capella Systems和Brightcove的per-title技术进行了比较。表2显示了关键结果。
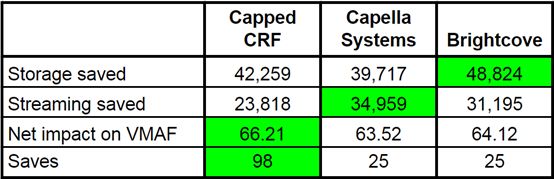
表2.来自2018 Streaming Media East的per-title技术记分卡。
从表格中,你可以看到Capped CRF在节省存储空间中排名第二,流媒体带宽的节省排名最后,但是对VMAF的净影响排名第一。从本质上讲,这意味着虽然Capped CRF并没有像其他两种技术那样降低数据速率,但却有利于提高观众的体验质量。如果你的目标是节省更多数据流,则可以使用更高的CRF值来降低数据速率并略微降低视频质量。例如,我使用CRF为22进行测试,而JWPlayer使用CRF为23,则可以节省更多带宽。
Capped CRF的一个主要的优点就是它是单通道技术。如果你目前使用的是双通道技术,那么Capped CRF也会显着增加容量或削减成本。相比之下,其他大多数per-title技术在实际编码之前需要进行额外的分析,这可能会提高编码成本或者会降低容量。
Capped CRF的单通道特性反映在“save”栏中的数据98上,这代表14个测试文件里七个梯级每一个的一次通过。Capella和Brightcove技术是通过从易于编码的视频剪辑的编码阶梯中消除梯级来获得saves值,但这并不会影响用于他们的per-title编码的两个系统分析的传递(它将用于下一次传递)。
比特率控制问题
关于Capped CRF的一个问题是:由于除了上限值之外没有其他比特率控制,文件中可能存在巨大的数据速率波动,这可能会破坏你所选择的ABR技术中所使用的切换算法。图1所示的文件中包含了芭蕾舞剧(峰值)与一部谈话短片的混合(谷值),这导致文件内的数据速率大小从约低于3Mbps变为6Mbps。
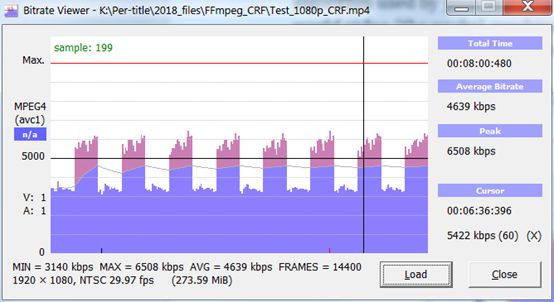
图1.使用Capped CFR编码的文件中重要数据速率的波动.
事实上,其他大多数VBR技术都提供类似的文件。例如,图2显示了使用200%约束VBR用FFmpeg编码的同一文件的数据速率。在该文件中,谷值大致相同,但峰值略高。所以,如果你现在使用200%约束VBR,则Capped CRF应该不会造成任何的担忧。
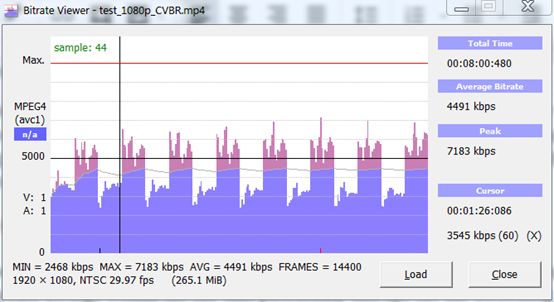
图2.使用200%约束VBR编码的文件中更为糟糕的数据速率波动
另一方面,如果是因为你认为它最大化了文件的可传递性而使用CBR,那么Capped CRF就绝对不适合你。从我的角度来看,JWPlayer在部署数年后继续使用Capped CRF的事实消除了大部分的问题。
留意摄像头屏幕
我大约用20个测试剪辑测试per-title技术,其中包括三个左右的摄像头屏幕或类似的合成剪辑。在写本篇文章的时候,我测试确认了CRF是否会严重降低了任何剪辑的质量,并通过莫斯科州立大学VQMT的结果图进行简化,如图3所示。

图3.结果图显示了Capped CRF和200%约束VBR之间显着的质量差异
简单的说,我在这些分析中使用了PSNR(而不是VMAF),因为它计算速度非常快,并且对于质量问题的分析非常有效。这里,我正分析200%约束VBR(橙色表示)和Capped CRF(绿色表示)。顶部图表显示整个文件中两个文件的PSNR值,而底部图表则显示顶部图表中突出显示的区域(大约是55%—65%)。数值之间的显着增量通常表明了非常显着的质量差异。
如果单击剪辑右下角的“Show Fram”,则可以切换两个分析剪辑中的源帧和各个帧。图4显示了来自Capped CRF剪辑屏幕的一部分,很明显能够看到它的降级。
图4.表示这样的几帧
请注意,到目前为止,这是我在三个合成剪辑中看到的最大的质量差异,而且是在现实世界的剪辑或动画中没有任何意义的差异。大多数真实世界的剪辑的比较如图5所示。这是一个高动态剪辑,其中CRF提供的数据速率略高于200%约束VBR,而且质量略高,但200%约束VBR图没有主要的增量。
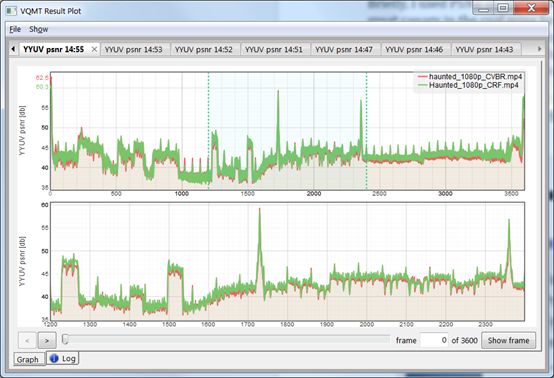
图5. CRF剪辑始终略高于200%约束VBR。
因此,尽管我不建议将Capped CRF用于无需额外测试的摄像头屏幕和类似的合成镜头,但我很乐意推荐将它用于真实世界的视频和动画。
部署Capped CRF
只要编码器允许你对编码参数进行精细控制,部署Capped CRF编码就非常简单。例如,图6是来自Hybrik云编码器的基于浏览器的用户界面的屏幕截图。如你所见,你选择了CRF比特率模式,然后输入max_bitrate和vbv_buffer大小值(CRF值的条目位于下方且并未显示)。如果你使用的是API,则可以通过JSON配置相同的参数。大多数云编码器都是围绕FFmpeg构建的,因此如果其他per-title方法不可用,那你就可以访问CRF编码。
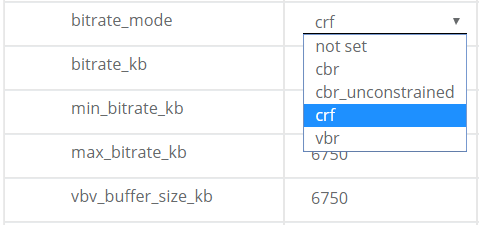
图6.在Hybrik云编码器中选择Capped CRF.
如果你的桌面编码器不允许你选择crf作为比特率,你可以直接在用户界面中输入x264命令。这是我上次确认的Telestream Vantage的一项功能。如果你可以访问CRF控件,则可以将这些替换为以前的比特率控制方法,无论是CBR还是VBR。
FFmpeg中的Capped CRF
下面的批处理文件显示了Streaming Media比较中的测试阶梯,其中缺少通常你在FFmpeg批处理中能够看到的GOP,预设,音频和其他命令。当然,我已将CRF值更改为23以匹配JWPlayer。我将最大速率和缓冲区大小设置为原始目标数据速率的1.5倍,即1080p视频流的速率为4500 kbps。JWPlayer也为数据速率和缓冲区大小设置了相同的值,当然我也看到过其他文档将缓冲区设为目标的两倍。
1ffmpeg -i Input.mp4 -c:v libx264 -crf 23 -maxrate 6750k -bufsize 6750k Output_1080p.mp42ffmpeg -i Input.mp4 -c:v libx264 -crf 23 -s 1280x720 -maxrate 4050k -bufsize 4050k Output_720p.mp43ffmpeg -i Input.mp4 -c:v libx264 -crf 23 -s 960x540 -maxrate 2850k -bufsize 2850k Output_540p.mp44ffmpeg -i Input.mp4 -c:v libx264 -crf 23 -s 852x480 -maxrate 2025k -bufsize 2025k Output_480p.mp45ffmpeg -i Input.mp4 -c:v libx264 -crf 23 -s 640x360 -maxrate 1350k -bufsize 1350k Output_360p.mp46ffmpeg -i Input.mp4 -c:v libx264 -crf 23 -s 480x272 -maxrate 750k -bufsize 750k Output_272p.mp47ffmpeg -i Input.mp4 -c:v libx264 -crf 23 -s 320x180 -maxrate 375k -bufsize 375k Output_180p.mp4
批处理1.使用Capped CRF编码完整的梯形图。
请注意,你可以调整这些所有的参数以实现特定的传输和体验质量目标。较低的CRF值(如21-22)将提供更高的比特率和更好的体验质量,而更高的CRF值则(如24-25)带来的结果就恰恰相反。
多分辨率
可以看到,批处理1中包含七个具有不同分辨率的梯级。这将步骤进行了简化,因为只要在所有梯级中使用相同的CRF值,较大的分辨率应始终具有较高的数据速率,从而保留有效流切换所需的数据速率级数。
但是,如果你在720p有三个梯级会发生什么?比如CRF值分别为 21,23和25?
你如何确定720p @ CRF 25时梯级的数据速率高于下一个较低的梯级,如540p @ CRF 21。4K视频镜头里的梯子可以有9到11个梯级,所以你几乎肯定会遇到这个问题。
在使用VR 4K素材时,我遇到过这种情况。在那种情况下,我在不同分辨率和CRF值的多个剪辑上运行测试编码器。通过这些数据,我创建了一个梯形图。它利用不同的CRF值,并多次使用多个分辨率(如4K,1080p和720p)。然后我用多个视频剪辑测试了该梯形图,编码复杂度从简单到复杂,以确保梯子在所有梯级之间保持必要的数据速率。
使用非常简单的剪辑,较低的梯级往往非常靠近。这仅仅是因为若最高速率为5 Mbps,则不需要11个梯级。当然,ABR小组仍然可行。我测试的难以编码的文件看起来就近乎完美。

本文分享自微信公众号 - LiveVideoStack(livevideostack)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











