
API设计风格(RRC、REST、GraphQL、服务端驱动)
Web API设计其实是一个挺重要的设计话题,许多公司都会有公司层面的Web API设计规范,几乎所有的项目在详细设计阶段都会进行API设计,项目开发后都会有一份API文档供测试和联调。本文尝试根据自己的理解总结一下目前常见的四种API设计风格以及设计考虑点。
RPC
这是最常见的方式,RPC说的是本地调用远程的方法,面向的是过程。
- RPC形式的API组织形态是类和方法,或者说领域和行为。
- 因此API的命名往往是一个动词,比如GetUserInfo,CreateUser。
- 因为URI会非常多而且往往没有一些约定规范,所以需要有详细的文档。
- 也是因为无拘无束,HTTP方法基本只用GET和POST,设计起来比较简单。
这里就不贴例子了,估计超过50%的API是这种分格的。
REST
是一种架构风格,有四个级别的成熟度:
- 级别 0:定义一个 URI,所有操作是对此 URI 发出的 POST 请求。
- 级别 1:为各个资源单独创建 URI。
- 级别 2:使用 HTTP 方法来定义对资源执行的操作。
- 级别 3:使用超媒体(HATEOAS)。
级别0其实就是类RPC的风格,级别3是真正的REST,大多数号称REST的API在级别2。REST实现一些要点包括:
REST形式的API组织形态是资源和实体,一切围绕资源(级别1的要点)。设计流程包括:
- 确定API提供的资源
- 确定资源之间的关系
- 根据资源类型和关系确定资源URI结构
- 确定资源的结构体
会定义一些标准方法(级别2的要点),然后把标准方法映射到实现(比如HTTP Method):

- GET:获取资源详情或资源列表。对于collection类型的URI(比如**/customers)就是获取资源列表,对于item类型的URI(比如/customers/1**)就是获取一个资源。
- POST:创建资源,请求体是新资源的内容。往往POST是用于为集合新增资源。
- PUT:创建或修改资源,请求体是新资源的内容。往往PUT用于单个资源的新增或修改。实现上必须幂等。
- PATCH:部分修改资源,请求体是修改的那部分内容。PUT一般要求提交整个资源进行修改,而PATCH用于修改部分内容(比如某个属性)。
- DELETE:移除资源。和GET一样,对于collection类型的URI(比如**/customers)就是删除所有资源,对于item类型的URI(比如/customers/1**)就是删除一个资源。
需要考虑资源之间的导航(级别3的要点,比如使用HATEOAS,HATEOAS是Hypertext as the Engine of Application State的缩写)。有了资源导航,客户端甚至可能不需要参阅文档就可以找到更多对自己有用的资源,不过HATEOAS没有固定的标准,比如:
{ "content": [ { "price": 499.00, "description": "Apple tablet device", "name": "iPad", "links": [ { "rel": "self", "href": "http://localhost:8080/product/1" } ], "attributes": { "connector": "socket" } }, { "price": 49.00, "description": "Dock for iPhone/iPad", "name": "Dock", "links": [ { "rel": "self", "href": "http://localhost:8080/product/3" } ], "attributes": { "connector": "plug" } } ], "links": [ { "rel": "product.search", "href": "http://localhost:8080/product/search" } ] }
Spring框架也提供了相应的支持:https://spring.io/projects/spring-hateoas,比如如下的代码:
@RestController
public class GreetingController { private static final String TEMPLATE = "Hello, %s!"; @RequestMapping("/greeting") public HttpEntity<Greeting> greeting( @RequestParam(value = "name", required = false, defaultValue = "World") String name) { Greeting greeting = new Greeting(String.format(TEMPLATE, name)); greeting.add(linkTo(methodOn(GreetingController.class).greeting(name)).withSelfRel()); return new ResponseEntity<>(greeting, HttpStatus.OK); } }
产生如下的结果: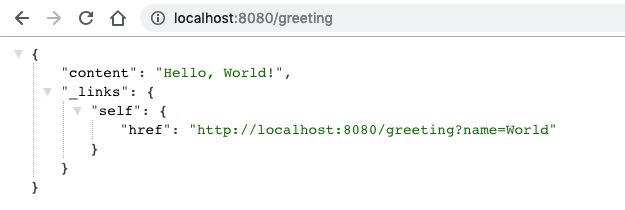
- 除了之前提到的几个要点,REST API的设计还有一些小点:
- 必须无状态的,相互独立的,不区分顺序的
- API需要有一致的接口来解耦客户端和服务实现,如果基于HTTP那么务必使用HTTP的Method来操作资源,而且尽量使用HTTP响应码来处理错误
- 需要尽量考虑缓存、版本控制、内容协商、部分响应等实现
可以说REST的API设计是需要设计感的,需要仔细来思考API的资源,资源之间的关系和导航,URI的定义等等。对于一套设计精良的REST API,其实客户端只要知道可用资源清单,往往就可以轻易根据约定俗成的规范以及导航探索出大部分API。比较讽刺的是,有很多网站给前端和客户端的接口是REST的,爬虫开发者可以轻易探索到所有接口,甚至一些内部接口,毕竟猜一下REST的接口比RPC的接口容易的多。
作为补充,下面再列几个有关REST API设计大家争议讨论纠结的比较多的几个方面。
创建资源使用PUT还是POST
比如 https://stackoverflow.com/questions/630453/put-vs-post-in-rest ,总的来说大家基本认同微软提到的三个方面:
- 客户端决定资源名用PUT,服务端决定资源名用POST
- POST是把资源加入集合
- PUT实现需要幂等
当然,有些公司的规范是创建资源仅仅是POST,不支持PUT
异常处理的HTTP响应状态码
- REST的建议是应当考虑尽可能使用匹配的Http状态码来对应到错误类型,比如删除用户的操作:
- 用户找不到是404
- 删除成功后是204
- 用户因为有账户余额无法删除是409(客户端的问题是4xx)
- 其它服务端异常是500(服务端的问题是5xx)
- 总体来说这个规范出发点是好的,实现起来落地比较困难,原因有下面几个:
- 状态码对应各种错误类型的映射关系没有统一标准,工程师实现的时候五花八门
- 实现起来可能需要在业务逻辑中耦合状态码,很难在GlobalExceptionHandler去做,除非事先先规范出十几种异常
- 如果使用了不正确的响应状态可能会导致反向代理等触发错误的一些操作,而且出现问题的时候搞不清楚是哪个层面出错了
- 各种Http Client对应非200状态码的处理方式不太一致
- 有关这个问题的争议,各大平台的API实现有些遵从这个规范建议,有些是500甚至200打天下的,相关的国内外讨论有:
- 国内外的很多大厂对于这点的实现不尽相同,总的来说,我的建议是:
- 如果我们明确API是REST的,而且API对外使用,应当使用合适的状态码来反映错误(建议控制在20个以内常用的),并且在文档中进行说明,而且出错后需要在响应体补充细化的error信息(包含code和message)
- 如果REST API对内使用,那么在客户端和服务端商量好统一标准的情况下可以对响应码类型进行收敛到几个,实现起来也方便
- 如果API是内部使用的RPC over HTTP形式,甚至可以退化到业务异常也使用200响应返回
返回数据是否需要包装
看到过许多文章都在说,REST还是建议返回的数据本身就是实体信息(或列表信息),而不建议把数据进行一层包装(Result)。如果需要有更多的信息来补充的话,可以放到HTTP Header中,比如https://developer.github.com/v3/projects/cards/的API:
GET /projects/columns/:column_id/cards
Status: 200 OK
Link: <https://api.github.com/resource?page=2>; rel="next", <https://api.github.com/resource?page=5>; rel="last" [ { "url": "https://api.github.com/projects/columns/cards/1478", "id": 1478, "node_id": "MDExOlByb2plY3RDYXJkMTQ3OA==", "note": "Add payload for delete Project column", "created_at": "2016-09-05T14:21:06Z", "updated_at": "2016-09-05T14:20:22Z", "archived": false, "column_url": "https://api.github.com/projects/columns/367", "content_url": "https://api.github.com/repos/api-playground/projects-test/issues/3", "project_url": "https://api.github.com/projects/120" } ]
之前我们给出的HATEOAS的例子是在响应体中有"content"和"links"的层级,也就是响应体并不是资源本身,是有包装的,除了links,很多时候我们会直接以统一的格式来定义API响应结构体,比如:
{
"code" : "",
"message" : "",
"path" : "" "time" : "", "data" : {}, "links": [] }
我个人比较喜欢这种方式,不喜欢使用HTTP头,原因还是因为多变的部署和网络环境下,如果某些环节请求头被修改了或丢弃了会很麻烦(还有麻烦的Header Key大小写问题),响应体一般所有的代理都不会去动。
URI的设计层级是否超过两层
微软的API设计指南(文末有贴地址)中指出避免太复杂的层级资源,比如**/customers/1/orders/99/products过于复杂,可以退化为/customers/1/orders和/orders/99/products,不URI的复杂度不应该超过collection/item/collection**,Google的一些API会层级比较多,比如:
API service: spanner.googleapis.com
A collection of instances: projects/*/instances/*.
A collection of instance operations: projects/*/instances/*/operations/*. A collection of databases: projects/*/instances/*/databases/*. A collection of database operations: projects/*/instances/*/databases/*/operations/*. A collection of database sessions: projects/*/instances/*/databases/*/sessions/*
这点我比较赞同微软的规范,太深的层级在实现起来也不方便。
GraphQL
如果说RPC面向过程,REST面向资源,那么GraphQL就是面向数据查询了。“GraphQL 既是一种用于 API 的查询语言也是一个满足你数据查询的运行时。 GraphQL 对你的 API 中的数据提供了一套易于理解的完整描述,使得客户端能够准确地获得它需要的数据,而且没有任何冗余,也让 API 更容易地随着时间推移而演进,还能用于构建强大的开发者工具。”
采用GraphQL,甚至不需要有任何的接口文档,在定义了Schema之后,服务端实现Schema,客户端可以查看Schema,然后构建出自己需要的查询请求来获得自己需要的数据。
比如定义如下的Schema:
#
# Schemas must have at least a query root type
#
schema { query: Query } type Query { characters( episode: Episode ) : [Character] human( # The id of the human you are interested in id : ID! ) : Human droid( # The non null id of the droid you are interested in id: ID! ): Droid } # One of the films in the Star Wars Trilogy enum Episode { # Released in 1977 NEWHOPE # Released in 1980. EMPIRE # Released in 1983. JEDI } # A character in the Star Wars Trilogy interface Character { # The id of the character. id: ID! # The name of the character. name: String! # The friends of the character, or an empty list if they # have none. friends: [Character] # Which movies they appear in. appearsIn: [Episode]! # All secrets about their past. secretBackstory : String @deprecated(reason : "We have decided that this is not canon") } # A humanoid creature in the Star Wars universe. type Human implements Character { # The id of the human. id: ID! # The name of the human. name: String! # The friends of the human, or an empty list if they have none. friends: [Character] # Which movies they appear in. appearsIn: [Episode]! # The home planet of the human, or null if unknown. homePlanet: String # Where are they from and how they came to be who they are. secretBackstory : String @deprecated(reason : "We have decided that this is not canon") } # A mechanical creature in the Star Wars universe. type Droid implements Character { # The id of the droid. id: ID! # The name of the droid. name: String! # The friends of the droid, or an empty list if they have none. friends: [Character] # Which movies they appear in. appearsIn: [Episode]! # The primary function of the droid. primaryFunction: String # Construction date and the name of the designer. secretBackstory : String @deprecated(reason : "We have decided that this is not canon") }
采用GraphQL Playground(https://github.com/prisma/graphql-playground)来查看graphql端点可以看到所有支持的查询: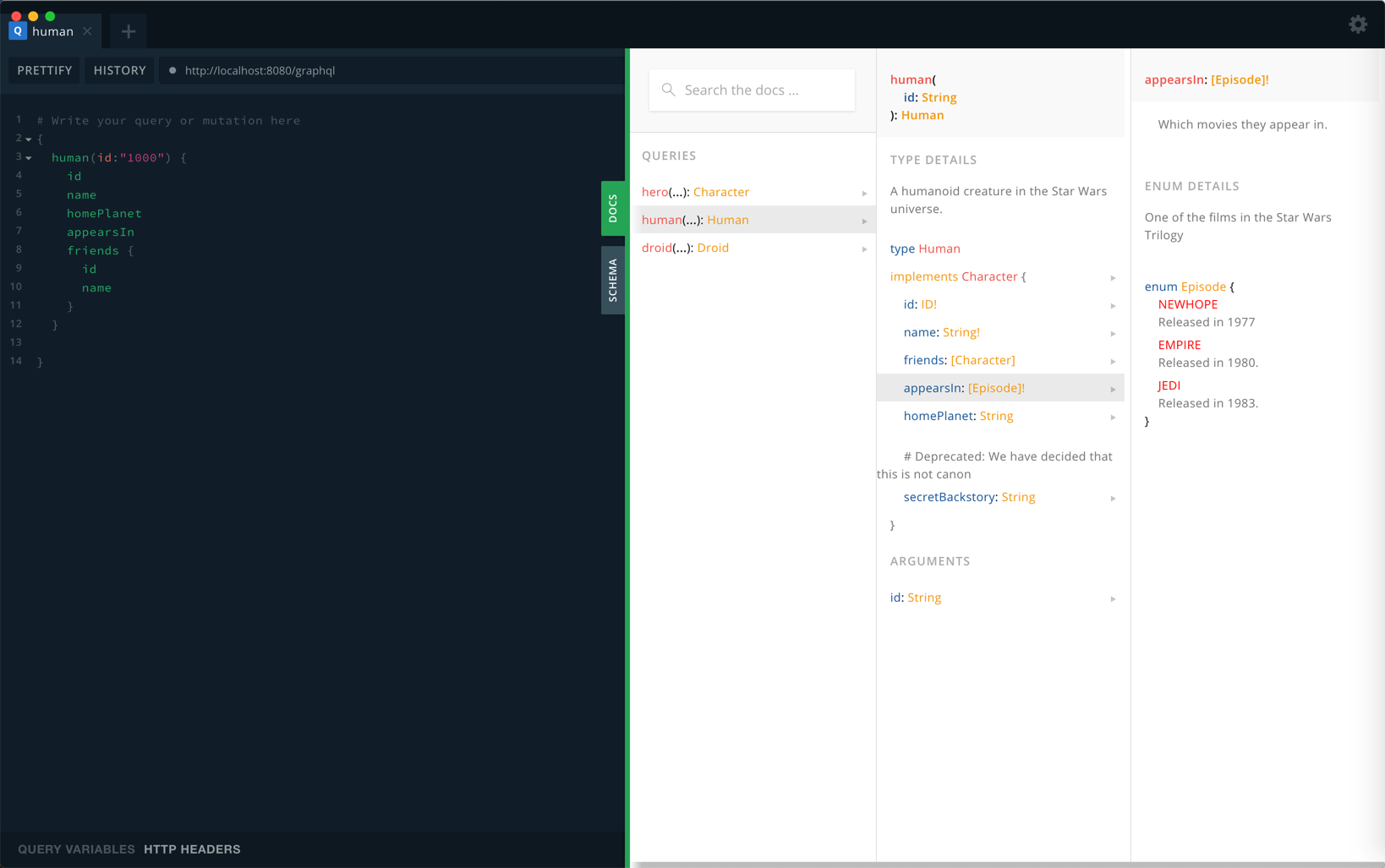
其实就是__schema: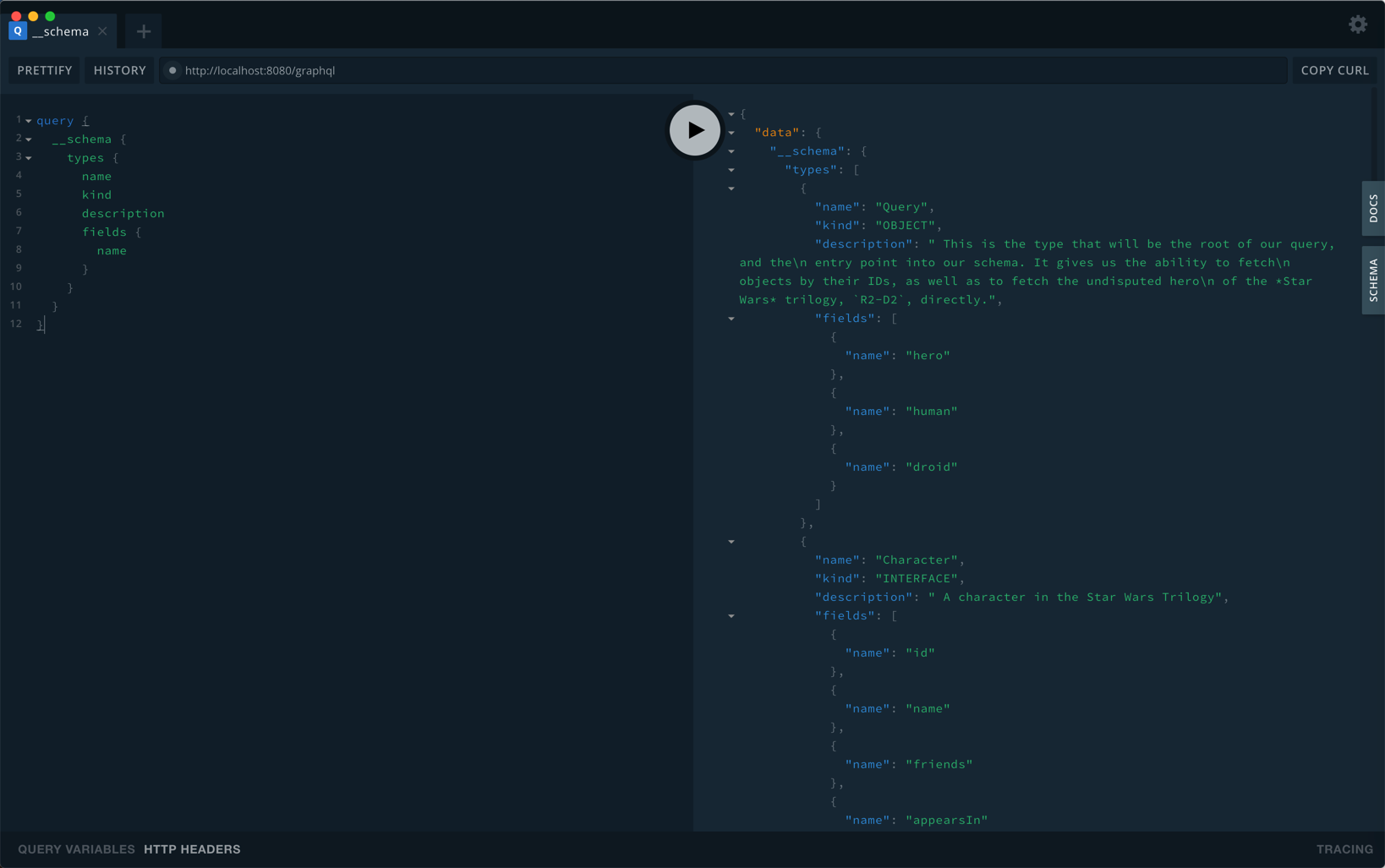
然后我们可以根据客户端的UI需要自己来定义查询请求,服务端会根据客户端给的结构来返回数据: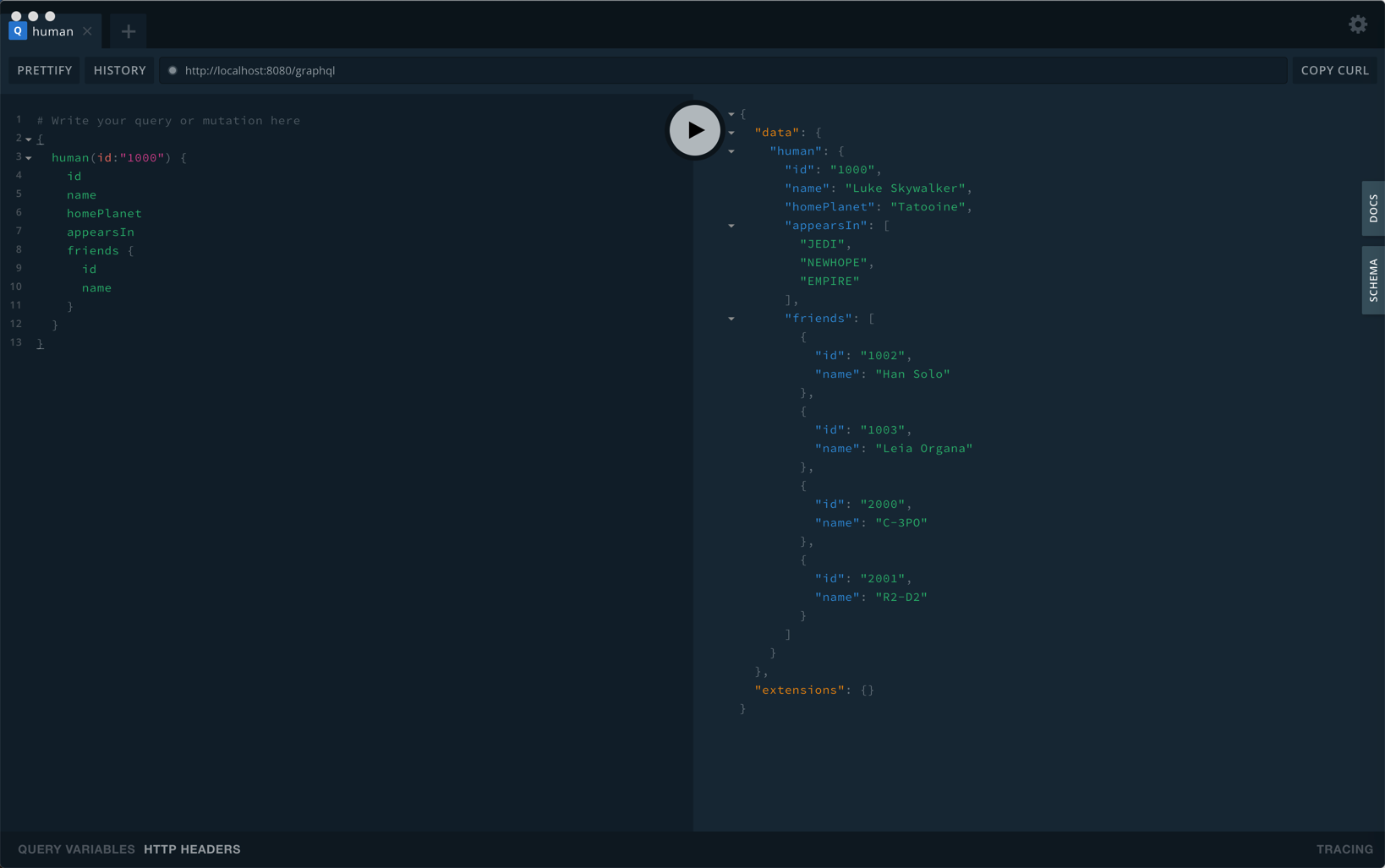
再来看看Github提供的GraphQL(更多参考https://developer.github.com/v4/guides/):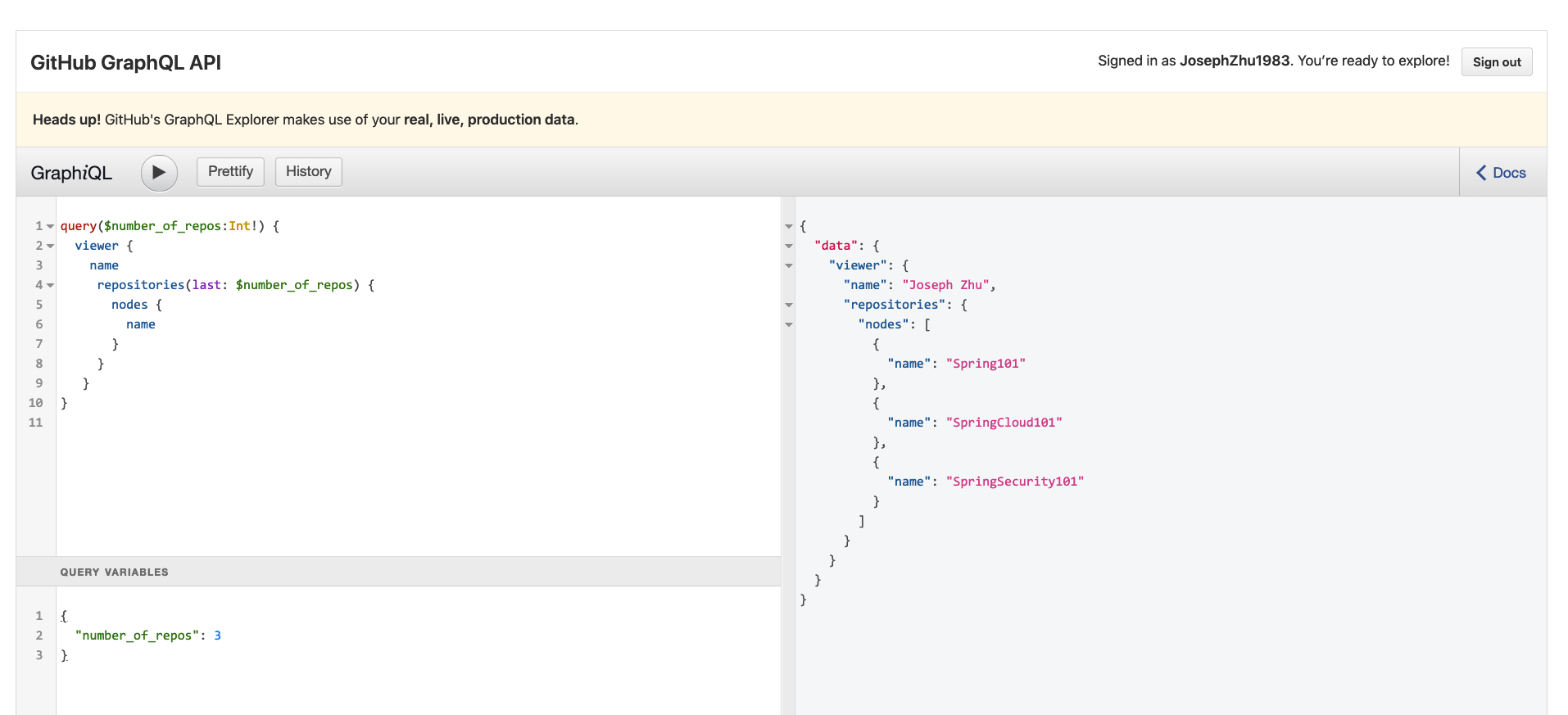
查询出了最后的三个我的repo: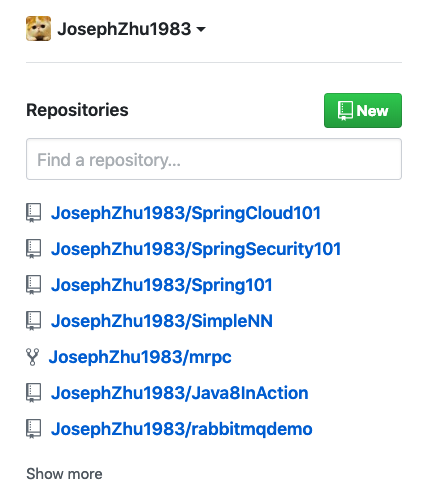
GraphQL就是通过Schema来明确数据的能力,服务端提供统一的唯一的API入口,然后客户端来告诉服务端我要的具体数据结构(基本可以说不需要有API文档),有点客户端驱动服务端的意思。虽然客户端灵活了,但是GraphQL服务端的实现比较复杂和痛苦的,GraphQL不能替代其它几种设计风格,并不是传说中的REST 2.0。更多信息参见 https://github.com/chentsulin/awesome-graphql 。
服务端驱动API
没有高大上的英文缩写,因为这种模式或风格是我自己想出来的,那就是通过API让服务端来驱动客户端,在之前的一些项目中也有过实践。说白了,就是在API的返回结果中包含驱动客户端去怎么做的信息,两个层次:
- 交互驱动:比如包含actionType和actionInfo,actionType可以是toast、alert、redirectView、redirectWebView等,actionInfo就是toast的信息、alert的信息、redirect的URL等。由服务端来明确客户端在请求API后的交互行为的好处是:
- 灵活:在紧急的时候还可以通过redirect方式进行救急,比如遇到特殊情况需要紧急进行逻辑修改可以直接在不发版的情况下切换到H5实现,甚至我们可以提供后台让产品或运营来配置交互的方式和信息
- 统一:有的时候会遇到不同的客户端,iOS、Android、前端对于交互的实现不统一的情况,如果API结果可以规定这部分内容可以彻底避免这个问题
- 行为驱动:更深一层的服务端驱动,可以实现一套API作为入口,让客户端进行调用,然后通过约定一套DSL告知客户端应该呈现什么,干什么。
之前有两个这样的项目采用了类似的API设计方式:
- 贷款审核:我们知道贷款的信用审核逻辑往往会变动比较大,还涉及到客户端的一些授权(比如运营商爬虫),而且App的发布更新往往比较困难(苹果App Store以及安卓各大应用商店的审核问题)。如果采用服务端驱动的架构来告知客户端接下去应该呈现什么界面做什么,那么会有很大的灵活性。
- 客户端爬虫:我们知道如果采用服务端做爬虫很多时候因为IP的问题会被封,所以需要找很多代理。某项目我们想出了客户端共享代理的概念,使用手机客户端来做分布式代理,由服务端驱动调度所有的客户端,那么这个时候客户端需要听从服务端的指示来做请求然后上报响应。
一般而言,对外的Web API是不会采用这种服务端驱动客户端的方式来设计API的。对于某些特殊类型的项目,我们可以考虑采用这种服务端驱动的方式来设计API,让客户端变为一个不含逻辑的执行者,执行的是UI和交互。
选择哪个模式
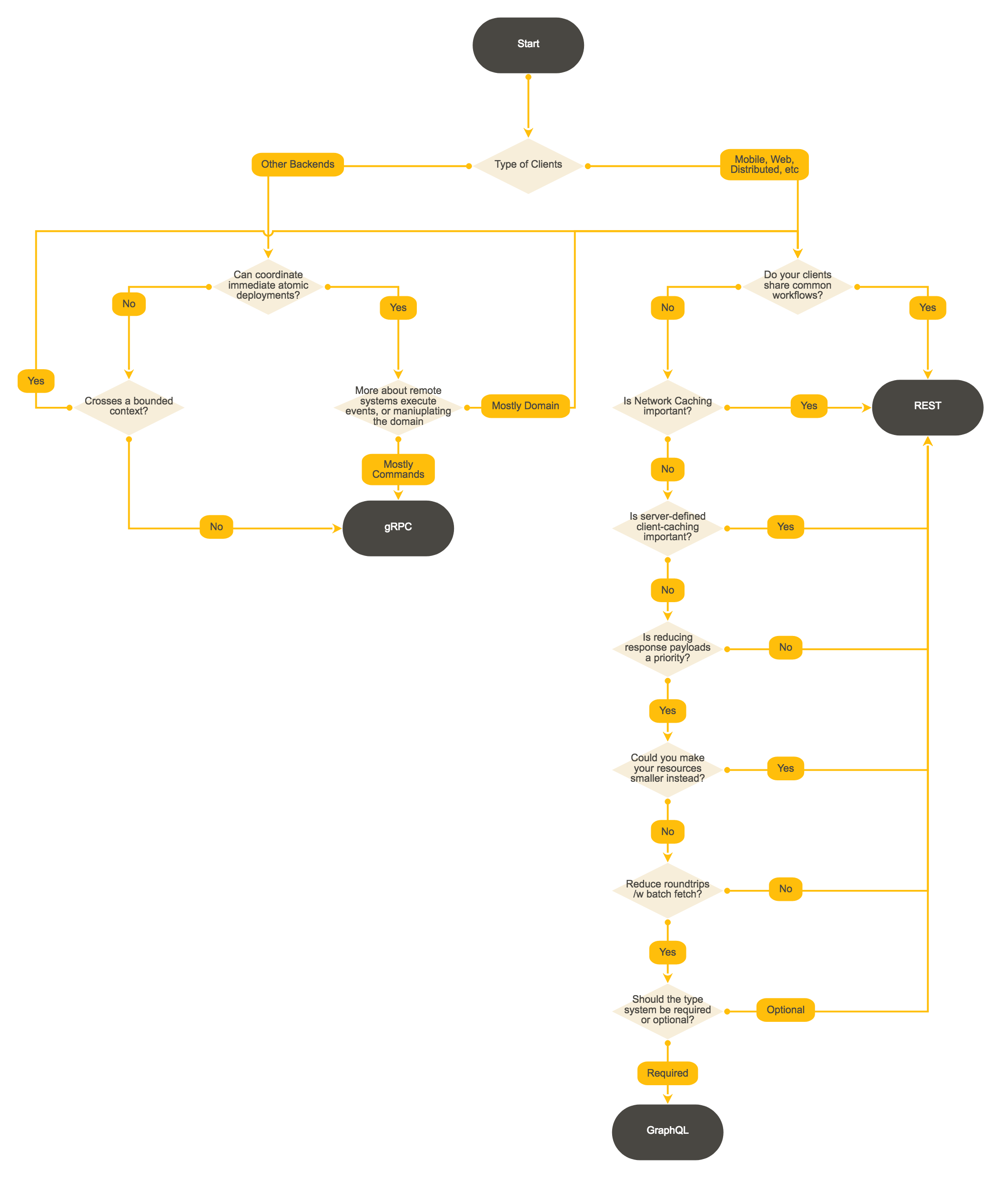
https://user-gold-cdn.xitu.io/2019/2/15/168eff296f015115 此文给出了一个有关RPC、REST、GRAPHQL选择的决策方式可以参考,见上图。
我觉得:
- 在下列情况考虑RPC风格的API或说是RPC:
- 偏向内部的API
- 没有太多的时间考虑API的设计或没有架构师
- 提供的API很难进行资源、对象抽象
- 对性能有高要求
- 在下列情况考虑REST风格:
- 偏向外部API
- 提供的API天生围绕资源、对象、管理展开
- 不能耦合客户端实现
- 在下列情况考虑GraphQL:
- 客户端对于数据的需求多变
- 数据具有图的特点
- 在下列情况考虑服务端驱动:
- 客户端发版更新困难,需要极端的灵活性控制客户端
- 仅限私有API
更多需要考虑的设计点
很多API设计指南都提到了下面这些设计考量点,也需要在设计的时候进行考虑:
版本控制,比如:
- 通过URI Path进行版本控制,比如https://adventure-works.com/v2/customers/3
- 通过QueryString进行版本控制,比如https://adventure-works.com/customers/3?version=2
- 通过Header进行版本控制,比如加一个请求头api-version=1
- 通过Media Type进行版本控制,比如Accept: application/vnd.adventure-works.v1+json
缓存策略,比如:
- 响应使用Cache-Control告知客户端缓存时间(max-age)、策略(private、public)
- 响应使用ETag来进行资源版本控制
部分响应:比如大的二进制文件需要考虑实现HEAD Method来表明资源允许分段下载,以及提供资源大小信息:
HEAD https://adventure-works.com/products/10?fields=productImage HTTP/1.1
HTTP/1.1 200 OK Accept-Ranges: bytes Content-Type: image/jpeg Content-Length: 4580
然后提供资源分段下载功能:
GET https://adventure-works.com/products/10?fields=productImage HTTP/1.1
Range: bytes=0-2499
HTTP/1.1 206 Partial Content Accept-Ranges: bytes Content-Type: image/jpeg Content-Length: 2500 Content-Range: bytes 0-2499/4580 [...]
- 列表设计:需要在设计列表类型API的时候考虑分页、投影、排序、查询几点,值得注意的是列表API的额外功能比较多,尽量进行命名的统一化规范
参考资料
- 微软API设计指南:https://docs.microsoft.com/zh-cn/azure/architecture/best-practices/api-design (英文版: https://docs.microsoft.com/en-us/azure/architecture/best-practices/api-implementation )
- Google Cloud API设计指南: https://google-cloud.gitbook.io/api-design-guide/ (英文版:https://cloud.google.com/apis/design/ )
- Github API概览:https://developer.github.com/v3/
作者: lovecindywang











