前言
为什么我们使用chatgpt问一个问题,回答时,他是一个字或者一个词一个词的蹦出来,感觉是有个人在输入,显得很高级,其实这这一个词一个词蹦不是为了高级感,而是他的实现原理决定的,下面我们看下为什么是一个一个蹦出来的

大模型的本质
特斯拉前AI总监Andrej Karpathy将大语言模型简单的描述为: 大模型的本质就是两个文件,一个是参数文件,一个是包含运行这些参数的代码文件。
参数文件是组成整个神经网络的权重,代码文件是用来运行这个神经网络的代码,可以是C或者其他任何编程语言写的,当然目前主要都是Python

那么接下来的问题就是:参数从哪里来?
这就引到了模型训练。
本质上来说,大模型训练就是对互联网数据进行有损压缩(大约10TB文本),需要一个巨大的GPU集群来完成。
以700亿参数的Llama 2(Facebook开源的羊驼大模型)为例,就需要6000块GPU,然后花上12天得到一个大约140GB的“压缩文件”,整个过程耗费大约200万美元。
而有了“压缩文件”,模型就等于靠这些数据对世界形成了理解。

大模型是如何工作的
简单来说,大模型的工作原理就是依靠这些压缩数据的神经网络对所给序列中的下一个单词进行预测。
比如我们问将“中 华 人民 ”输入进去后,请大模型补充完整,可以想象是分散在整个网络中的十亿、上百亿参数依靠神经元相互连接,顺着这种连接就找到了下一个连接的词,然后给出概率,比如“共和国(97%) ”,就形成了“中华人民共和国”的完整句子。然后继续将“中华人民共和国”作为输入,继续依·靠神经元相互连接,顺着这种连接就找到了下一个连接的词,然后给出概率,比如“中华人民共和国 成立于1949年(98%) ”.

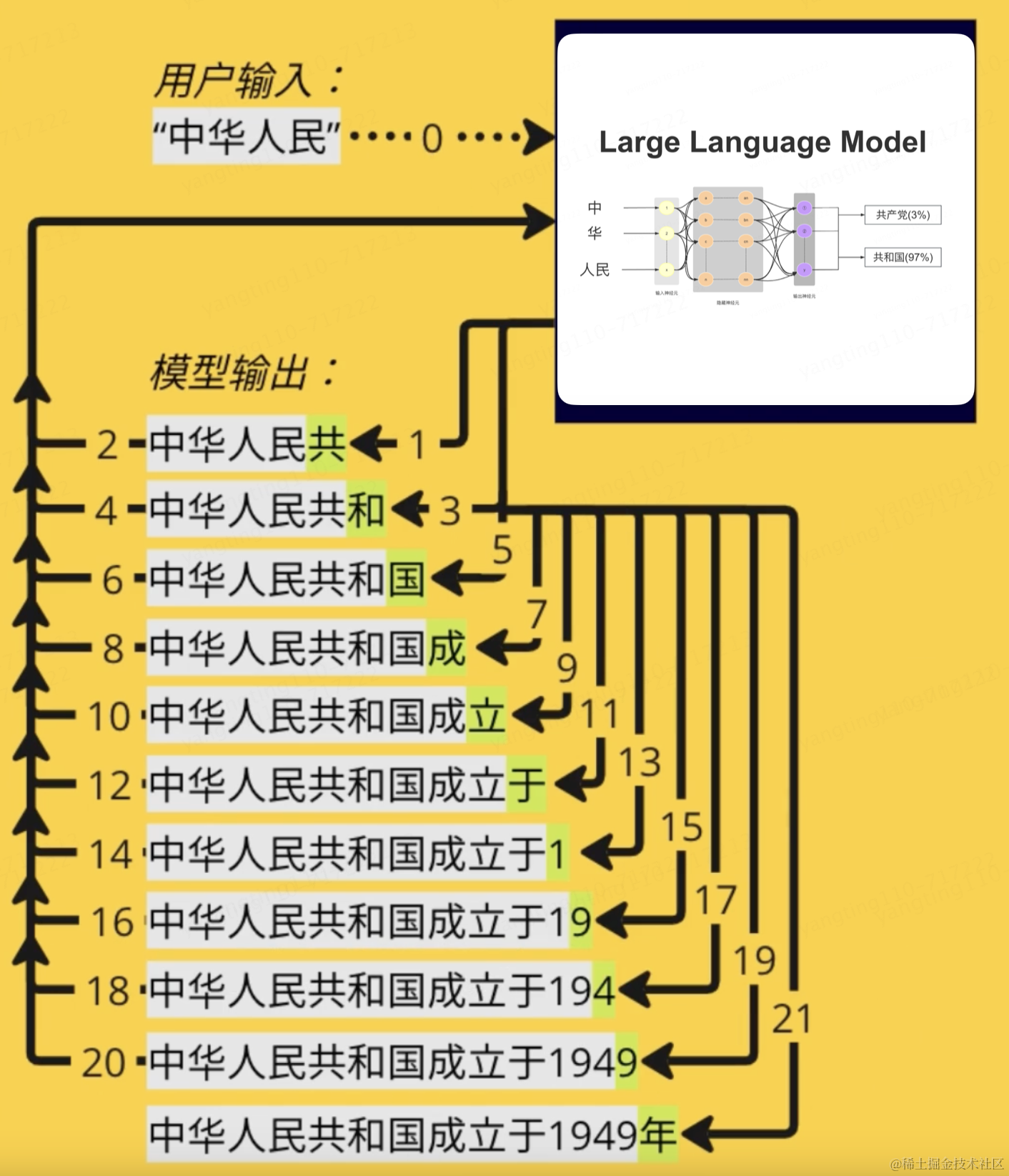
根据维基百科我们可以看到中华人民共和国出现了571次,概率非常大,实际上大模型就是对给出序列的下一个词的概率预测

这就是为什么我们刚才讲大语言模型都是一个词一个词的蹦了,你可以理解大模型就是一个很牛逼的成语接龙大师
那么大模型又是如何训练,并预测下一个词的呢?
神经网络
看到“神经网络”几个字就觉得复杂了不往下看了,别紧张,一点都不复杂,让我们继续看。
历史上,科学家一直希望模拟人的大脑,造出可以思考的机器。人为什么能够思考?科学家发现,原因在于人体的神经网络。
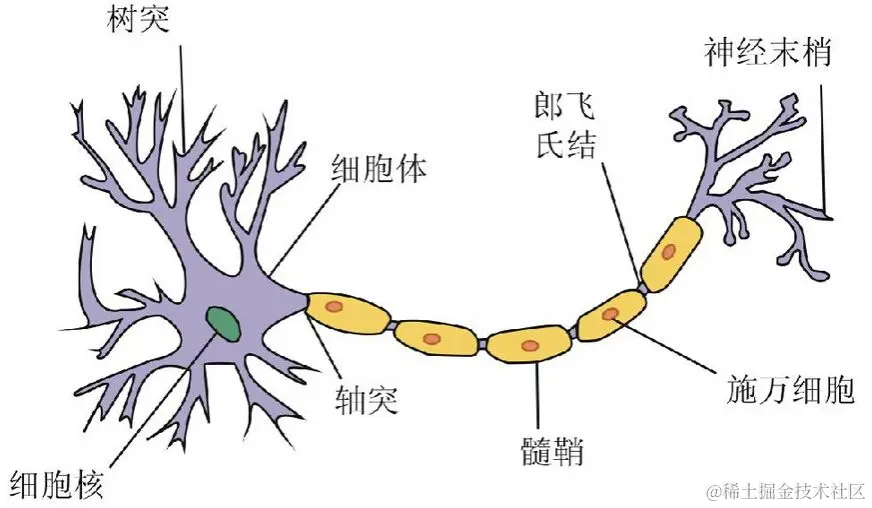
•外部刺激通过神经末梢,转化为电信号,转导到神经细胞(又叫神经元)。
•无数神经元构成神经中枢。
•神经中枢综合各种信号,、做出判断。
•人体根据神经中枢的指令,对外部刺激做出反应。
感知器
最简单的神经网络 “感知器”, 早在1957年就被发明,并使用了.直到今天还在用

上图的圆圈就代表一个感知器。它接受多个输入(x1,x2,x3...),产生一个输出(output),好比神经末梢感受各种外部环境的变化,最后产生电信号。
为了简化模型,我们约定每种输入只有两种可能:1 或 0。如果所有输入都是1,表示各种条件都成立,输出就是1;如果所有输入都是0,表示条件都不成立,输出就是0。
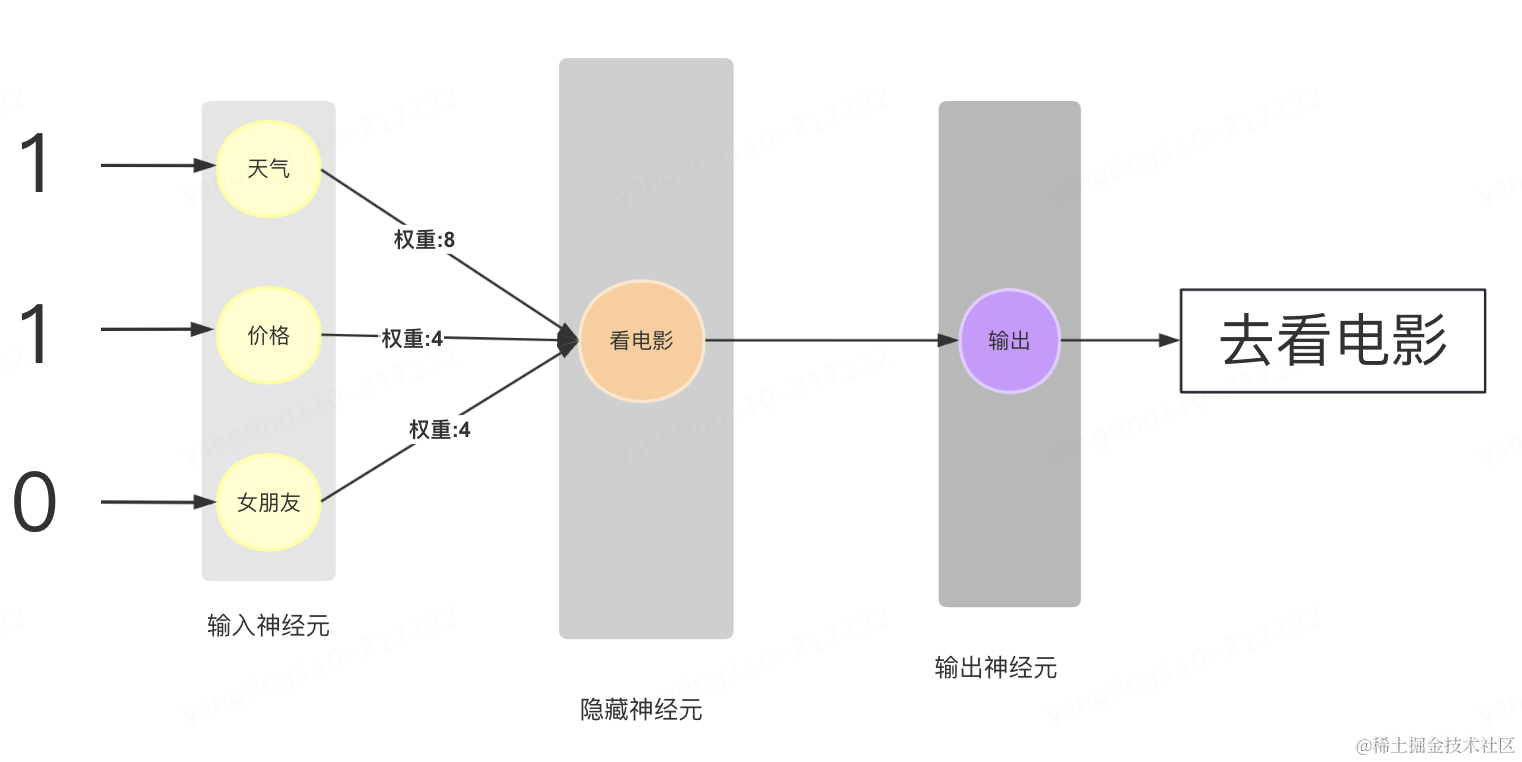
下面来看一个例子。最近刚上映一部好莱坞大片,张三拿不定主意。周末要不要去看电影.
决定他要不要去看电影有三个因素(特征)。
•天气:周末是否晴天?
•价格:票价是否可承受?
•女朋友:能否找到女朋友一起去?
这就构成一个感知器。上面三个因素就是外部输入,最后的决定就是感知器的输出。如果三个因素都是 Yes(使用1表示),输出就是1(去看电影);如果都是 No(使用0表示),输出就是0(不去看电影)。
权重和阈值
那么:如果某些因素成立,另一些因素不成立,输出是什么?比如,周末是好天气,票价也不贵,但是张三找不到女朋友,他还会不会去看电影呢?
现实中,各种因素很少具有同等重要性:某些因素是决定性因素,另一些因素是次要因素。因此,可以给这些因素指定权重(weight),代表它们不同的重要性。
•天气:权重为8
•价格:权重为4
•女朋友:权重为4
上面的权重表示,天气是决定性因素,女朋友和价格都是次要因素。
如果三个因素都为1,它们乘以权重的总和就是 8 + 4 + 4 = 16。
如果天气和价格因素为1,女朋友因素为0,总和就变为 8 + 0 + 4 = 12。
这时,还需要指定一个阈值(threshold)。如果总和大于阈值,感知器输出1,否则输出0。假定阈值为8,那么 12 > 8,小明决定去看电影。阈值的高低代表了意愿的强烈,阈值越低就表示越想去,越高就越不想去。
这就是一个包含了输入层、隐藏层、输出层、权重的一个非常简单的神经网络例子。当然实际场景会比这个更复杂,对于神经网络小白来说,已有了一个感性的认识.
上面图中的连接是神经元中最重要的东西。每一个连接上都有一个权重。
上面我们自定义了几个因素的权重
•天气:权重为8
•价格:权重为4
•女朋友:权重为4
但是实际情况,这个权重我们只是初始化了一个值,通过大量的数据进行训练,然后不断的调整得到的权重值.例如随机利用1万人的习惯数据,他们是否都是天气好的时候去看电影,没女朋友的时候不去看电影等等.这个权重值就是经过训练不断更新得到的.这样就可以预测张三会不会去看电影
这就是一个简单的神经网络,一个神经网络的训练过程就是让权重的值调整到最佳,以使得整个网络的预测效果最好。最终的训练结果可能是“女朋友”这个权重占98,其他都是次要的

玩一玩神经网络
上面我们讲的都是一些简单的例子,下面我们看一个简单神经网络在线演示和实验的平台
TenforFlow Playground 又名 TensorFlow 游乐场,是一个用来图形化教学的简单神经网络在线演示和实验的平台,非常强大且极其易用。如果您已经有一部分神经网络知识,使用此工具,可以快速体验一个算法工程师的调参工作。
在线体验地址: http://playground.tensorflow.org/
开源github地址:https://github.com/tensorflow/playground
下图可简单理解为,正在训练1万人,以天气、价格、女朋友这三个特征,进行训练,判断什么情况下会,人们会去看电影、什么情况下不会去看电影


上图标明了该页面上每个部分的含义,刚开始不用全部都理解,感兴趣再去研究每部分都是干嘛的,下面列了理解该页面的一些解释。
1.运行控制区,这里主要对算法执行进行控制,可以启动、暂停和重置
2.迭代次数展示区,这里展示当前算法执行到了哪一次迭代
3.超参数选择区,这里可以调整算法的一些超参数,不同的超参能解决不同的算法问题,得到不同的效果
4.数据集调整区,数据集定义了我们要解决怎样的问题,数据集是机器学习最为重要的一环,
5.特征向量选择,从数据集中抓取出的可以用来被训练的特征值
6.神经网络区域,算法工程师构建的用于数据拟合的网络
7.预测结果区,展示此算法的预测结果
一些名词解释
•参数: 通常是指网络中可以通过训练数据自动学习和调整的那些数值,例如权重(weights)和偏置(biases)。这些参数是模型在学习过程中不断调整的,以便更好地预测或分类数据。
•超参数:则是指那些控制训练过程本身的参数。不同于模型参数,超参数通常是在训练开始之前设置的,并且在训练过程中保持不变。换句话说,超参数是用来定义模型结构(例如有多少层、每层有多少个神经元)和控制训练过程(例如学习速率、训练轮数)的高级设置。
•线性:指的是一种直接比例关系,即输出直接随输入按固定比例变化。用通俗的话说,就像你加速汽车,速度的增加与你踩油门的力度成正比。比如,假设你的工资是按小时计算的,这时候工资(输出)和工作时间(输入)之间就是线性关系。
•非线性: 则是指输出和输入之间的关系不是直接比例的,即输出不会直接随输入按固定比例变化。通俗来说,就像你对一只橡皮筋施力,开始时很容易拉长,但越往后拉越难,力的增加和橡皮筋的伸长之间就是非线性关系。在现实生活中,很多复杂的现象(如天气变化)都是非线性的。
•激活函数:在神经网络中用来引入非线性因素,使得网络能够学习和模拟复杂的输入与输出之间的关系。简单来说,激活函数就像是决定神经元是否应该被激活(即对信息做出反应)的开关。例如,ReLU(Rectified Linear Unit,修正线性单元)激活函数是一种常用的激活函数,它的作用是:如果输入是正数就原样输出,如果是负数就输出0。这样的非线性特性让神经网络能够处理更加复杂和抽象的任务,比如图像识别和语言处理。
•学习率:是在训练神经网络时用来控制模型学习进度的一个参数。简单讲就是每次给权重添加多少值,如果加的越多,容易学习过头,如果加的太低,学习次数就会变多
•正则化:是一种用于避免模型过拟合的技术,可以理解为给模型训练加上一种约束或者惩罚。
•正则率: (通常用λ表示)则是控制正则化强度的参数。正则率的值越大,对模型复杂度的惩罚就越重,模型就越倾向于更加简单,但过高的正则率可能导致模型过于简单,无法捕捉数据的关键特征,即欠拟合。因此,选择合适的正则率是保持模型泛化能力和拟合能力之间平衡的关键。
特别注意:不是学习的越精准、越没瑕疵越好,过度拟合或导致误判
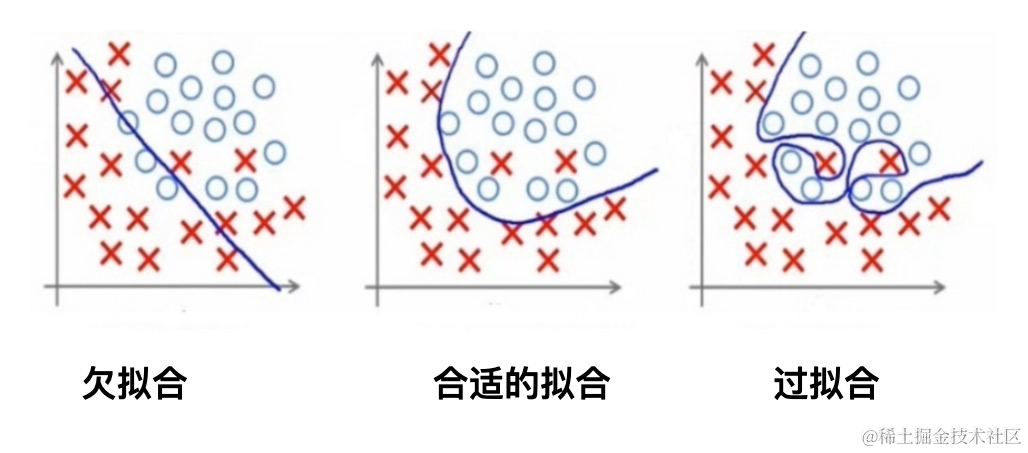
神经网络的学习过程本质上就是在学习数据的分布
Transformer架构(深度学习模型)
有了上面的感性理解后,让我们稍微加一点点难度,理解一下Transformer架构。
目前绝大多数的开源大模型都是基于Transformer架构的。Transformer架构自2017年由Vaswani等人在论文《Attention is All You Need》中提出以来,迅速成为自然语言处理(NLP)领域的主流架构,广泛应用于各种任务,如机器翻译、文本生成、问答系统等等。Transformer模型的核心创新是自注意力机制(Self-Attention Mechanism),这使得模型能够在处理序列数据时,有效地捕捉序列内各元素之间的关系,无论它们在序列中的位置如何远近。
1、向量、矩阵
讲Transformer之前,先回忆一下高中知识:向量、矩阵
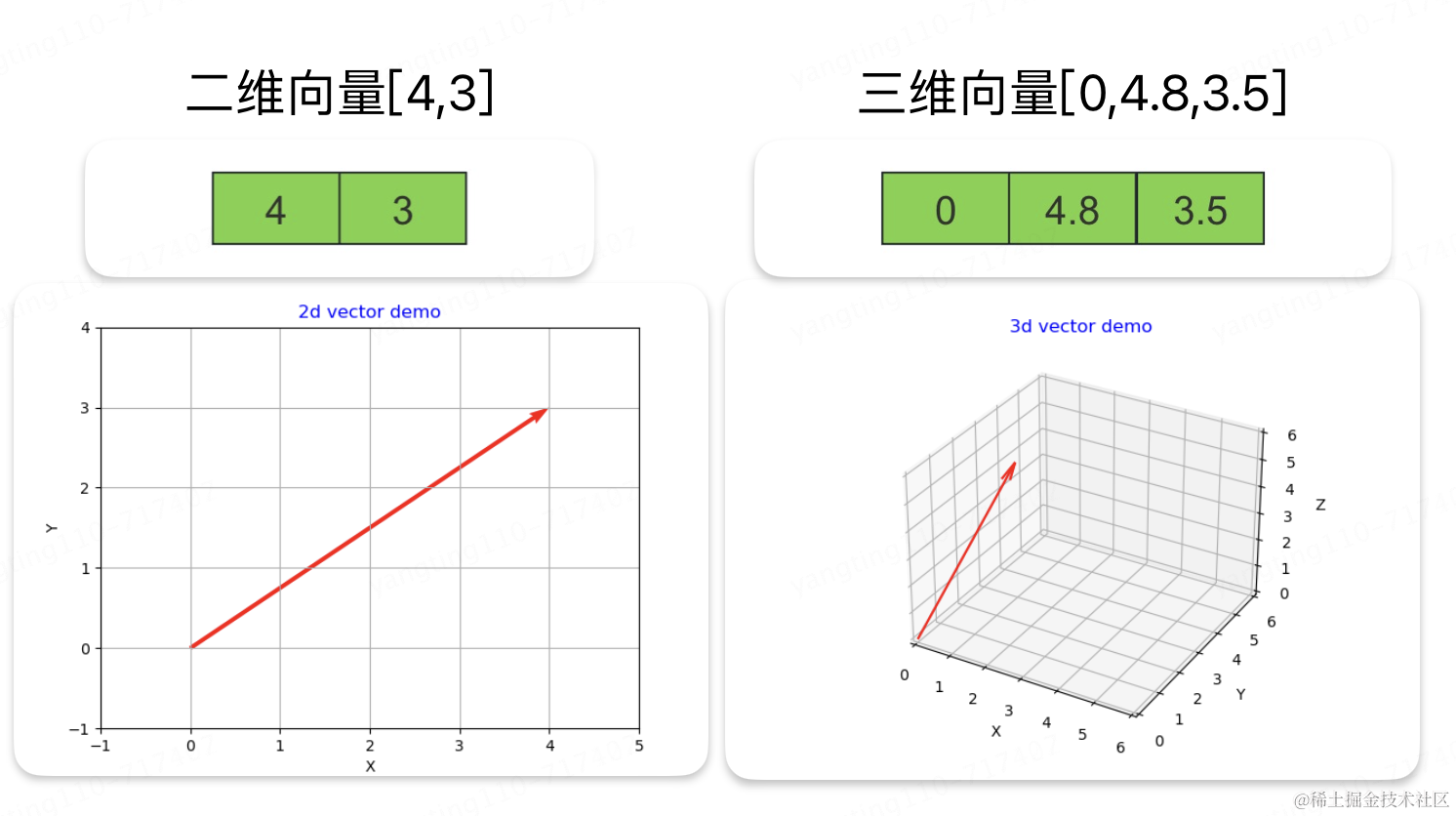
向量相加得到另一个向量,可以理解为两条向量一共走了多少路径,的直线距离

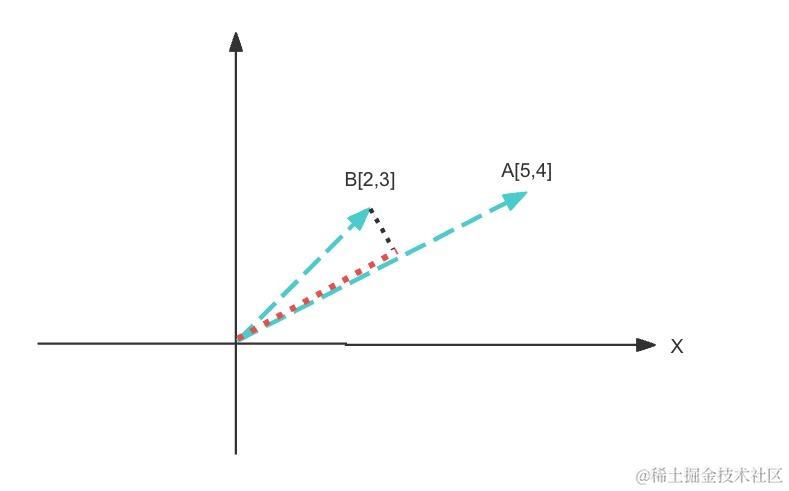
向量相乘,可以看成向量B在向量A的垂线上的正射投影和向量A的长度的乘积
矩阵其实就是多维向量组,如图就是3个向量组成的1个矩阵

矩阵相乘,请查看动画演示
http://matrixmultiplication.xyz/
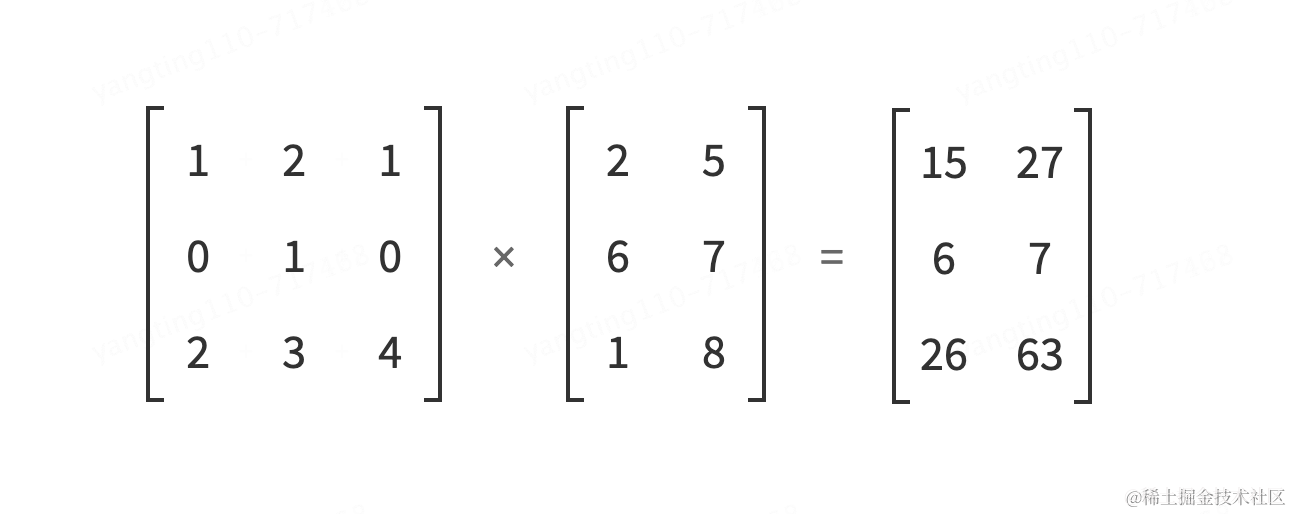
感兴趣并想深入研究的同学,可以自行温习一下向量、向量的加、乘法、三角函数、矩阵、线性代数等基础知识。有以上几张图的基本理解就完全足够理解下面我们即将要讲的大模型核心架构Transformer了。
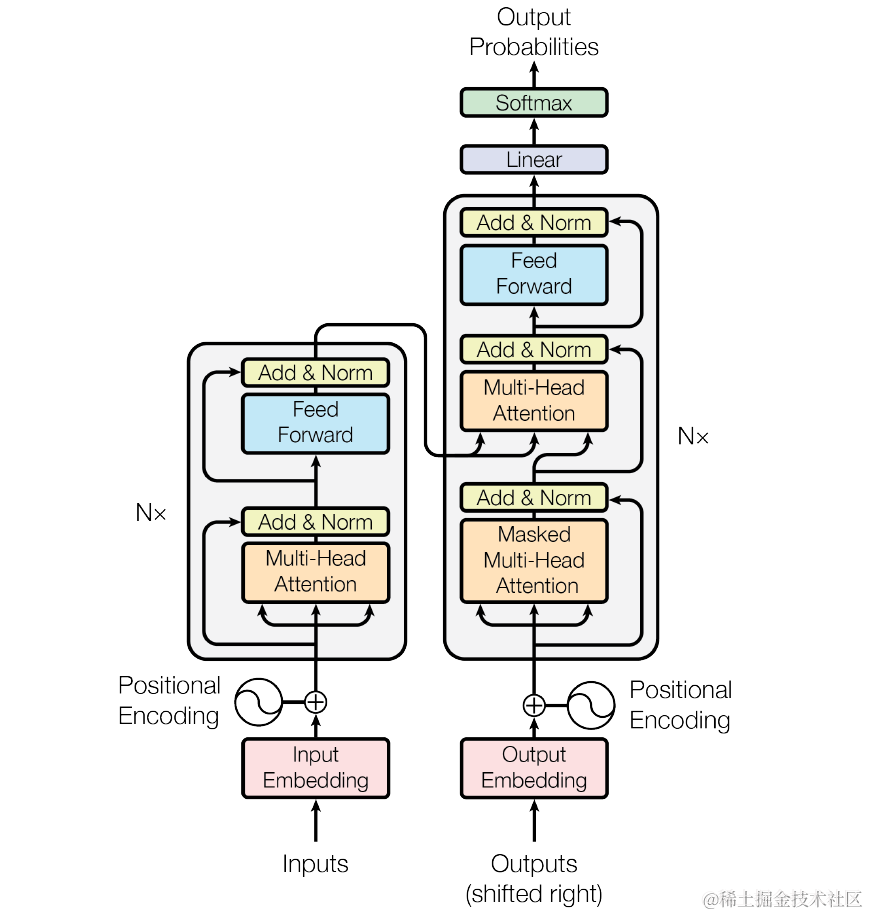
2、Transformer架构图
下图就是一个Transformer的架构图,现在让我们看Transformer时如何实现训练的

从下往上大致分为这样一个流程,样本文字转数字向量--->增加位置信息--->自身的语义关系学习---->数字缩放(归一化)---->输出概率---->对应的文字。下面让我们逐一的来看每一层都做了什么。
3、训练文字的token化与嵌入向量

对输入的文本进行token的数字转换,每个字对应一个从编码库中标记出来的一个token向量.得到一个4行x64列的这么一个矩阵,每一行代表了1个token(1个token其实就是一个向量,chatgpt按token收费,其中的token就是这个意思),每列代表了这个token在不同语义下的1个数字
是如何标记的呢,实际上是通过一张超级大的编码字典表中查找到的.
目前常用的是openai开源的向量查找表库tiktoken
https://github.com/openai/tiktoken
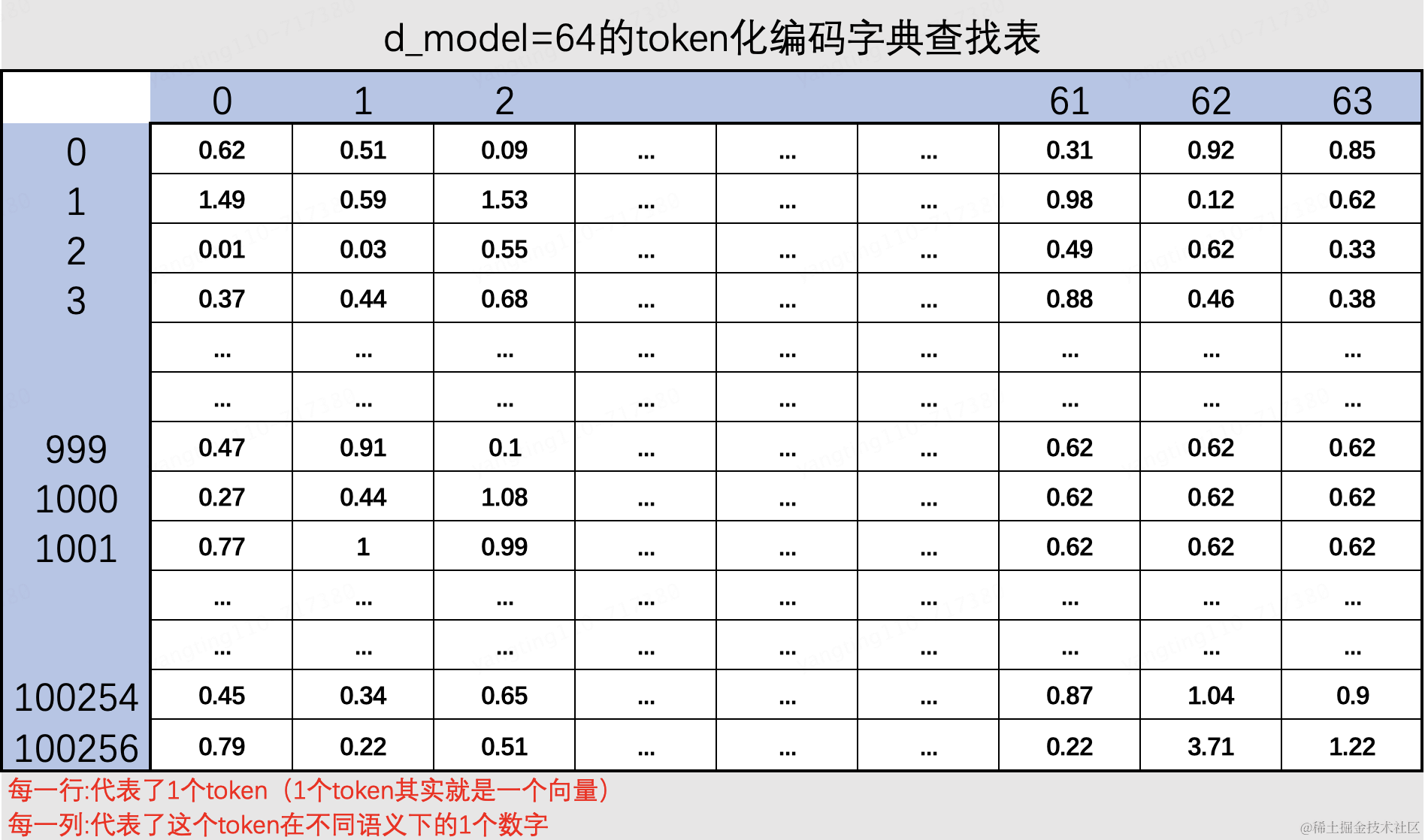
为什么有多列呢?因为每个字可能存在多种意思,例如“思”字, 你是什么意思?我没什么意思,就是意思意思,每个思字是不同含义的.
•输入:样本训练文本。
•输出:token化的词嵌入向量矩阵。
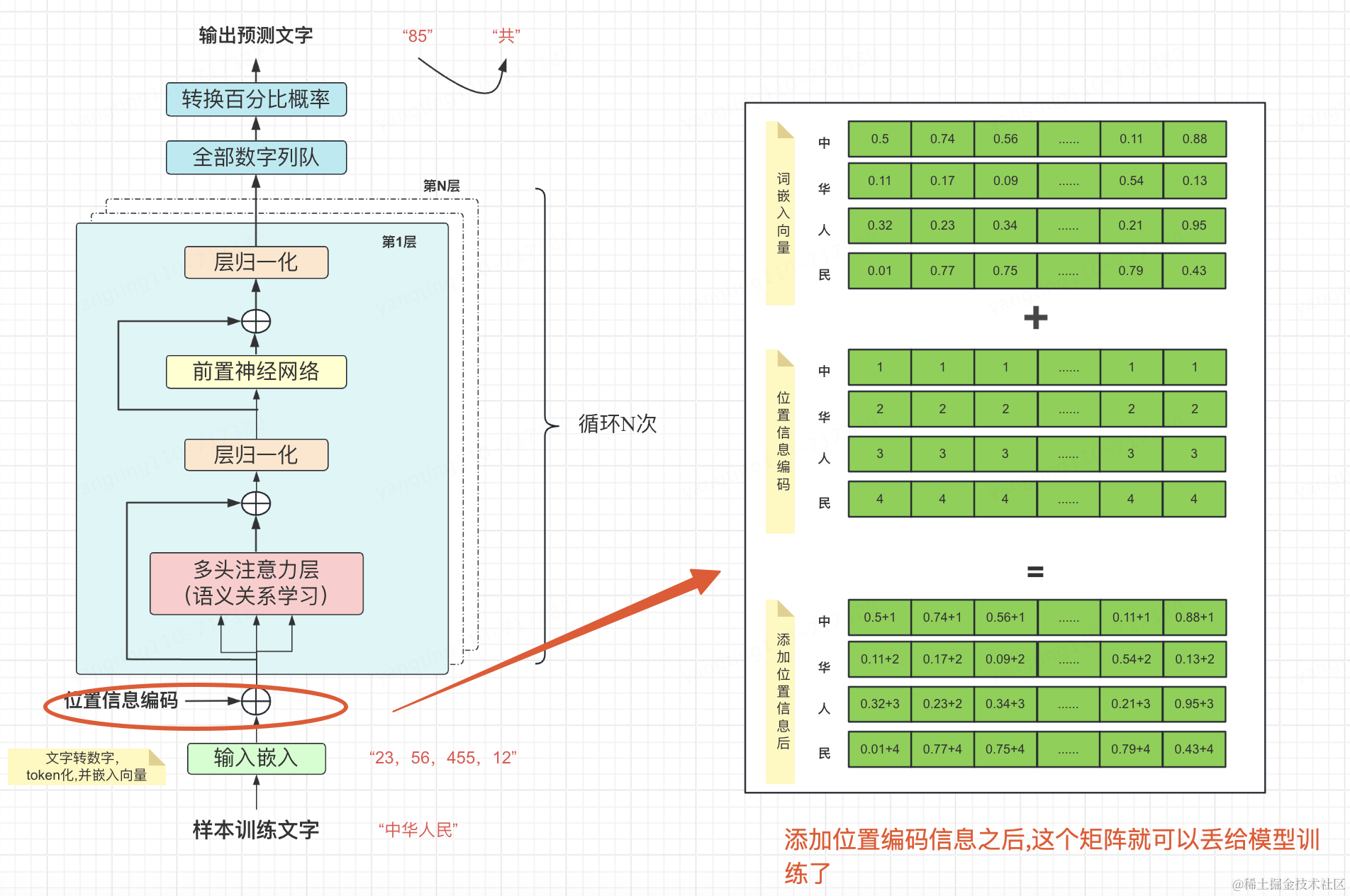
4、位置信息编码
经过token化和嵌入向量得到的数据矩阵还不能给模型训练.
例如,张麻子正在打李麻子,这句话中,通过token化嵌入向量后,不明确“麻子”这个词指代的是哪个麻子,所以需要进行位置编码,需要让我们在训练的过程中即知道token、又知道语义,还需知道位置,怎么引入位置呢?
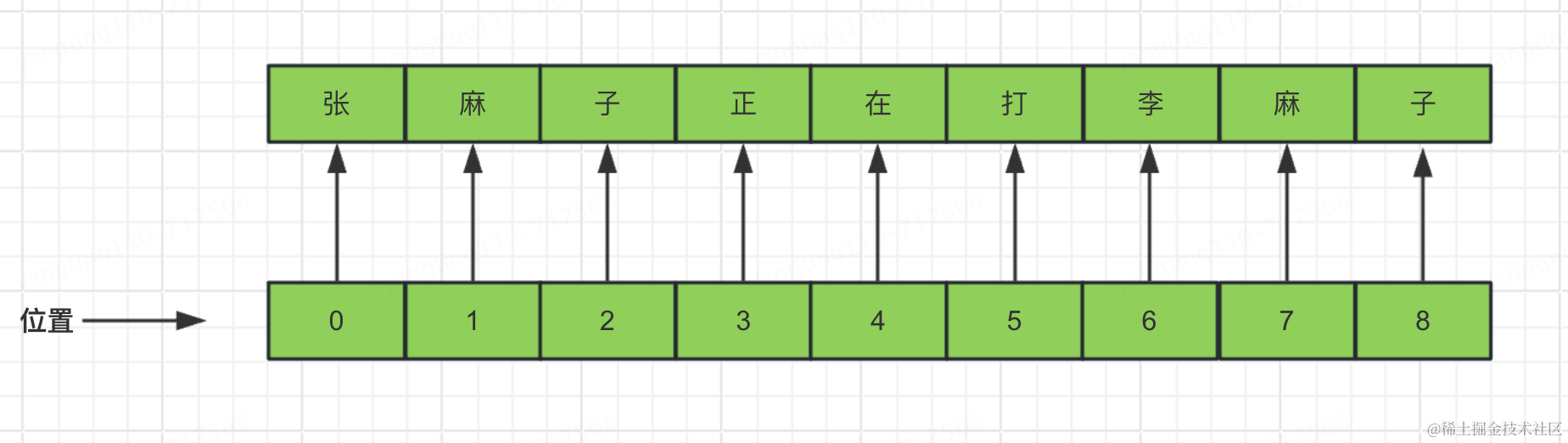
当添加位置信息编码时,不可能像咱们现在这样,每个位置的编码是整数顺序大小的,我们这里只有“中华人民”四个字,所以是1、2、3、4的位置编码,如果我们有1万字,位置编码就会很大,导致向量比较分散,如何解决呢?
sin,cos正好可以拿来做位置编码,因为正弦、余弦的值永远都在-1~1之间
奇数位置:sin(f(x))
偶数位置:cos(f(x))

token矩阵与位置编码矩阵相加,得到的矩阵就可以丢给模型去训练了
•输入:词嵌入向量矩阵。
•输出:通过增加位置编码后,得到可训练的带位置信息的向量矩阵。
5、自注意力机制
注意:这一小节是核心,这一小节是核心,这一小节是核心
汉字的序顺并不定一影阅响读

1.自注意力层让模型能够在处理一个单词时考虑到句子中的其他单词。这使得模型能够捕捉单词之间的关系,比如代词和它所指代的名词。
例子:在处理句子"汉字的序顺并不定一影阅响读"时,自注意力层会帮助模型理解"序"和"顺"的关系。
想象一下,你正在一个聚会上,周围有很多人在聊天。你的大脑会自动地选择性地听某些人的话,这取决于你认为谁的话对当前的对话最重要或最有趣。也就是说,即便所有的声音都进入了你的耳朵,你的大脑还是会“关注”某些特定的声音或信息。这个过程,就有点像自注意力机制在做的事情。
在自然语言处理(NLP)中,当我们给模型输入一个句子,比如:“我爱吃苹果”,模型的目标可能是理解这个句子的意思,或者翻译成另一种语言。自注意力机制允许模型在处理每个词(比如“苹果”)时,不仅考虑这个词本身,还要考虑它与句子中其他词的关系。模型会“关注”句子中的每个词,然后根据这些词之间的关系来决定哪些词是更重要的。
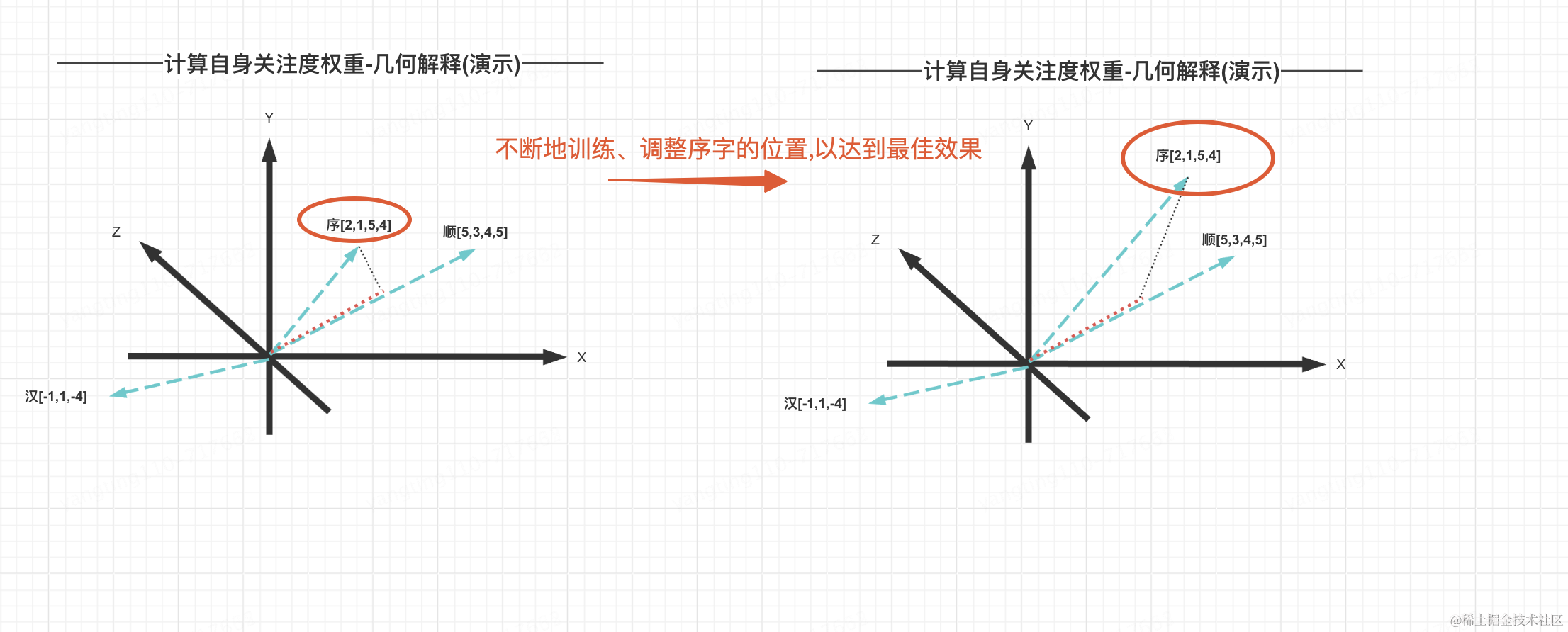
自注意力机制会为句子中的每个词生成一个“权重”,这个权重反映了当前处理的词对句子中其他词的关注程度。比如,在处理“苹果”这个词时,模型可能会给“吃”这个词分配更高的权重,因为这两个词之间有直接的关系。通过这种方式,模型就可以更好地理解每个词在句子中的作用,进而更好地理解整个句子的意思。回到前面的句子“汉字的序顺并不定一影阅响读”,看下图,“顺”字跟句子中其他字之间都会生成一个关系权重,经过大量的训练,“顺”字对“序”字的权重最大。
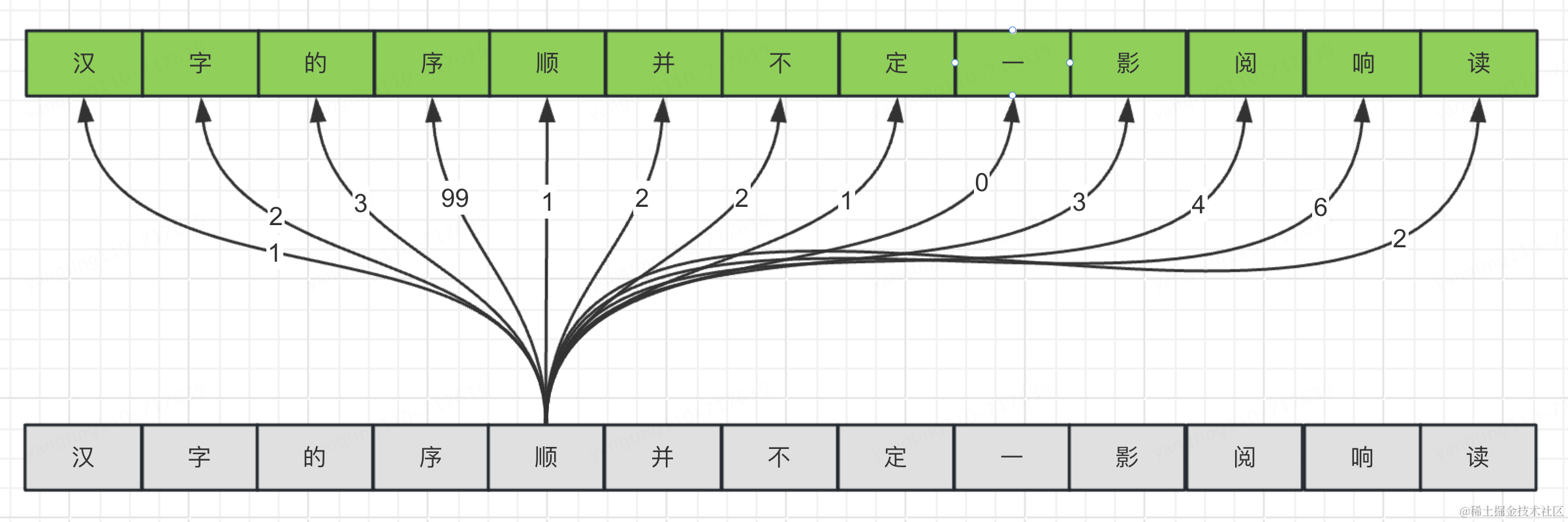
简单来说,自注意力就是模型在处理信息时,能够“自己决定”去关注哪些相关的信息,这样做可以帮助模型更好地理解和处理数据。
如何实现的呢?自注意力机制的核心思想是让每个输入元素(如一个词)能够关注到其他输入元素,从而捕捉到序列中的全局依赖关系。矩阵乘法在自注意力机制中起到了关键作用,使用矩阵相乘,找到位置相似的向量,即最终得到比较合理的权重值

矩阵相乘后,值越大说明词与词之间的关注度越高
大致的训练过程是这样的:“顺”字对“序”字的关注度,是在训练的过程中不断的调整向量坐标(权重),以达到最佳效果
自注意力层实际上做了两件事,1是计算词与词之间的关注度权重,同时加权求和后输出新的矩阵(预测出的词的得分矩阵)
计算词与词之间的关注度权重(Attention Scores) :自注意力机制首先会计算序列中每个词对于其他所有词的关注度权重。这个过程通常涉及将输入序列的每个元素(例如,每个词)转换成三个向量:查询(Query)、键(Key)和值(Value),通过计算查询向量与键向量之间的相似度(通常是点积或某种归一化形式的点积),来得出这些权重。这些权重表明了序列中每个元素对其他元素的重要性程度。
加权求和后输出新的矩阵:一旦计算出关注度权重,自注意力机制会使用这些权重对值(Value)向量进行加权求和,以生成每个位置新的表示。这个过程实质上是根据每个元素对序列中其他元素的关注度,重新组合了原始信息。这样,输出的新矩阵中的每个元素都融合了整个序列的信息,反映了序列内部的复杂依赖关系。
•输入:一个表示序列的矩阵 ( X )。
•线性变换:生成查询(Q)、键(K)、和值(V)矩阵。
•注意力计算:并计算词之间的关注度权重。
•输出:通过注意力权重对值矩阵 ( V ) 进行加权求和,得到自注意力机制的输出矩阵。
6、 归一化注意力分数
归一化是一种将数据按照一定规则缩放到一个特定范围(通常是0到1之间或者是-1到1之间)的过程。这个过程可以帮助我们在处理数据时,减少数据之间因为量纲(单位大小)不同带来的影响,使得数据之间的比较或者计算更加公平和合理。同时提高训练速度和稳定性
归一化后的注意力分数可以被解释为概率,表示一个词关注另一个词的程度。
神经网络的学习过程本质上是在学习数据的分布,如果没有进行归一化的处理,那么每一批次的训练数据的分布是不一样的,
•从大的方向上来看,神经网络则需要在这多个分布当中找到平衡点
•从小的方向上来看 ,由于每层的网络输入数据分布在不断地变化 ,那么会导致每层网络都在找平衡点,显然网络就变得难以收敛。
下图中,我们可以看到数据归一化后的效果。 原始值(蓝色)现在以零(红色)为中心。 这确保了所有特征值现在都处于相同的比例。

例子说明归一化:
再举个简单的例子,假设一个班级里有5个学生参加了一次考试,分数分别是
学生A=90分
学生B=80分
学生C=70分
学生D=60分
学生E=50分
这个分数比较大,对于如果我们想将这些分数归一化到0到1之间,我们可以将每个学生的分数减去最低分50分,然后再除以最高分和最低分的差值,即40分(90-50)。这样,90分就变成了1((90-50)/40),50分就变成了0((50-50)/40),其他分数也会相应转换到0到1之间的某个值。这个过程就是归一化。通过归一化,我们可以更直观地看出每个学生的成绩在班级中的相对位置。
7、 前馈神经网络
通过以上步骤,输出的内容基本都是向量矩阵,都是线性的,并且每个词都是独立处理的,单词之间没有信息的交换,然而,前馈神经网络可以访问之前由头注意力复制的任何信息。前馈层由神经元组成,这些神经元是可以计算其输入加权和的数学函数。前馈层之所以强大,是因为它有大量的连接。例如,GPT-3 的前馈层要大得多:输出层有 12288 个神经元(对应模型的 12288 维词向量),隐藏层有 49152 个神经元。
自注意力机制:在这一步,每个词会观察周围的词,以找出与自己相关的上下文信息。
前馈神经网络:在这一步,每个词会根据自己收集到的上下文信息,进行信息的整合和处理。

在数学和物理学中,非线性是指任何不遵循加法原理(输出不是输入的直接倍数)或者乘法原理(系统的响应不是输入的简单线性组合)的现象。
8、 训练与推理
以上训练过程实际上就是我们文章开头提到的“大模型训练就是对互联网数据进行有损压缩”的有损压缩的过程。
•训练: 是指使用大量的数据对模型进行学习和优化的过程。在这个过程中,模型学习数据中的模式、特征、规律等,调整自身的参数以尽可能准确地对各种输入做出预测或输出。
•推理: 则是在训练完成后,将新的数据输入到已训练好的模型中,让模型基于其学到的知识和模式进行计算、分析并给出相应的输出或预测结果。可以说训练是让模型具备能力,而推理是运用这种能力来处理具体的任务和问题。
其实上面我们只讲了大模型训练的过程,没有讲推理的过程,推理的过程跟训练的过程大致相同,相差就是训练的过程是沉淀结果,推理是直接计算完成之后输出,并沉淀结果。感兴趣的同学可以自己下来,我们网上经常看到的Transformer架构图如下,左边是输入,右边是输出,可以看出输入、输出的中间部分基本是相同的
我们可以简单理解左边部分时训练的过程、右边部分时推理的过程.时间关系,推理的过程咱们先不讲了,感兴趣的同学可以下去看看