
1 Checksum
1.1 checksum原理
checksum table的原理是对表中的数据进行一行一行的较验和计算,在执行checksum命令时,表会被加一个读锁(read lock),因此对于大表,这是一个很耗时的过程。
读锁:又叫S锁/共享锁;当MySQL的一个进程为某一表开启读锁之后,其他的进程包含自身都没有权利去修改这表表的内容。但是所有的进程还是可以读出表里面的内容的。但是不能实现更新。
1.2 语法
在数据库中输入checksum table 库.表;
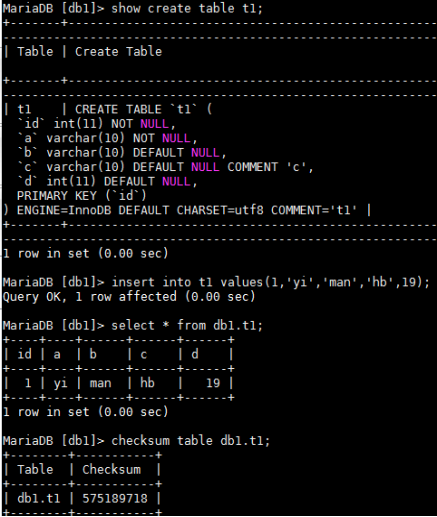
说明:checksum无法对表结构,表属性等进行检查,只对表中的数据进行检验;
2 mysqldiff
mysqldiff该工具是官方mysql-utilities工具集的一个脚本,可以用来对比不同数据库之间的表结构,或者同个数据库间的表结构,并生成差异SQL语句。mysqldiff 是通过对象名称(有表,索引,视图,图表,缺省值,规则,触发器,用户,函数,存储过程等)来进行比较的;
2.1 mysqldiff安装
#wget https://cdn.mysql.com/archives/mysql-utilities/mysql-utilities-1.6.5.tar.gz
#tar xf mysql-utilities-1.6.5.tar.gz
#cd mysql-utilities-1.6.5
#python setup.py build
#python setup.py install
#mysqldiff --version
2.2 语法
语法示例:
#mysqldiff --server1=user:pass@host:port:socket --server2=user:pass@host:port:socket db1.object1:db2.object1 db3:db4
这个语法有两个用法:
db1.object1:db2.object1:如果指定了具体表对象,那么就会详细对比两个表的差异,包括表名、字段名、备注、索引、大小写等所有的表相关的对象。
db3:db4:如果只指定数据库,那么就将两个数据库中互相缺少的对象显示出来,不比较对象里面的差异。这里的对象包括表、存储过程、函数、触发器等。
2.3 主要参数
- --server1:配置server1的连接。
- --server2:配置server2的连接。
- --character-set:配置连接时用的字符集,如果不显示配置默认使用character_set_client。
- --width:配置显示的宽度。
- --skip-table-options:保持表的选项不变,即对比的差异里面不包括表名、AUTO_INCREMENT(自增)、ENGINE(存储引擎)、CHARSET(配置连接时用的字符集)等差异。
- -v, --verbose:控制显示多少信息。例如,- v =冗长,-vv=更详细,-vvv=调试;
- -d DIFFTYPE,--difftype=DIFFTYPE:差异的信息显示的方式,有[unified|context|differ|sql],默认是unified。如果使用sql,那么就直接生成差异的SQL,这样非常方便。
输出类型,也就是difftype选项值:
(1)unified (默认)显示统一的格式输出;
(2)context以上下文格式输出;
(3)differ以differ-style 格式输出;
(4)sql以生成转换SQL语句输出;
- --changes-for=:修改对象。例如--changes-for=server2,那么对比以sever1为主,生成的差异的修改也是针对server2的对象的修改。
- --show-reverse:在生成的差异修改里面,同时会包含server2和server1的修改。
2.4 对比效果
注意:发现运行时需要用户有spuer权限,否则无法运行,后面的工具都是如此;
示例1:
1)表test1和test2对比,显示test2的不同,以及对test2的sql修改
1 mysqldiff --server1=root:0@localhost --server2=root:0@localhost --changes-for=server2 --difftype=sql study.test1:study.test2
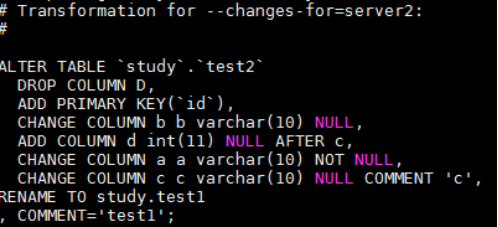
注意:以SQL输出的限制有:
1.对于分区表,如果分区表有差异,将对所有的改变生产。
2.ALTER TABLE 语句,显示经过并省略分区差异。
3.事件重命名不支持。
4.不支持事务定义的条款。
5.不支持MySQL Cluster 的SQL扩展特性。
示例2:
(2)输出类型对比,输出类型,也就是difftype选项值:
1.unified (默认)显示统一的格式输出;
2.context以上下文格式输出;
3.differ以differ-style 格式输出;
4.sql以生成转换SQL语句输出;
1.输出类型(默认)--difftype=unified;
mysqldiff --server1=root:0@localhost --server2=root:0@localhost --changes-for=server2 study.test1:study.test2
2.输出类型--difftype=context;
mysqldiff --server1=root:0@localhost --server2=root:0@localhost --changes-for=server2 --difftype=context study.test1:study.test2
3.输出类型--difftype=differ;
mysqldiff --server1=root:0@localhost --server2=root:0@localhost --changes-for=server2 --difftype=differ study.test1:study.test2
4.输出类型--difftype=sql;
mysqldiff --server1=root:0@localhost --server2=root:0@localhost --changes-for=server2 --difftype=sql study.test1:study.test2
示例3:
如果需要生成SQL文件,加上输出就可以;
mysqldiff --server1=root:0@localhost --server2=root:0@localhost --changes-for=server2 --difftype=sql study.test1:study.test2 > output.sql
3 mysqldbcompare
mysqldbcompare该工具是官方mysql-utilities工具集的一个脚本,可以用来检查不同数据库之间的数据一致性,检查内容包括数据库字符集、表结构、数据内容,只要有一个不一样,则检查不通过。
数据库中的对象包括:表、视图、触发器、存储过程、函数和事件。每一个对象类型计数可以使用-vv选项显示。
3.1 mysqldbcompare安装
#wget https://cdn.mysql.com/archives/mysql-utilities/mysql-utilities-1.6.5.tar.gz
#tar xf mysql-utilities-1.6.5.tar.gz
#cd mysql-utilities-1.6.5
#python setup.py build
#python setup.py install
#mysqldiff --version
说明:mysqldiff和mysqldbcompare都是mysql-utilities工具集的脚本,故只要一次安装即可,两个命令都有;
3.2 语法
语法示例:
#mysqldbcompare --server1=user:pass@host:port:socket --server2=user:pass@host:port:socket db1:db2
Mysqldbcompare和mysqldiff语法结构相似,可以参照mysqldiff;
3.3 主要参数
- --server1:MySQL服务器1配置。
- --server2:MySQL服务器2配置。如果是同一服务器,--server2可以省略。
- db1:db2:要比较的两个数据库。如果比较不同服务器上的同名数据库,可以省略:db2。
- --all:比较所有两服务器上所有的同名数据库。--exclude排除无需比较的数据库。
- --run-all-tests:运行完整比较,遇到第一次差异时不停止。
- --changes-for=:修改对象。例如--changes-for=server2,那么对比以sever1为主,生成的差异的修改也是针对server2的对象的修改。
- -d DIFFTYPE,--difftype=DIFFTYPE:差异的信息显示的方式,有[unified|context|differ|sql],默认是unified。如果使用sql,那么就直接生成差异的SQL。
- -v, --verbose:控制显示多少信息。例如,- v =冗长,-vv=更详细,-vvv=调试;
- --show-reverse:在生成的差异修改里面,同时会包含server2和server1的修改。
- --skip-table-options:保持表的选项不变,即对比的差异里面不包括表名、AUTO_INCREMENT、ENGINE、CHARSET等差异。
- --skip-diff:跳过对象定义比较检查。所谓对象定义,就是CREATE语句()里面的部分,--skip-table-options是()外面的部分。
- --skip-object-compare:默认情况下,先检查两个数据库中相互缺失的对象,再对都存在对象间的差异。这个参数的作用就是,跳过第一步,不检查相互缺失的对象。
- --skip-checksum-table:数据一致性验证时跳过CHECKSUM TABLE。
- --skip-data-check:跳过数据一致性验证。
- --skip-row-count:跳过字段数量检查。
- --disable-binary-logging 如果服务器上启用二进制日志,不想比较日志这步,可以使用选项来禁用。
3.4 对比效果
示例1:
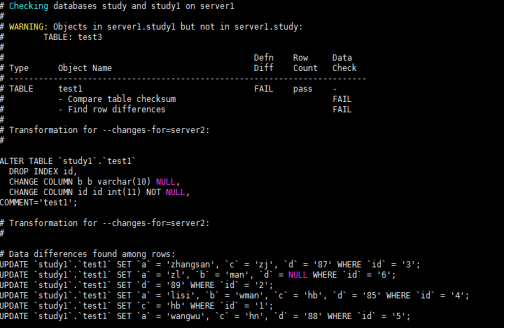
库study和study1对比,显示study1的不同,以及对study1的sql修改
mysqldbcompare --server1=root:0@localhost --server2=root:0@localhost --changes-for=server2 --difftype=sql --run-all-tests study:study1
4 pt-table-checksum
pt-table-checksum其原理是在主库执行基于statement的sql语句来生成主库数据块的checksum,把相同的sql语句传递到从库执行,并在从库上计算相同数据块的checksum,最后,比较主从库上相同数据块的checksum值,由此判断主从数据是否一致。检测过程根据唯一索引将表按row切分为块(chunk),以为单位计算,可以避免锁表。检测时会自动判断复制延迟、 master的负载, 超过阀值后会自动将检测暂停,减小对线上服务的影响。
4.1 安装
#yum -y install perl-DBI perl-devel perl-DBD-MySQL perl-IO-Socket-SSL.noarch perl-Time-HiRes perl perl-Digest-MD5 perl-TermReadKey
#wget https://www.percona.com/downloads/percona-toolkit/3.0.11/binary/tarball/percona-toolkit-3.0.11_x86_64.tar.gz
#tar xf percona-toolkit-3.0.11_x86_64.tar.gz
#cd percona-toolkit-3.0.11
#perl Makefile.PL
#make
#make install
4.2 常用参数
- --nocheck-replication-filters :不检查复制过滤器,建议启用。后面可以用--databases来指定需要检查的数据库。
- --no-check-binlog-format : 不检查复制的binlog模式,要是binlog模式是ROW,则会报错。
- --replicate-check-only :只显示不同步的信息。
- --replicate= :把checksum的信息写入到指定表中,建议直接写到被检查的数据库当中。
- --create-replicate-table 选项会自动创建 percona.checksums 表
- --databases= :指定需要被检查的数据库,多个则用逗号隔开。
- --tables= :指定需要被检查的表,多个用逗号隔开
- --empty-replicate-table:每个表checksum开始前,清空它之前的检测数据(不影响其它表的checksum数据),默认yes。当然如果使用--resume启动检测数据不会清空。当启用--noempty-replicate-table即不清空时,不计算计算chunk,只计算。
- --recursion-method:发现从库的方式;
- h= :Master的地址
- u= :用户名
- p=:密码
- P= :端口
4.3 注意事项
1)第一次运行的时候需要加上--create-replicate-table参数,生成checksums表!!如果不加这个参数,那么就需要在对应库下手工添加这张表了,表结构SQL如下:
create database db5;
use db5;
CREATE TABLE checksums (
db char(64) NOT NULL,
tb1 char(64) NOT NULL,
chunk int NOT NULL,
chunk_time float NULL,
chunk_index varchar(200) NULL,
lower_boundary text NULL,
upper_boundary text NULL,
this_crc char(40) NOT NULL,
this_cnt int NOT NULL,
master_crc char(40) NULL,
master_cnt int NULL,
ts timestamp NOT NULL,
PRIMARY KEY (db, tb1, chunk),
INDEX ts_db_tb1 (ts, db, tb1)
) ENGINE=InnoDB;
2)授权
(1)根据测试,需要一个即能登录主库,也能登录从库的账号;
(2)只能指定一个host,必须为主库的IP;
(3)在检查时会向表加S锁(读锁/共享锁);
(4)运行之前需要从库的同步IO和SQL进程是YES状态(show slave status\G;)。
4.4 pt-table-checksum使用梳理
(1)对特定表一致性进行检查
pt-table-checksum --nocheck-replication-filters --no-check-binlog-format --replicate=percona.checksums --create-replicate-table --databases=study --tables=test1 h=192.168.122.65,u=jin,p=123456,P=3306

解释:
TS :完成检查的时间。
ERRORS :检查时候发生错误和警告的数量。
DIFFS :0表示一致,1表示不一致。当指定--no-replicate-check时,会一直为0,当指定--replicate-check-only会显示不同的信息。
ROWS :表的行数。
CHUNKS :被划分到表中的块的数目。
SKIPPED :由于错误或警告或过大,则跳过块的数目。
TIME :执行的时间。
TABLE :被检查的表名。
(2)对特定数据库的一致性进行检查
pt-table-checksum --nocheck-replication-filters --replicate=percona.checksums --no-check-binlog-format --databases=’study,study1’ h=192.168.122.65,u=jin,p=123456,P=3306
4.5 pt-table-sync用法梳理
如果通过pt-table-checksum 检查找到了不一致的数据表,那么如何同步数据呢?即如何修复MySQL主从不一致的数据,让他们保持一致性呢?
这时候可以利用另外一个工具pt-table-sync。
pt-table-sync: 高效的同步MySQL表之间的数据,他可以做单向和双向同步的表数据。他可以同步单个表,也可以同步整个库。它不同步表结构、索引、或任何其他模式对象。所以在修复一致性之前需要保证他们表存在。
(1)参数解释:
- --replicate= :指定通过pt-table-checksum得到的表,这2个工具差不多都会一直用。
- --databases= : 指定执行同步的数据库。
- --tables= :指定执行同步的表,多个用逗号隔开。
- --sync-to-master :指定一个DSN,即从的IP,他会通过show processlist或show slave status 去自动的找主。
- h= :服务器地址,命令里有2个ip,第一次出现的是Master的地址,第2次是Slave的地址。
- u= :帐号。
- p= :密码。
- --print :打印,但不执行命令。
- --execute :执行命令。
(2) 示例语句
pt-table-checksum --nocheck-replication-filters --no-check-binlog-format --replicate=percona.checksums --databases=study --tables=test1 h=192.168.122.65,u=jin,p=123456,P=3306

pt-table-sync --replicate=percona.checksums h=192.168.122.65,u=jin,p=123456 h=192.168.122.67,u=jin,p=123456 --print --execute

建议:
修复数据的时候,最好还是用--print打印出来的好,这样就可以知道那些数据有问题,可以人为的干预下。
不然直接执行了,出现问题之后更不好处理。总之还是在处理之前做好数据的备份工作。
如上修复后,再次检查,发现主从库数据已经一致了!
pt-table-checksum --nocheck-replication-filters --no-check-binlog-format --replicate=percona.checksums --databases=study --tables=test1 h=192.168.122.65,u=jin,p=123456,P=3306

问题说明:
在上面的操作中,在主库里添加pt-table-checksum检查的权限(从库可以不授权)后,进行数据一致性检查操作,会在操作的库(实例中是study、study1)下产生一个checksums表!
这张checksums表是pt-table-checksum检查过程中产生的。这张表一旦产生了,默认是删除不了的,并且这张表所在的库也默认删除不了,删除后过一会儿就又会出来。
参考链接:
https://www.cnblogs.com/kevingrace/p/6261091.html













