
前言
2023 哪个网络词最热?我投“生成式人工智能”一票。过去一年大家都在拥抱大模型,所有的行业都在做自己的大模型。就像冬日里不来件美拉德色系的服饰就会跟不上时代一样。这不前段时间接入JES,用上好久为碰的RestHighLevelClient包。心血来潮再次访问Elasticsearch官网,发现风格又变了!很惊艳,不信你看
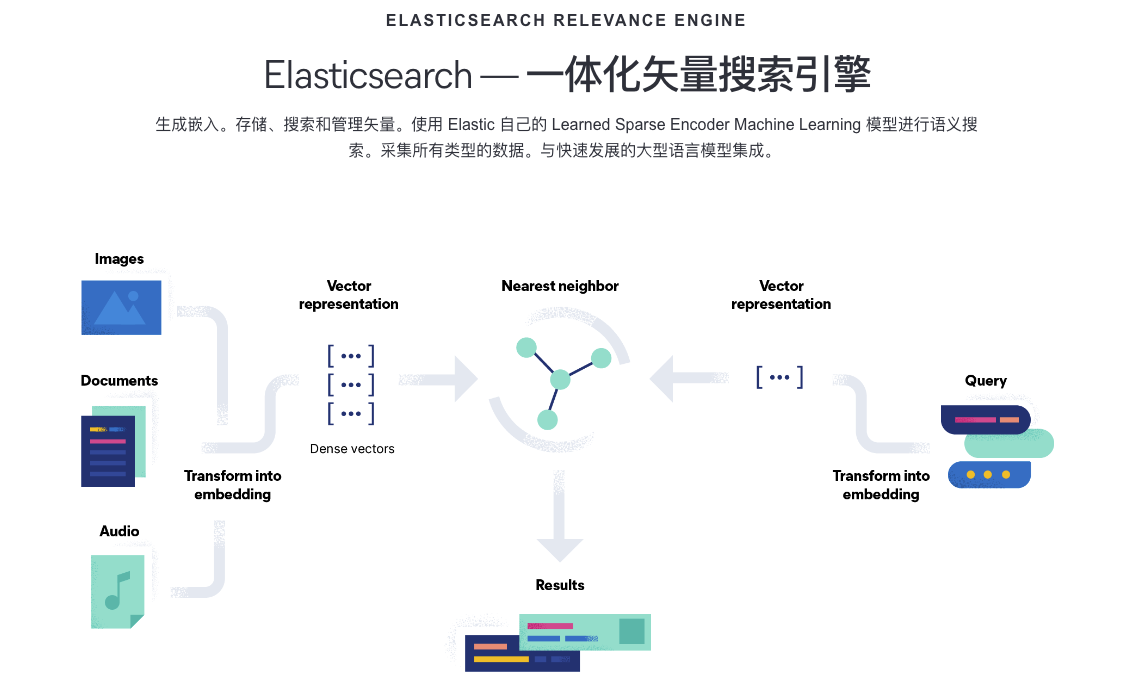
很久没有上Elasticsearch官网。以前的Elasticsearch是以全文搜索引擎为主打的。去年还在想RediSearch会不会撼动Elasticsearch的地位。现在来看它找到内卷焦虑的方子-换个战场去卷别人!所以我就很好奇看看他是如何卷的?决定一探究竟。那么今天就来看下生成式AI和Elasticsearch Relevance Engine(ESRE)最后学习下Elasticsearch作为向量数据如何使用。
一、什么是生成式AI
生成式 AI 是人工智能的一个分支,其核心是能够生成原创内容的计算机模型。通过利用大型语言模型、神经网络和机器学习的强大功能,生成式 AI 能够模仿人类创造力生成新颖的内容。这些模型使用大型数据集和深度学习算法进行训练,从而学习数据中存在的底层结构、关系和模式。根据用户的输入提示,生成新颖独特的输出结果,包括图像、视频、代码、音乐、设计、翻译、问题回答和文本。
流行的生成式AI有哪些
1.ChatGPT ChatGPT 是由 OpenAI 开发的一个大型语言模型,自 2022 年 11 月公开发布以来取得了巨大成功。它使用对话式聊天界面与用户互动,并对输出结果进行微调。它旨在理解文本提示,并生成类似于人的回复,而且它已展示出了参与对话交流、回答相关问题,甚至展现幽默感的能力。
据说,最初向用户免费提供的 ChatGPT-3 版本是根据互联网上超过 45 TB 的文本数据进行训练的。不久之后,Microsoft 将 GPT 的一个版本集成到了 Bing 搜索引擎中。OpenAI 的升级版、基于订阅的 ChatGPT-4 是于 2023 年 3 月推出的。
ChatGPT 采用最先进的转换器架构。GPT 是“Generative Pre-trained Transformer”(生成式预训练转换器)的缩写,转换器架构为自然语言处理 (NLP) 领域带来了革命性的变化。
2.DALL-E 同样来自 OpenAI 的 DALL-E 2 专注于生成图像。DALL-E 结合了 GAN 架构与变分自动编码器,可基于文本提示生成高度细腻和富有想象力的视觉结果。借助 DALL-E,用户可以描述自己心目中的图像和风格,模型就会生成它。与 MidJourney 和新晋加入的 Adobe Firefly 等竞争对手一样,DALL-E 和生成式 AI 正在彻底改变图像的创建和编辑方式。随着整个行业不断涌现的新兴能力,视频、动画和特效也将发生类似的转变。
3.Google Bard 最初是基于 Google LaMDA 系列大型语言模型的一个版本构建而成,后来升级到更先进的 PaLM 2,是 Google ChatGPT 的替代品。Bard 的功能与 ChatGPT 类似,可以编码、解决数学问题、回答问题、写作,以及提供 Google 搜索结果。
在电商行业的应用
电子商务和零售业领域中的 AI:生成式 AI 可以利用购物者的购买模式推荐新产品,并创建更顺畅的购物流程,从而帮助电子商务企业为购物者提供更具个性化的购买体验。对于零售商和电子商务企业来说,无论从更直观的浏览到使用聊天机器人支持的 AI 客户服务功能,以及 AI 常见问题解答板块,AI 都可以打造更好的用户体验。
金融服务领域中的 AI:生成式 AI 可用于市场趋势预测、市场模式研究、投资组合优化、欺诈保护、算法交易和个性化客户服务。模型还可以根据历史趋势生成合成数据,从而帮助进行风险分析和决策。
生成式 AI 模型的局限性
1.领域知识/准确性:模型可能没有足够的与特定域相关的内部知识。这要源于训练模型的数据集。为了定制 LLM 生成的数据和内容,企业需要一种方法来向模型馈送专有数据,以便模型能够学会提供更相关、特定于业务的信息。LLM 是基于大量通用数据集训练的,这些数据集通常缺乏特定领域知识或可能过时。这可能导致不准确的响应,包括“幻觉”,其中模型自信地生成错误信息。
2.隐私和安全:数据隐私是企业如何通过网络和在组件之间使用和安全地传递专有数据的核心,即使在构建创新的搜索体验时也是如此。这引发了隐私和敏感数据保护问题,尤其是在处理个人或机密信息时。
3.规模和成本:由于数据量以及所需的计算能力和内存,使用大型语言模型可能会让许多企业望而却步。然而,想要构建自己的生成式 AI 应用(如聊天机器人)的企业需要将 LLM 与他们的私有数据结合起来。
4.过时:模型在收集训练数据的时候就已被冻结在过去的某一时间点上。因此,生成式 AI 模型所创建内容和数据只有在基于它们进行训练时才是最新的。整合公司数据是让 LLM 能够提供及时结果的内在需求。例如,如果用户向 LLM 查询“今天天气怎么样”,那么传统搜索引擎可能在几毫秒内返回结果,而 LLM 可能需要几秒钟或更长时间。
5.幻觉:当回答问题或进行交互式对话时,LLM 模型可能会编造一些听起来可信和令人信服的事实,但实际上是一些不符合事实的预测。这也是为什么需要将 LLM 与具有上下文、定制的知识相结合的另一个原因,这对于让模型在商业环境中发挥作用至关重要。
二、Elasticsearch Relevance Engine
是的ChatGPT 和 LLM 面临很多挑战。如专业领域数据的质量准确性,相关性数据缺乏过滤,维护和训练成本,安全性和性能,可解释性等。那接下来看下Elastic的ESRE是如何帮助他们解决问题的。
ESRE 提供了多项用于创建高度相关的 AI 搜索应用程序的新功能。ESRE 站在 Elastic 这个搜索领域的巨人肩膀之上,并基于两年多的 Machine Learning 研发成就构建而成。Elasticsearch Relevance Engine 将 AI 的最佳实践与 Elastic 的文本搜索进行了结合。ESRE 为开发人员提供了一整套成熟的检索算法,并能够与大型语言模型 (LLM) 集成。不仅如此,ESRE 还可通过已经得到 Elastic 社区信任的简单、统一的 API 访问,因此世界各地的开发人员都可以立即开始使用它来提升搜索相关性。
Elasticsearch Relevance Engine 的可配置功能可用于通过以下方式帮助提高相关性:
•应用包括 BM25f(这是混合搜索的关键组成部分)在内的高级相关性排序功能
•使用 Elastic 的矢量数据库创建、存储和搜索密集嵌入
•使用各种自然语言处理 (NLP) 任务和模型处理文本
•让开发人员在 Elastic 中管理和使用自己的转换器模型,以适应业务特定的上下文
•通过 API 与第三方转换器模型(如 OpenAI 的 GPT-3 和 4)集成,以根据客户在 Elasticsearch 部署中整合的数据存储,检索直观的内容摘要
•使用 Elastic 开箱即用型的 Learned Sparse Encoder 模型,无需训练或维护模型,就能实现 ML 支持的搜索,从而在各种域提供高度相关的语义搜索
•使用倒数排序融合 (RRF) 轻松组合稀疏和密集检索;倒数排序融合是一种混合排名方法,让开发人员能够自行优化 AI 搜索引擎,以符合他们独特的自然语言和关键字查询类型的组合
•与 LangChain 等第三方工具集成,以帮助构建复杂的数据管道和生成式 AI 应用程序
三、Elasticsearch 向量库适合用在哪
Elasticsearch 支持的信息检索方法:
•词袋模型和 BM25 算法: 用于传统的文本检索。
•KNN(k-nearest neighbor k-近邻)和 ANN(近似最近邻)向量搜索: 用于基于相似度的向量检索。目前8.11版本中还是使用KNN检索。
Elasticsearch 如何缓解 LLM 问题:
•提供数据上下文并与 ChatGPT 或其他 LLM 集成: Elasticsearch 可以存储和管理大量数据,并提供丰富的上下文信息,帮助 LLM 理解查询意图,生成更准确的结果。
•支持自带模型(任何第三方模型): Elasticsearch 可以接入各种预训练语言模型,包括 ChatGPT 和其他 LLM,为用户提供更灵活的选择。
•内置 Elastic Learned Sparse Encoder 模型: 这个模型可以对文本进行高效的向量化表示,方便进行向量搜索和分析。
Elasticsearch 作为向量数据库的优势:
•高效的混合检索: Elasticsearch 可以同时进行文本检索和向量检索,满足多种应用场景。
•海量数据存储: Elasticsearch 可以存储和管理大量文本和向量数据,为 LLM 提供丰富的数据资源。
•高性能查询: Elasticsearch 的查询速度非常快,可以满足实时检索的需求。
Elasticsearch和LLM结合有三种方式:
方式一:**Elasticsearch和LLM**
使用 Elasticsearch 作为向量存储并与 LLM 集成
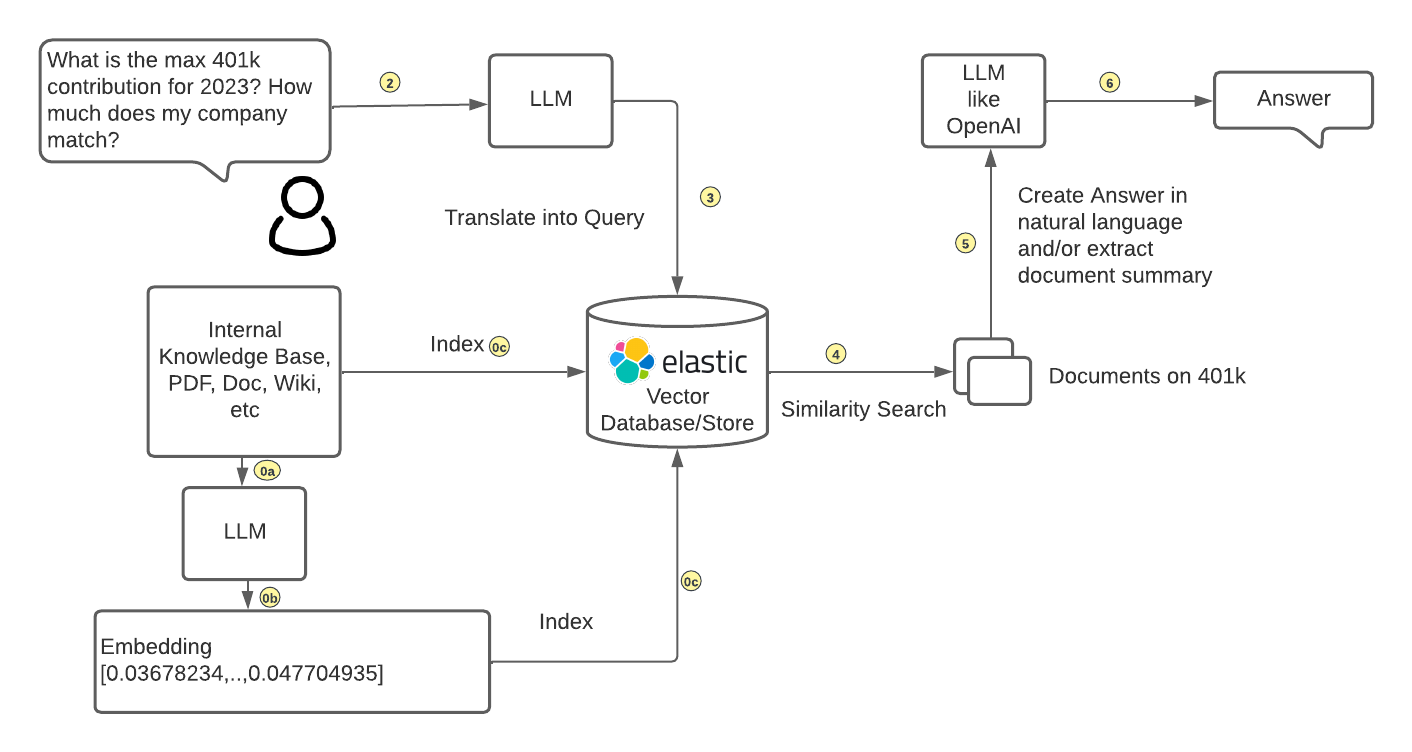
用户将问题数据和生成的嵌入向量一起导入 Elasticsearch。Elasticsearch 会存储和索引这些数据(用户问题的上下文),以便进行高效的检索。当用户提出问题时,用户可以使用 Elasticsearch 的近似最近邻 (KNN) 搜索功能,根据用户的查询在数据集中找到最相似的嵌入向量。这一步骤可以快速找到与用户问题相关的潜在答案。最后Elasticsearch 将搜索结果(包含相关数据的上下文信息)传递给 ChatGPT 或其他 LLM。LLM 会利用这些上下文信息,生成更加准确、流畅和自然的自然语言回答,并返回给用户。
方式二:Elasticsearch Relevance Engine 和LLM
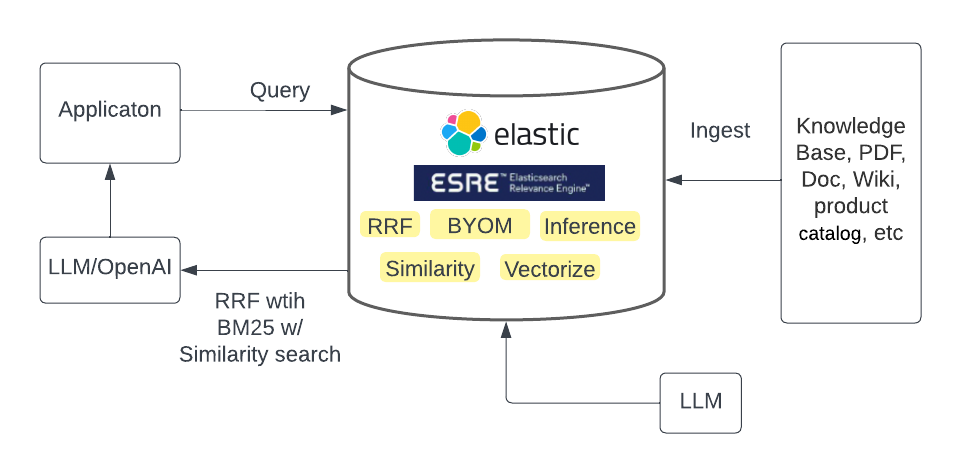
Elasticsearch Relevance Engine (ESRE) 使 BYOLLM 成为现实。此功能以前只能通过机器学习访问,现在已经可以轻松使用。 从 8.8 版开始,可以使用熟悉的搜索 API 将 LLM 模型摄取和查询到 Elasticsearch 中,就像任何其他数据一样。重要的是他使用RRF进行混合检索,将检索结果提高了一个水平,同事降低了复杂性和运营成本。
方式三:使用内置的稀疏编码模型
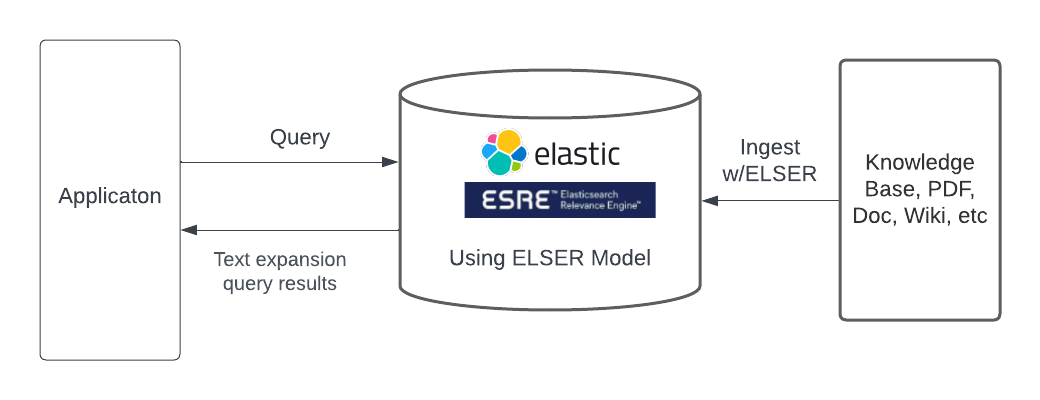
Elastic Learned Sparse Encoder 是 Elastic 开箱即用的语言模型,其性能优于 SPLADE(SParse Lexical AnD Expansion Model),而 SPLADE 本身就是最先进的模型。Elastic Learned Sparse Encoder 解决了词汇不匹配。就像其他搜索端点一样,可以通过text_expansion查询访问 Elastic Learned Sparse Encoder。Elastic Learned Sparse Encoder 使我们的用户只需点击一下即可开始最先进的生成式 AI 搜索并立即产生结果。Elastic Learned Sparse Encoder 也是 Elastic 的一项商业功能。
四、Elasticsearch 向量检索
ES作为向量数据库提供三种能力:1.存储嵌入 2.高效搜索相邻数据 3.将文本嵌入到向量表示。
首先将待检索的数据转换成向量存储。其表现形式为128维的float数组。之后将数组索引到ES的dense_vector类型的字段中。最后基于ANN或KNN进行检索。如下图
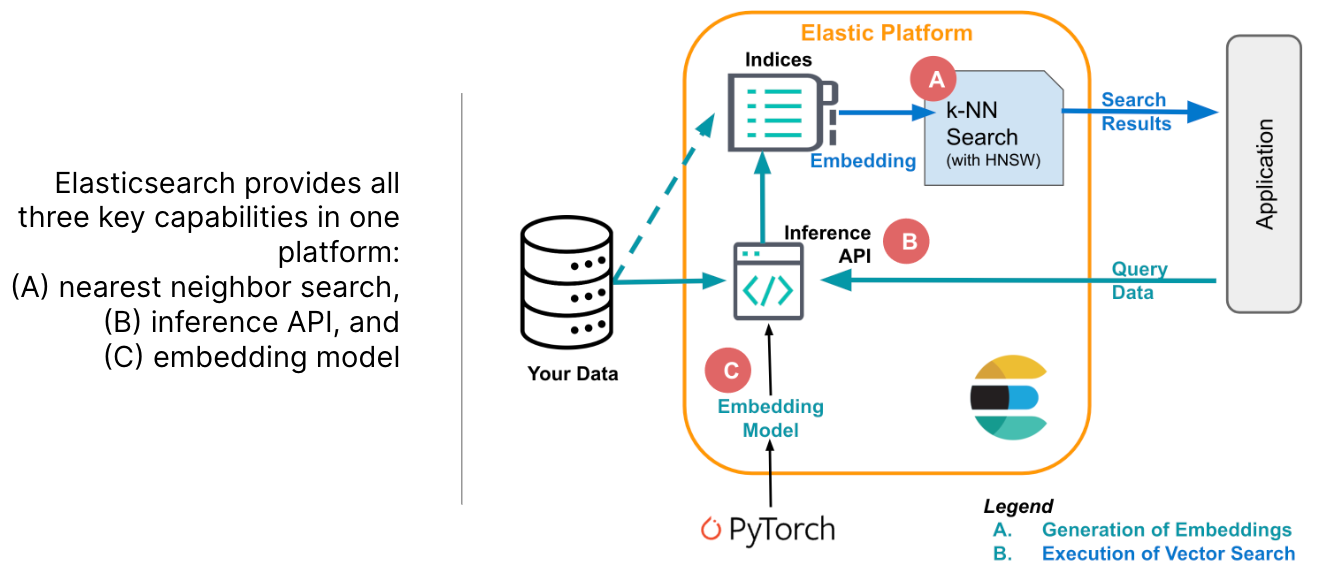
五、Elasticsearch vector search
我们来看一个ES中创建和查询向量数据的示例
第一步我们创建一个向量索引image-index
PUT /image-index
{
"mappings": {
"properties": {
"image-vector": {
"type": "dense_vector",
"dims": 3,
"index": true,
"similarity": "l2_norm"
},
"title-vector": {
"type": "dense_vector",
"dims": 5,
"index": true,
"similarity": "l2_norm"
},
"title": {
"type": "text"
},
"file-type": {
"type": "keyword"
}
}
}
}第二步向索引image-index中批量插入数据
POST /image-index/_bulk?refresh=true
{ "index": { "_id": "1" } }
{ "image-vector": [1, 5, -20], "title-vector": [12, 50, -10, 0, 1], "title": "moose family", "file-type": "jpg" }
{ "index": { "_id": "2" } }
{ "image-vector": [42, 8, -15], "title-vector": [25, 1, 4, -12, 2], "title": "alpine lake", "file-type": "png" }
{ "index": { "_id": "3" } }
{ "image-vector": [15, 11, 23], "title-vector": [1, 5, 25, 50, 20], "title": "full moon", "file-type": "jpg" }最后通过KNN api检索数据
POST /image-index/_search
{
"knn": {
"field": "image-vector",
"query_vector": [-5, 9, -12],
"k": 10,
"num_candidates": 100
},
"fields": [ "title", "file-type" ]
}查询结果如下
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 0.008547009,
"hits": [
{
"_index": "image-index",
"_id": "1",
"_score": 0.008547009,
"_source": {
"image-vector": [
1,
5,
-20
],
"title-vector": [
12,
50,
-10,
0,
1
],
"title": "moose family",
"file-type": "jpg"
},
"fields": {
"file-type": [
"jpg"
],
"title": [
"moose family"
]
}
},
{
"_index": "image-index",
"_id": "3",
"_score": 0.00061349693,
"_source": {
"image-vector": [
15,
11,
23
],
"title-vector": [
1,
5,
25,
50,
20
],
"title": "full moon",
"file-type": "jpg"
},
"fields": {
"file-type": [
"jpg"
],
"title": [
"full moon"
]
}
},
{
"_index": "image-index",
"_id": "2",
"_score": 0.00045045046,
"_source": {
"image-vector": [
42,
8,
-15
],
"title-vector": [
25,
1,
4,
-12,
2
],
"title": "alpine lake",
"file-type": "png"
},
"fields": {
"file-type": [
"png"
],
"title": [
"alpine lake"
]
}
}
]
}
}以上是作为向量数据库的实例。ES是可以作为AI查询。支持AI查询的客户端包括JavaScript,Python,Go,PHP,Ruby(没有java)。有兴趣的可以直接去github上去试跑( elasticsearch-labs )
六、总结
Elasticsearch确实卷。它的架构已经不是以前,为了实现更快的查询而迭代。2024年Elasticsearch提出了无服务架构的理念。将存储和计算完全分离开。无服务器架构标志着 Elasticsearch 的重大重组。它的构建是为了利用最新的云原生服务,以轻松的管理提供优化的产品体验。它不仅具备数据湖的存储能力,还拥有与 Elasticsearch 相媲美的快速搜索性能,同时通过无需人工干预的集群管理和扩展,实现了操作的简便性。
七、名词解释
RRF:RRF 是 Elasticsearch 中新推出的一种混合搜索技术,可以将来自不同搜索方法的结果进行融合和排序,以提供更全面、更准确的搜索结果。
ANN:ANN 代表人工神经网络 (Artificial Neural Networks)。人工神经网络是一种计算机科学和人工智能领域的算法模型,它模仿人类大脑的神经网络。
KNN:代表 k 近邻。它是一种机器学习算法,用于在数据集中找到与给定查询最相似的 k 个点。KNN 算法可用于各种任务,包括分类、回归和聚类。
作者:京东保险 管顺利
来源:京东云开发者社区 转载请注明来源




