
这篇是接着上篇来的,所以标号就继续了~~~~
四、set
介绍:
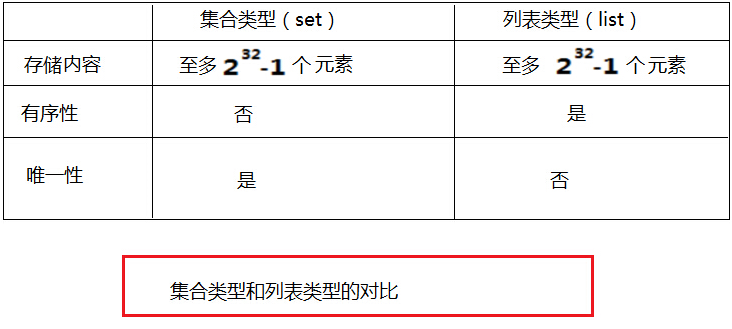
set集合元素是不重复的无序的。set类型与list类型有相似之处,如图:
命令:
①sadd/smembers/srem/sismember 添加/获取/删除/是否是set的元素
sadd set a,sadd set b,
smembers set(返回set集合所有的元素) srem set a, sismember b
sadd set1 a b c
②sdiff/sinter(交集)/sunion(并集)
sdiif set set1 返回差集,即返回set有的而set2中没有
sinter set set1 返回两个set都有的
sunion set set1 返回两个的都有的
③sdiffstore/sinterstore/sunionstore
将②中的数据存储 sdiffstore a1 set set1 存到a1中 a1也是一个set集合
④scard(获取集合长度)/spop(随机从集合中取出并删除一个元素)
scard set 返回set集合长度,spop set 随机从set中弹出一个元素
⑤srandmember key [count]
如果 count 为正数,且小于集合基数,那么命令返回一个包含 count 个元素的数组,数组中的元素各不相同。
如果 count 大于等于集合基数,那么返回整个集合。
如果 count 为负数,那么命令返回一个数组,数组中的元素可能会重复出现多次,而数组的长度为 count 的绝对值。
五、sortedset
介绍:
有序集合,在set集合类型的基础上为集合中的每个元素都关联了一个分数,这样可以很方便的获得分数最高的N个元素(topN)。
有序集合类型和列表类型的差异
相同点
(1)二者都是有序的
(2)二者都可以获得某一范围的元素
不同点
(1)列表类型是通过双向链表实现的,获取靠近两端的数据速度极快,当列表中元素增多后,访问中间的数据速度会很慢,所以它比较适合很少访问中间元素的应用
(2)有序集合类型是使用散列表和跳跃表(skip list)实现的,所以即使读取位于中间部分的数据速度也很快
(3)列表中不能简单的调整某个元素的位置,但是有序集合可以(通过更改这个元素的分值)
(4)有序集合要比列表类型更耗费内存
命令:
①zadd/zscore/zrange/zrevrange/ 添加/获取指定元素分数/从小到大返回/从大到小返回
zadd zset 10 a zadd zset 20 b zadd zset 5 c
zscore zset b(返回20)
zrange zset 0 -1 返回(c a b)有序
zrevrange zset 0 -1 (b a c)
②zrangebyscore(默认是闭区间,可使用"("使用开区间)
zrangebyscore zset 0 10 获取zset中0分到10分的元素 这里返回c和a
zrangebyscore zset 0 (10 获取zset中0分到10分的元素 这里返回c
③zincrby/zcard/zcount(获取指定分数范围的元素个数)
zincrby zset 6 c 让zset中c元素的值加6
zcard zset 返回zset中元素个数
zcount zset 0 10 指定分数范围的元素
④zrem/zremrangebyrank/zremrangebyscore
zrem zset a
zremrangebyrank zset 0 1 角标区间删除
zremrangebyscore zset 0 10 分数范围删除
扩展:+inf(正无穷) -inf(负无穷)











