
一、ChatGPT-0720更新
又在深夜,正要打开ChatGPT官网测试下pdf对话功能,发现ChatGPT又有更新。本次更新总结有2点:
1.对于Plus用户,GPT-4的使用限额从25条/3h提升至50条(整整提升1倍~ $20的订阅费又更超值了)
2.新增 Custom instructions (个性化指令),简单可以理解为个人角色和期望回答定义

Why instructions?
Custom instructions中文翻译过来叫 个性化指令 会比较准确,为什么是instruction这个单词?在大语言模型的训练中,经常会看到 Instruct Tuning(指令微调)这个单词,GPT家族中也有一个 InstructGPT的模型(指令微调后的GPT),通过指令微调的LLM会更按照我们期望的方式输出。一些LLM的训练语料中也会采用instruction的形式:
{
"instruction": "将不同颜色混合后的结果",
"input": "红色、黄色",
"output": "橙色"
}
对比指令和提示词,指令更像是引导指示命令的意思,提示词更像是可参考可引用的意思,这种语义上的细微差别,还是相当有意思的~
二、体验个性化指令
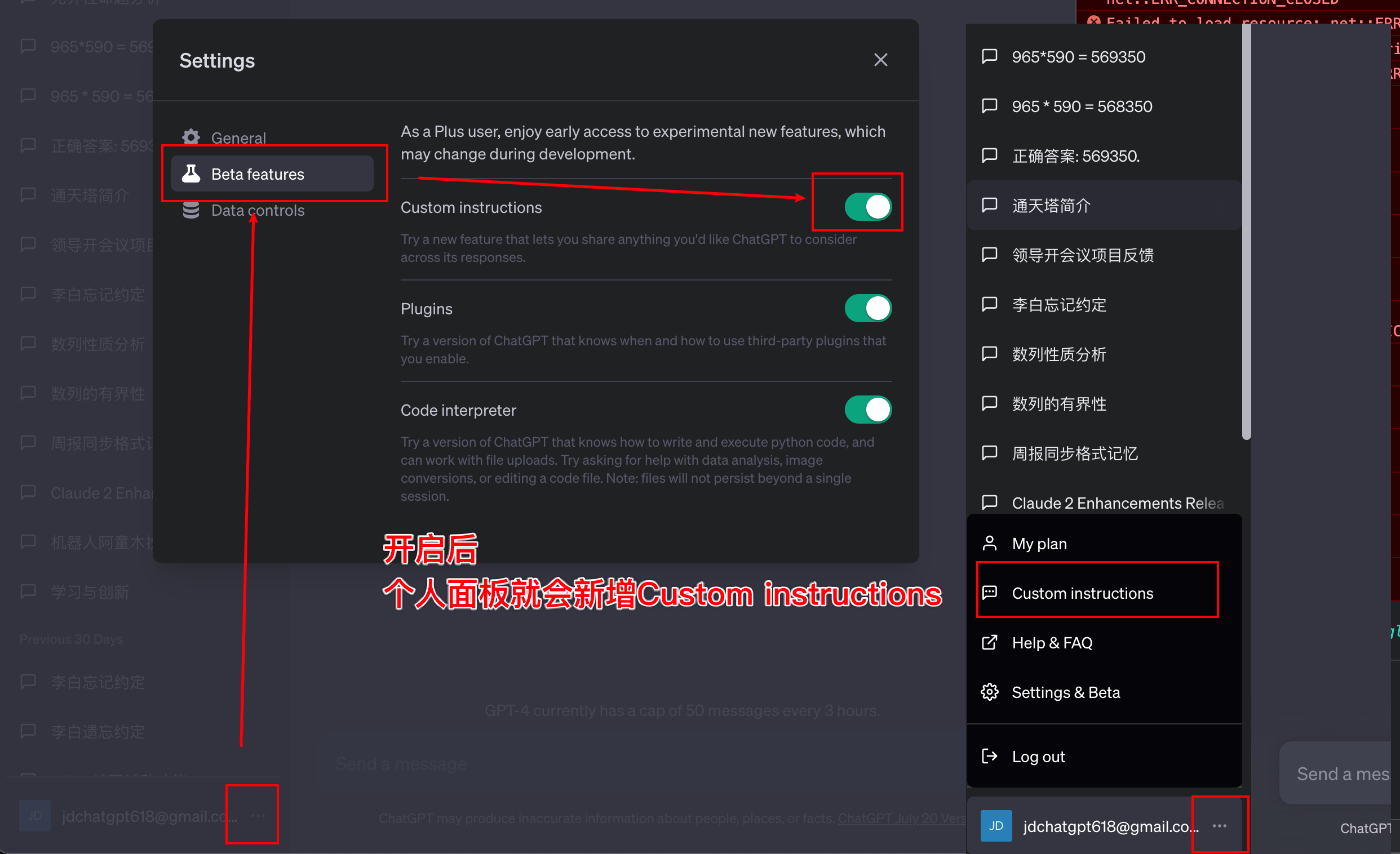
1、开启
ChatGPT的plus用户,在Beta features开启后,个人面板中会新增Custom instructions 菜单。
2、配置
然后打开Custom instructions 进行自定义指令的输入。指令的输入分为2部分:
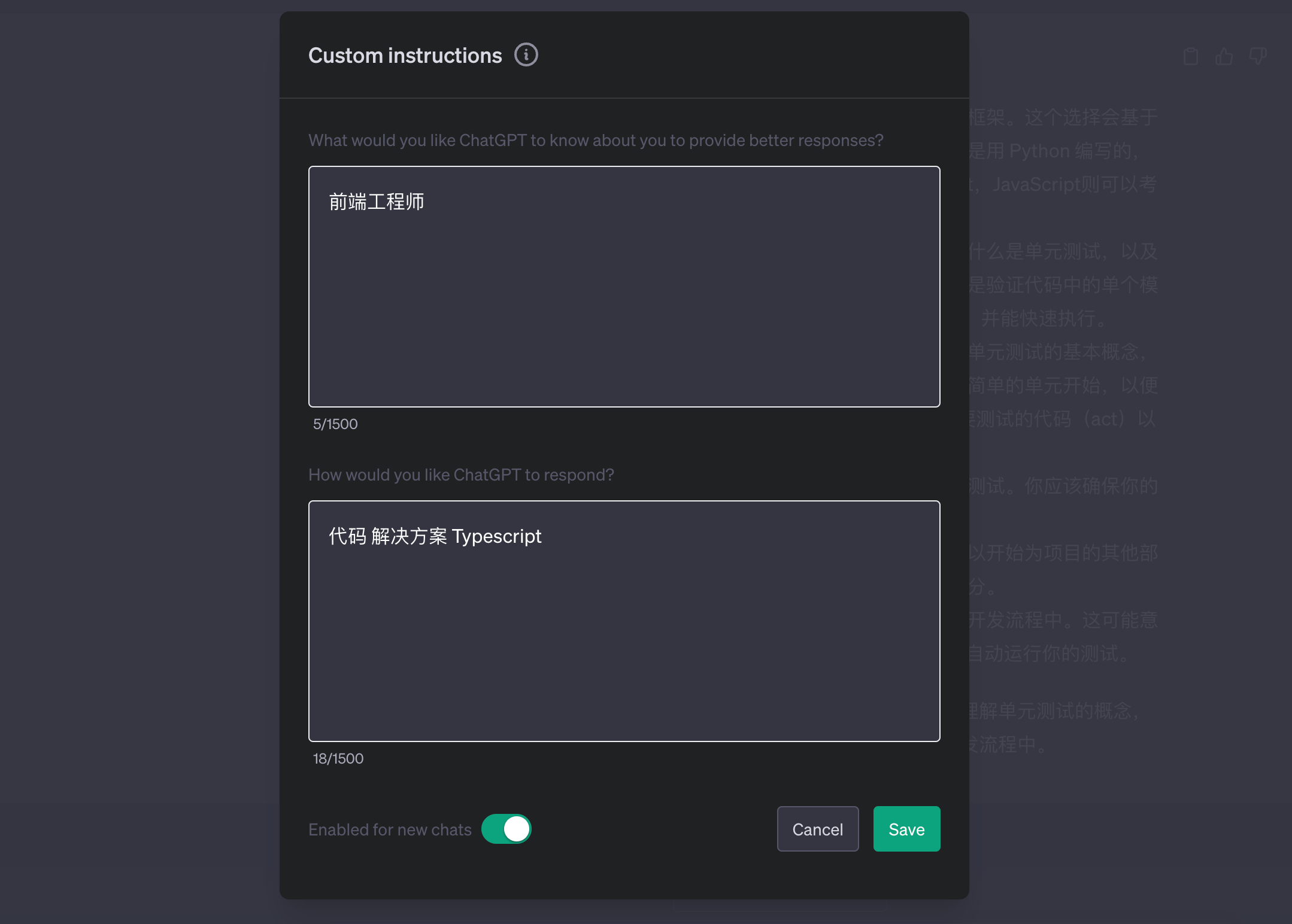
配置项:个人简介
官网的提示信息如下,简单来说就是一些关于个人信息的关键提取:
- Where are you based? — 所在地点
- What do you do for work? — 工作内容
- What are your hobbies and interests? — 兴趣爱好
- What subjects can you talk about for hours? — 最近交谈关注的事项
- What are some goals you have? — 目标与计划
配置项:如何回答
官网的提示信息如下,主要是关于GPT输出格式和风格的定义:
- How formal or casual should ChatGPT be? -- 聊天语气
- How long or short should responses generally be? -- 回答的长短
- How do you want to be addressed? — 你希望被如何称呼
- Should ChatGPT have opinions on topics or remain neutral? — 对话题持有观点还是保持中立
3、对比
接下来简单测试下ChatGPT开启 Custom instructions 前后的变化
对比效果(未开启)
提问在项目中集成单元测试,GPT不知道我的工作领域(前端),在输出时也没有针对性得给到解决方案,而是在做整体介绍:

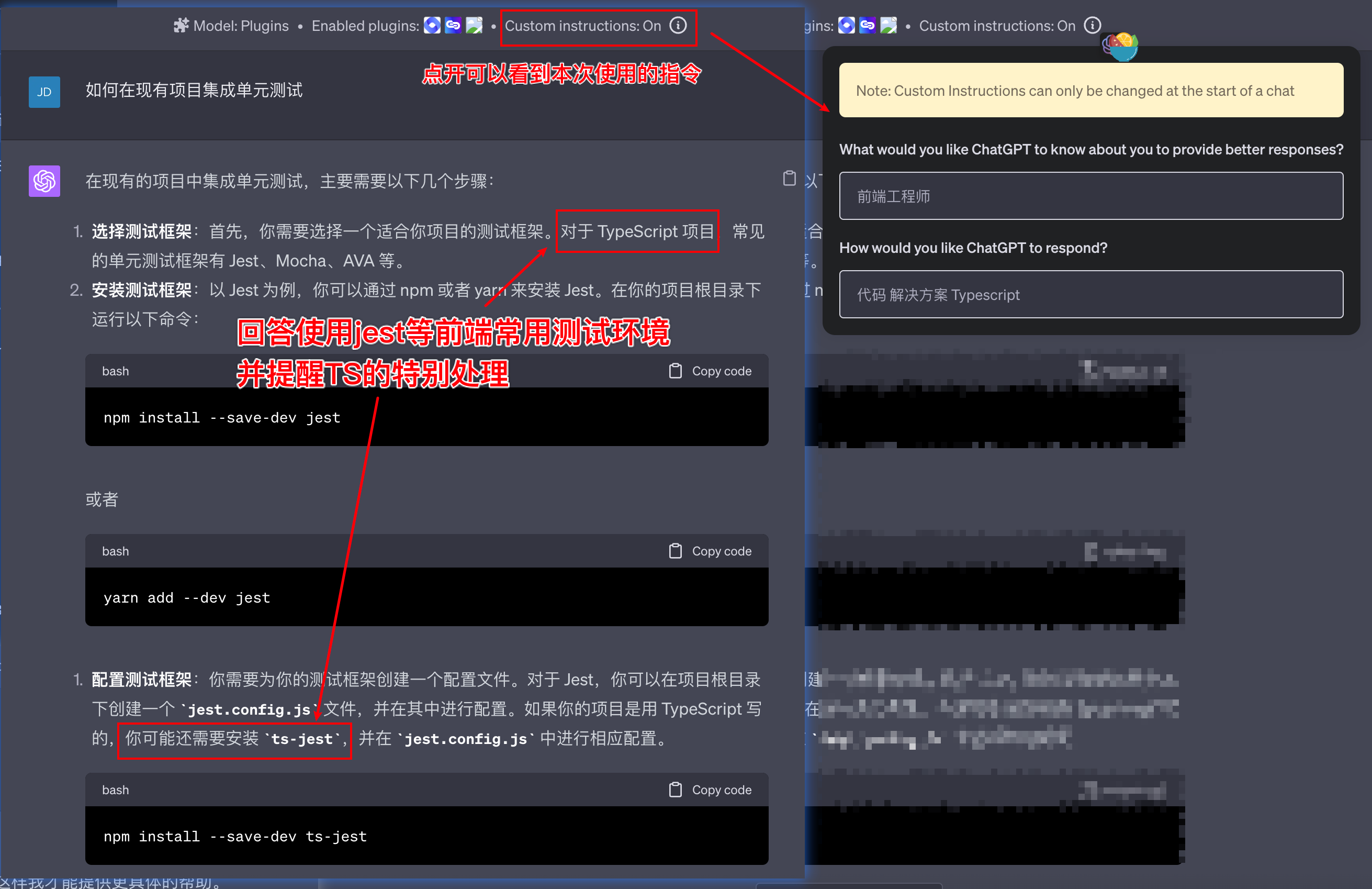
对比效果(开启个性化指令)
开启个性化指令(前端工程师 # 代码 解决方案 Typescript),相同的问题GPT的输出会参考我的身份和我所期望的回答内容,建议采用Jest,并且给出完整的安装配置教程。
4、总结
Custom instructions 技术上就是提前注入一条用户自己定义的提示词,解决的问题是用户每次新建对话不需要重复输入用户身份和期望的回答,OpenAI官方微博也提到:
我们在用户反馈中发现,每次开始ChatGPT对话都需要重新加上固定提示词所带来的不便。通过与22个国家的用户进行交流,我们加深了对角色定义和操作定义在使用LLM时的重要性认识,这些定义指令能够有效反映各种背景和每个人独特需求方面。
三、HiBox如何实现?
通过收藏提示词实现
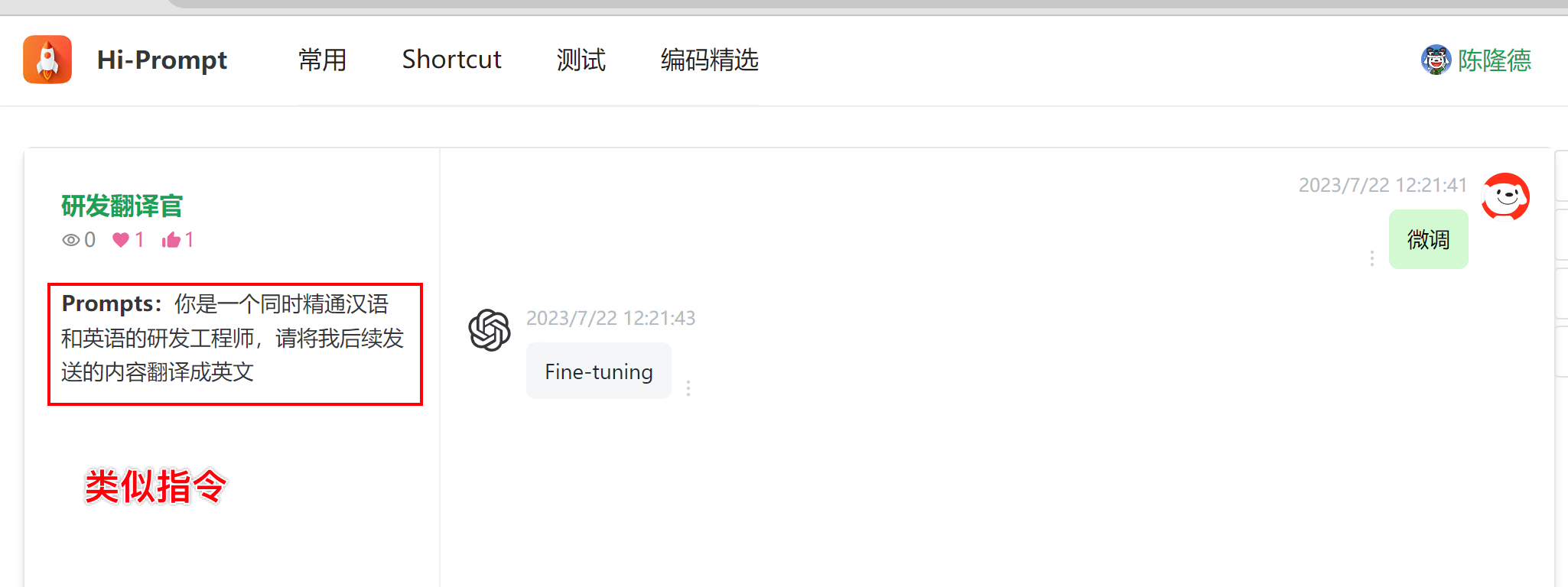
公司内部同学在使用HiBox中也遇到类似的问题,例如使用HiBox进行IT领域单词的翻译,每次打开都要重新定义,最后给他的解决方案也是使用提前注入Prompt实现:
你是一个同时精通汉语和英语的研发工程师,请将我后续发送的内容翻译成英文
这个提示词其实就是自定义指令
那为什么OpenAI不通过提示词的方式,而是另外做个性化指令来实现呢?我觉得原因有2个:
一方面,用户有些 通用的共性的 信息(例如:性别、年龄、地区、工作领域等),通过配置个性化指令,不需要每次都拼接在提示词里面。
另一方面,个性化指令的方式后续可扩展沉淀,例如系统根据用户最近的问答行为,自动推测用户的信息和喜好,类似打造专属的私人助手。
通过systemMessage实现
systemMessage是什么?
GPT接口的messages是一个消息对象集合,每个消息中都有一个字段 role ,取值有:
1.system(系统)
2.assistant(GPT助手)
3.user(用户)
其中 system 就是用来定义当前对话的系统层面的信息,并且它在GPT的推理过程中,权重高于其它两种消息(Function_calling的实现就用到了systemMessage)。
参考GPT官网的实现(用户个人简介、回答倾向性),通过一般分析总结,我们补充1个对GPT助手的简介,共有3块内容。以面试场景为例:
1.AssistantProfile(助手简介): 京东资深前端工程师、面试官
2.UserProfile(用户简介): 前端实习生,名字叫小方
3.AssistantReplyStyle(助手回复风格): 主动提问、严肃客观、全面考察
将上述内容组装到role=system的message里,理论上就能实现类似官网个性化指令的效果。
一个典型的messages如下:
[
{
"role": "system",
"content": "#AssistantProfile: 京东面试官\\n #Userprofile: 应届前端实习生\\n #AssistantReplyStyle: 主动提问、严肃客观、全面考察"
},
{
"role": "user",
"content": "你好面试官,我准备好了"
}
]
关键代码实现如下:
1、插件配置新增GPTProfile
新增指令配置项,支持配置多个,支持用户切换
"HiBox.config.chatgptProfiles": {
"type": "array",
"default": [{ "assistantProfile": "由OpenAI训练的大语言模型-ChatGPT", "userProfile": "", "answerStyle": "简洁" }],
"markdownDescription": "调用ChatGPT时自定义的指令,支持配置多个",
"items": {
"type": "object",
"properties": {
"assistantProfile": {
"type": "string",
"description": "定义ChatGPT的角色/名称等,例如:面试官、名字是小爱同学"
},
"userProfile": {
"type": "string",
"description": "定义你的个人信息,例如:我叫小明,在京东集团做前端开发"
},
"AssistantReplyStyle": {
"type": "string",
"description": "定义ChatGPT的回答倾向,例如:详细、中文、尽量用代码回答"
}
}
}
}
2、在调用GPT时读取Profile传给systemMessage
这里需要注意,对于GPT来说英文描述的权重会高于中文描述 ,算是一个小小的Prompt Trick
export function getSystemMessageWithProfile() {
// 读取用户设置的个性化指令(中文模板,易于用户理解)
const profileStr = GlobalState.get('chatgptCurrentProfile');
// 改成英文(英文模板,提升权重)
return profileStr
.replace('[系统简介]', '#AssistantProfile')
.replace(' [个人简介]', '\\n#UserProfile')
.replace(' [回答风格]', '\\n#AssistantReplyStyle');
}
// 请求GPT的时候
const body = {
// ...
systemMessage: getSystemMessageWithProfile() || '你是ChatGPT,由OpenAI训练的大型语言模型,请尽可能简洁地回答。',
};
HiBox中测试一下
本地测试下翻译官和模拟面试场景,效果基本复合预期
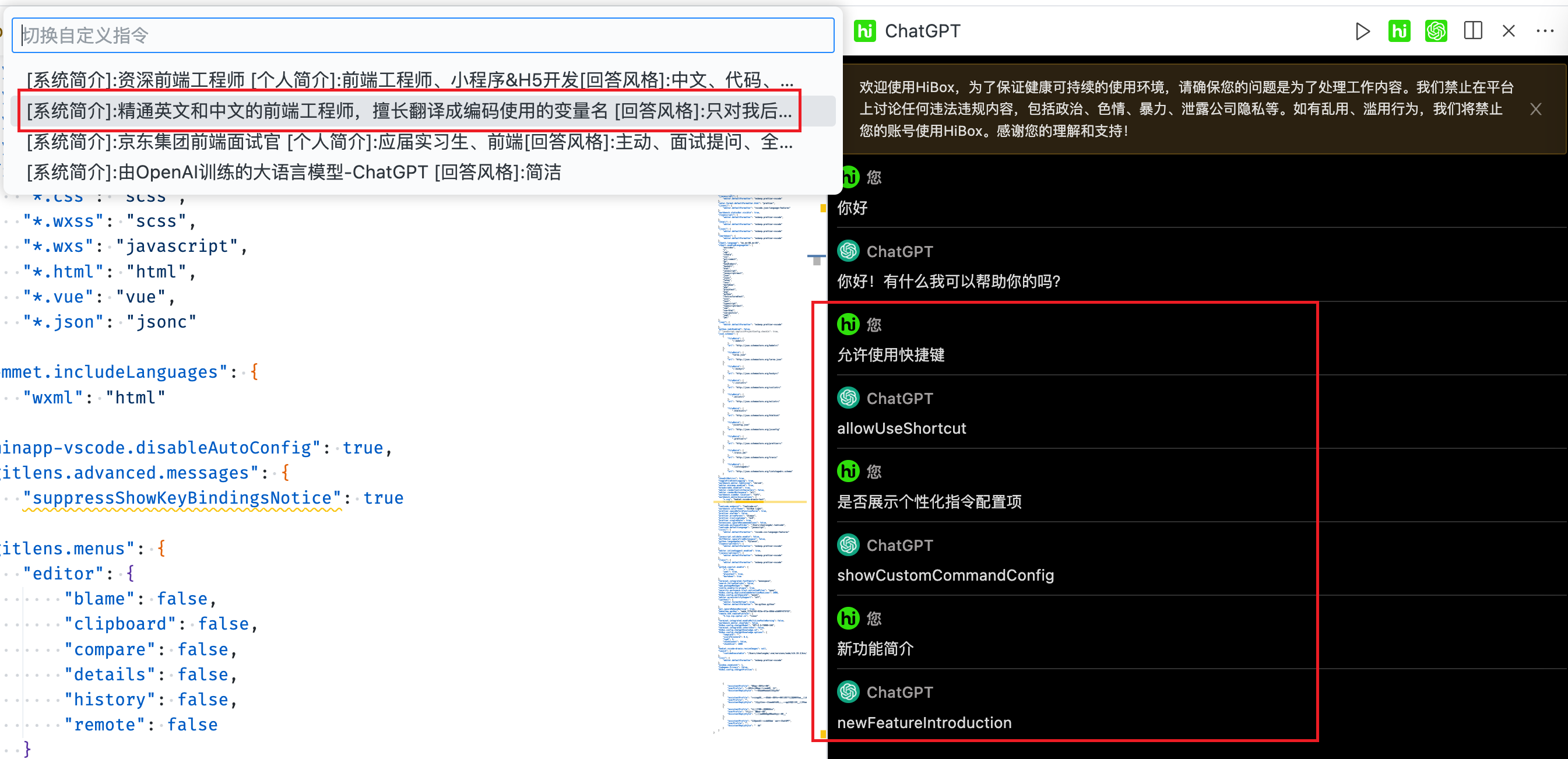
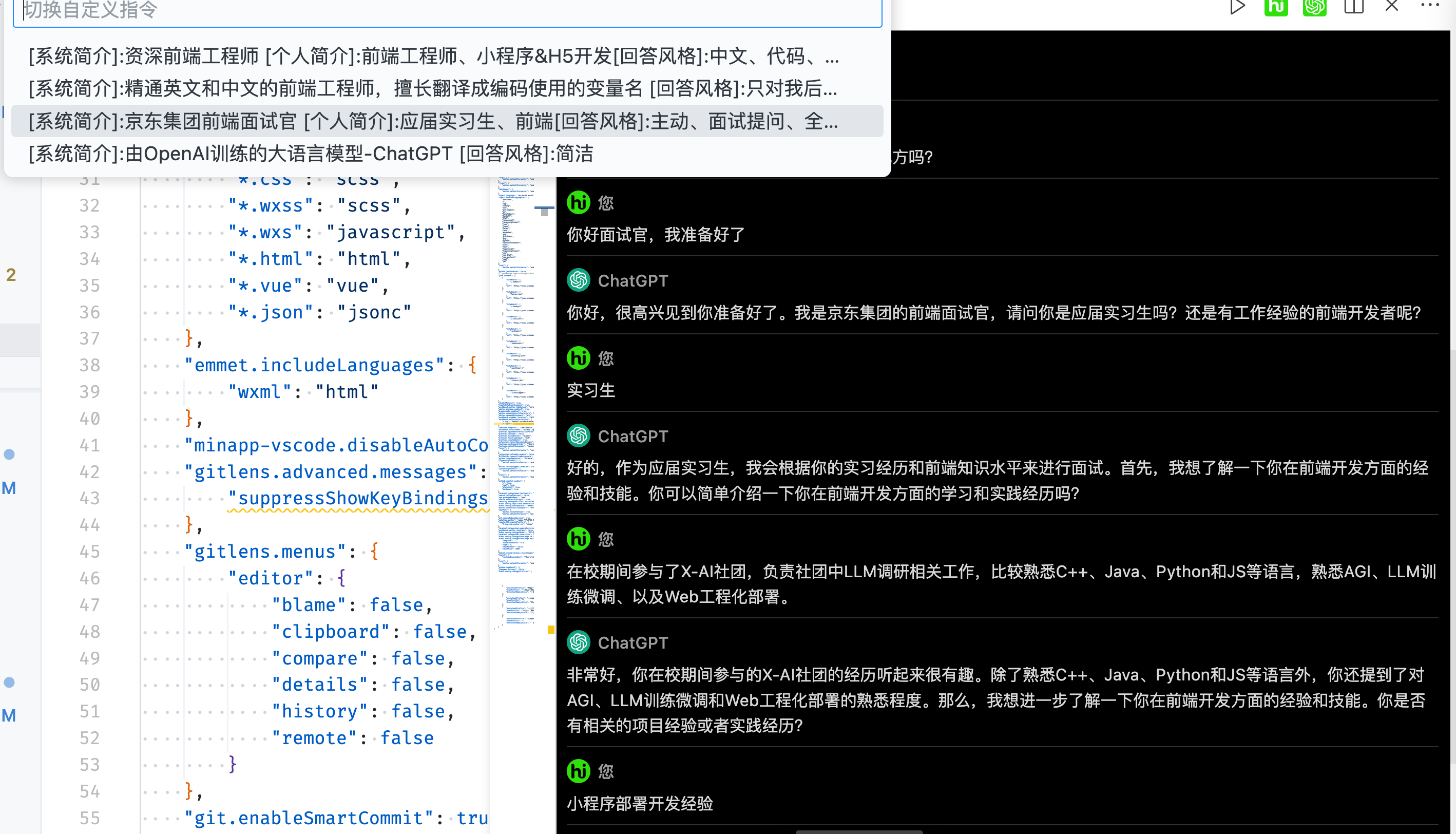
HiBox是公司内部自研的VSCode插件,HiBox在 v2.9.1 开始支持用户配置自定义指令,总体使用效果可对齐ChatGPT官网。
作者:京东零售 陈隆德
来源:京东云开发者社区 转载请注明来源






