
CheckPoint
1. checkpoint 保留策略
默认情况下,checkpoint 不会被保留,取消程序时即会删除他们,但是可以通过配置保留定期检查点,根据配置 当作业失败或者取消的时候 ,不会自动清除这些保留的检查点 。
java :
CheckpointConfig config = env.getCheckpointConfig();
config.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
ExternalizedCheckpointCleanup 可选项如下:
- ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION: 取消作业时保留检查点。请注意,在这种情况下,您必须在取消后手动清理检查点状态。
- ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 取消作业时删除检查点。只有在作业失败时,检查点状态才可用。
2. Checkpoint 配置
与SavePoint 类似 ,checkpoint 保留的是元数据文件和一些数据文件
默认情况下checkpoint 只保留 一份最新数据,如果需要进行checkpoint数据恢复 ,可以通过全局设置的方式设置该集群默认的checkpoint 保留数,以保证后期可以从checkpoint 点进行恢复 。 同时为了 及时保存checkpoint状态 还需要在服务级别设置 checkpoint 检查点的 备份速度 。 全局配置:
flink-conf.yaml
// 设置 checkpoint全局设置保存点
state.checkpoints.dir: hdfs:///checkpoints/
// 设置checkpoint 默认保留 数量
state.checkpoints.num-retained: 20
注意 如果将 checkpoint保存在hdfs 系统中 , 需要设置 hdfs 元数据信息 : fs.default-scheme:
服务级别设置:
java:
// 设置 checkpoint 保存目录
env.setStateBackend(new RocksDBStateBackend("hdfs:///checkpoints-data/");
// 设置checkpoint 检查点间隔时间
env.enableCheckpointing(5000);
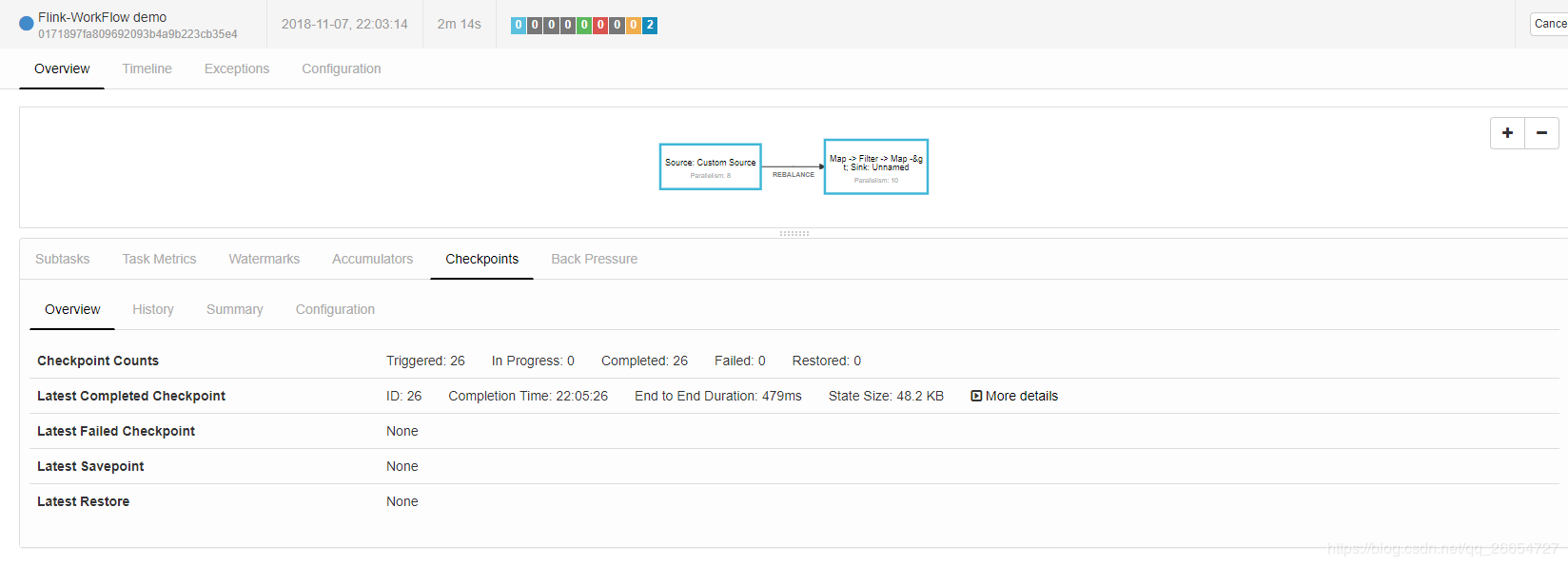
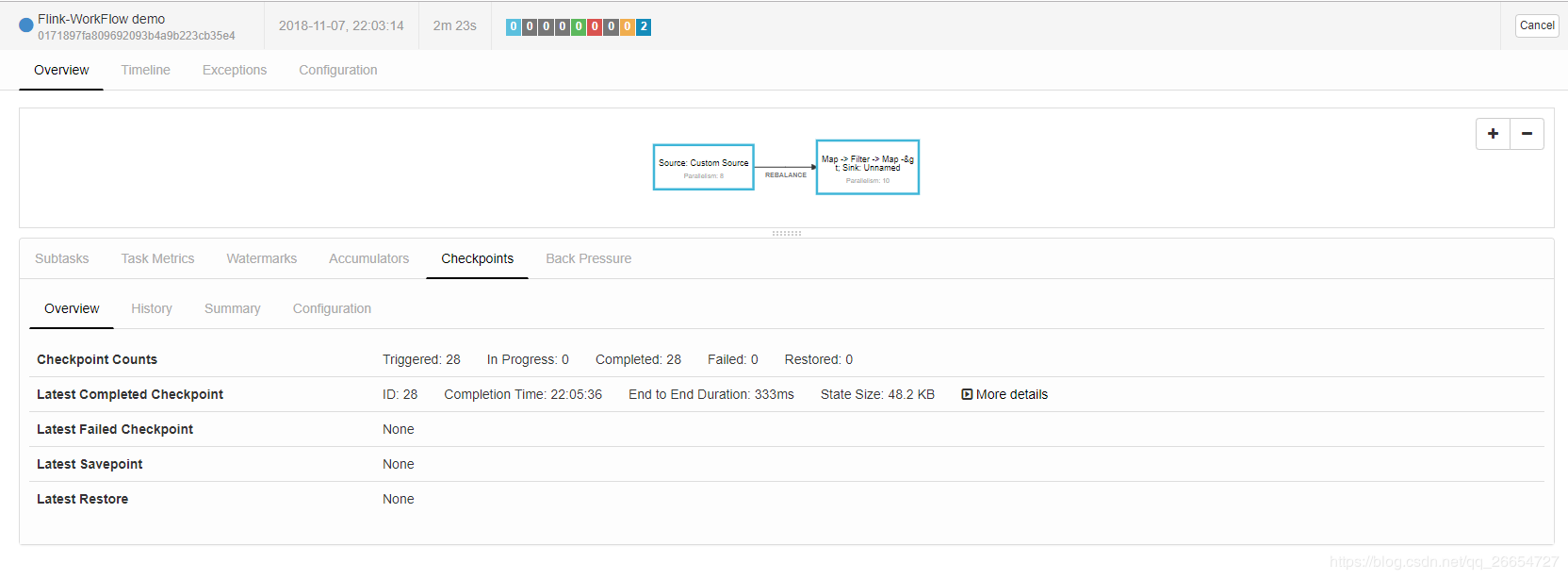
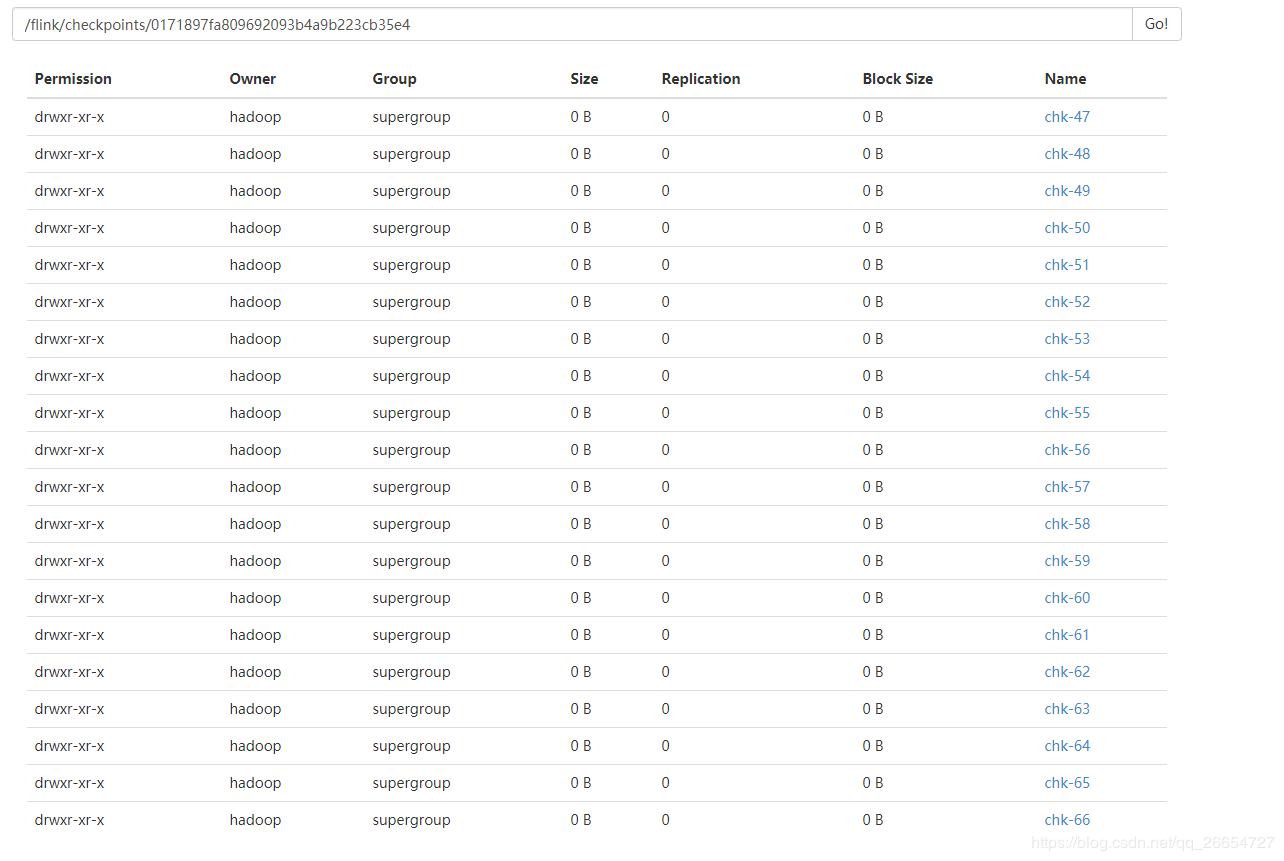
提交任务之后 job 界面 和 hdfs 界面
- 通过页面可以看出 checkpoint 备份方式是每5秒执行一次 ,保存当前所有task 状态元信息 和状态信息 。
- hdfs 信息 保存 jobId 为 0171897fa809692093b4a9b223cb35e4 最新的 20次 checkpoint 信息
3. Checkpoint 状态点恢复
因为 flink checkpoint 目录 分别对应的是 jobId , 每通过 flink run 方式 / 页面提交方式 都会重新生成 jobId ,那么如何通过checkpoint 恢复 失败任务或者重新执行保留时间点的 任务?
flink 提供了 在启动 之时 通过设置 -s 参数指定checkpoint 目录 , 让新的jobId 读取该checkpoint 元文件信息和状态信息 ,从而达到指定时间节点启动 job 。启动方式如下 :
./bin/flink -s /flink/checkpoints/0171897fa809692093b4a9b223cb35e4/chk-50/_metadata -p @Parallelism -c @Mainclass @jar
Savepoint
Savepoint 介绍
Savepoint是通过Flink的检查点机制创建的流作业执行状态的一致图像。您可以使用Savepoints来停止和恢复,分叉或更新Flink作业。保存点由两部分组成:稳定存储(例如HDFS,S3,...)上的(通常是大的)二进制文件和(相对较小的)元数据文件的目录。稳定存储上的文件表示作业执行状态图像的净数据。Savepoint的元数据文件以(绝对路径)的形式包含(主要)指向作为Savepoint一部分的稳定存储上的所有文件的指针。
savepoint 和 checkpoint 区别
从概念上讲,Flink的Savepoints与Checkpoints的不同之处在于备份与传统数据库系统中的恢复日志不同。检查点的主要目的是在意外的作业失败时提供恢复机制。Checkpoint的生命周期由Flink管理,即Flink创建,拥有和发布Checkpoint - 无需用户交互。作为一种恢复和定期触发的方法,Checkpoint实现的两个主要设计目标是:i)being as lightweight to create (轻量级),ii)fast restore (快速恢复) 。针对这些目标的优化可以利用某些属性,例如,JobCode在执行尝试之间不会改变。
与此相反,Savepoints由用户创建,拥有和删除。他们的用例是planned (计划) 的,manual backup( 手动备份 ) 和 resume(恢复) 。例如,这可能是您的Flink版本的更新,更改您的Job graph ,更改 parallelism ,分配第二个作业,如红色/蓝色部署,等等。当然,Savepoints必须在终止工作后继续存在。从概念上讲,保存点的生成和恢复成本可能更高,并且更多地关注可移植性和对前面提到的作业更改的支持。
Assigning Operator IDs ( 分配 operator ids)
为了能够在将来升级你的程序在本节中描述。主要的必要更改是通过该uid(String)方法手动指定操作员ID 。这些ID用于确定每个运算符的状态。
java:
DataStream<String> stream = env.
// Stateful source (e.g. Kafka) with ID
.addSource(new StatefulSource())
.uid("source-id") // ID for the source operator
.shuffle()
// Stateful mapper with ID
.map(new StatefulMapper())
.uid("mapper-id") // ID for the mapper
// Stateless printing sink
.print(); // Auto-generated ID
如果您未手动指定ID,则会自动生成这些ID。只要这些ID不变,您就可以从保存点自动恢复。生成的ID取决于程序的结构,并且对程序更改很敏感。因此,强烈建议手动分配这些ID。
Savepoint State
触发保存点时,会创建一个新的保存点目录,其中将存储数据和元数据。可以通过配置默认目标目录或使用触发器命令指定自定义目标目录来控制此目录的位置
保存Savepoint
$ bin/flink savepoint :jobId [:targetDirectory]
这将触发具有ID的作业的保存点:jobId,并返回创建的保存点的路径。您需要此路径来还原和部署保存点。
在yarn 集群中保存Savepoint
$ bin/flink savepoint :jobId [:targetDirectory] -yid :yarnAppId
这将触发具有ID :jobId和YARN应用程序ID 的作业的保存点:yarnAppId,并返回创建的保存点的路径。
使用 Savepoint 取消job
$ bin/flink cancel -s [:targetDirectory] :jobId
这将以原子方式触发具有ID的作业的保存点:jobid并取消作业。此外,您可以指定目标文件系统目录以存储保存点。该目录需要可由JobManager和TaskManager访问。
Resuming Savepoint
$ bin/flink run -s :savepointPath [:runArgs]
这将提交作业并指定要从中恢复的保存点。您可以指定保存点目录或_metadata文件的路径。
允许未恢复状态启动
$ bin/flink run -s :savepointPath -n [:runArgs]
默认情况下,resume操作将尝试将保存点的所有状态映射回要恢复的程序。如果删除了运算符,则可以通过--allowNonRestoredState(short -n:)选项跳过无法映射到新程序的状态:
全局配置
您可以通过state.savepoints.dir 配置文件设置默认savepoint 位置 。触发保存点时,此目录将用于存储保存点。您可以通过使用触发器命令指定自定义目标目录来覆盖默认值(请参阅:targetDirectory参数)。
flink-conf.yaml
# Default savepoint target directory
state.savepoints.dir: hdfs:///flink/savepoints
参考地址:
https://ci.apache.org/projects/flink/flink-docs-release-1.6/ops/state/state_backends.html https://ci.apache.org/projects/flink/flink-docs-release-1.6/ops/state/checkpoints.html https://ci.apache.org/projects/flink/flink-docs-release-1.6/ops/state/savepoints.html http://ju.outofmemory.cn/entry/370841












