
据我所知,目前很多公司都在生产环境使用TiDB了,例如:小米,小红书,饿了吗,美团等。
如今硬件的性价比越来越高,网络传输速度越来越快,数据库分层的趋势逐渐显现,人们已经不再强求用一个解决方案来解决所有的存储问题,而是通过分层,让缓存与数据库负责各自擅长的业务场景。
当前数据库领域面临各种问题,如在缩放、一致性、大数据分析、与云基础架构集成等方面均存在诸多问题,现有的数据库解决方案和大数据分析引擎解决方案基本处于割裂的状态,由于 Oracle、MySQL 数据库并不是面向分布式环境而设计,因此即使勉强通过分库、分表或中间件的方式,在数据库层面做了分片,从本质上看也只是复制了相同的堆栈,而非针对分布式系统进行存储和计算优化,这正是进行跨业务查询或跨物理机查询和写入十分繁琐的本质原因。NoSQL 虽然解决了数据库弹性扩展的难题,但是却放弃了数据的强一致性以及对 ACID 事务的支持,带来了新的问题。
为了解决这一问题,TiDB 在架构上将计算和存储层进行高度的抽象和分离,对混合负载的场景通过 IO 优先级队列,智能副本调度,行列混合存储等技术使其变为可能。TiDB 作为开源的分布式关系数据库,其特点是几乎可以 100% 兼容 MySQL 接口,也兼容 MySQL 的语法和协议,在保证不丧失 ACID 事务的前提下,能够弹性伸缩,高可用,可以同时处理 OLTP 和 OLAP 工作负载,不再需要 ETL。
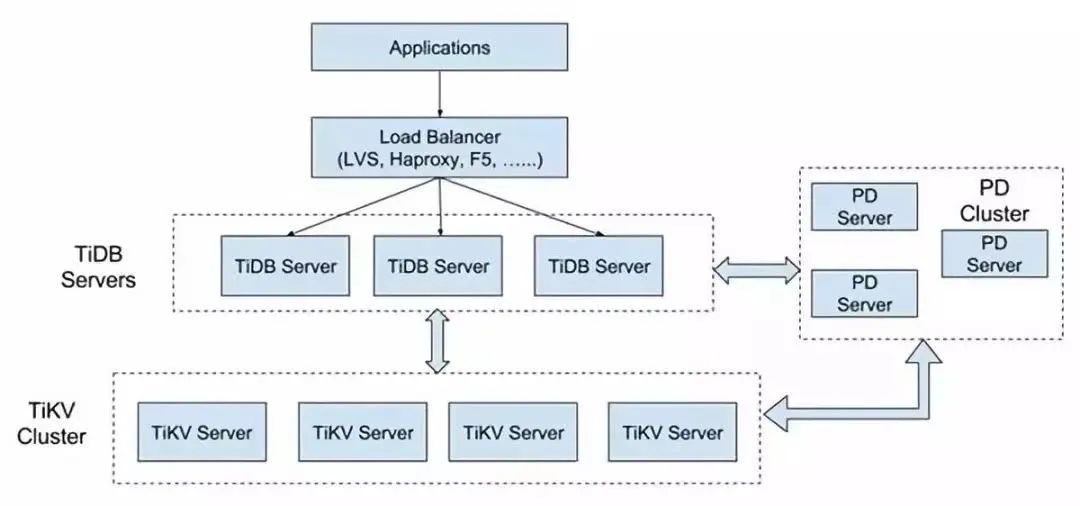
TiDB整体架构图
TiDB 产品的整体架构是高度分层的,由分布式 SQL 层(TiDB)、分布式 KV 存储引擎(TiKV)以及管理整个集群的 PD 模块组成。无限水平扩展是 TiDB 的一大特点,这里所说的水平扩展包括两方面:计算能力和存储能力。
HTAP 给开发者提供了一个实时数据分析方面的新思路,不需要再去维护另一个离线的数据仓库,既减轻了 ETL 的工作,又能节省很大一部分建立数据仓库所用到的存储和计算成本,HTAP 将是未来的重要趋势。黄东旭介绍了 TiDB 的四个主要应用场景,一是 MySQL 分片与合并;二是直接替换 MySQL;三是用做数据仓库;四是作为其他系统的一个模块。
用例1:MySQL分片与合并
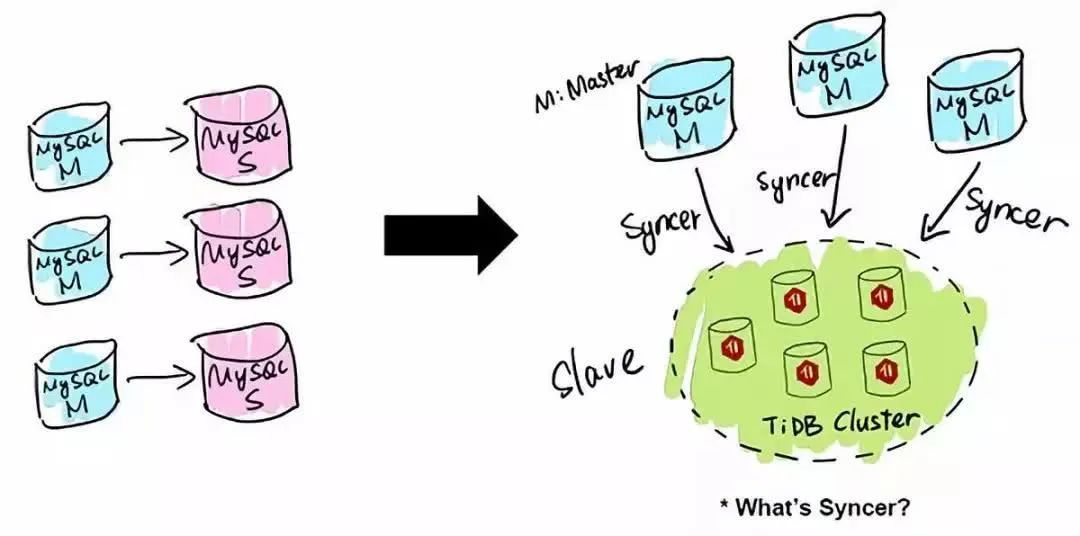
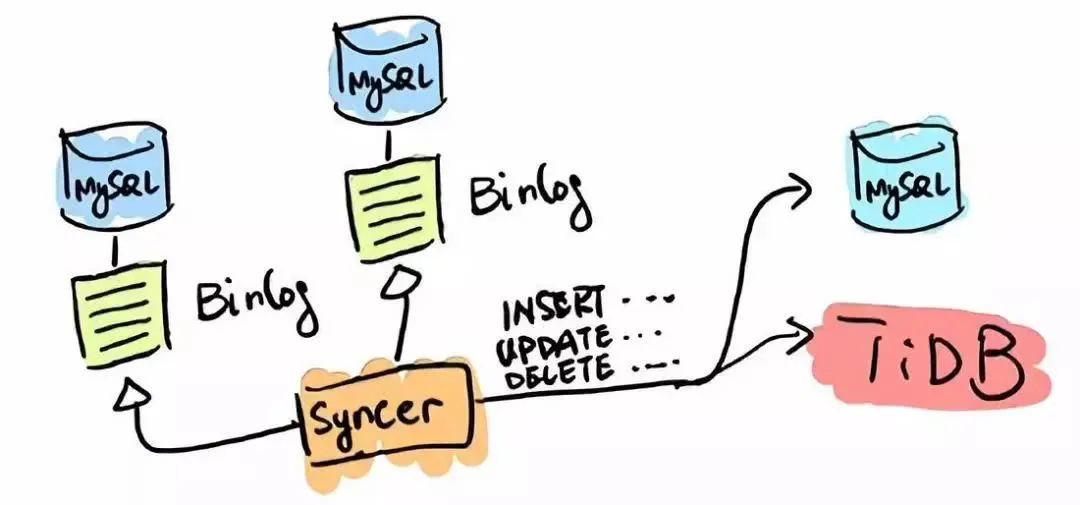
Syncer
TiDB 应用的第一类场景是 MySQL 的分片与合并。对于已经在用 MySQL 的业务,分库、分表、分片、中间件是常用手段,随着分片的增多,跨分片查询是一大难题。TiDB 在业务层兼容 MySQL 的访问协议,PingCAP 做了一个数据同步的工具——Syncer,它可以把 TiDB 作为一个 MySQL Slave,将 TiDB 作为现有数据库的从库接在主 MySQL 库的后方,在这一层将数据打通,可以直接进行复杂的跨库、跨表、跨业务的实时 SQL 查询。黄东旭提到,“过去的数据库都是一主多从,有了 TiDB 以后,可以反过来做到多主一从。”
用例2:直接替换MySQL
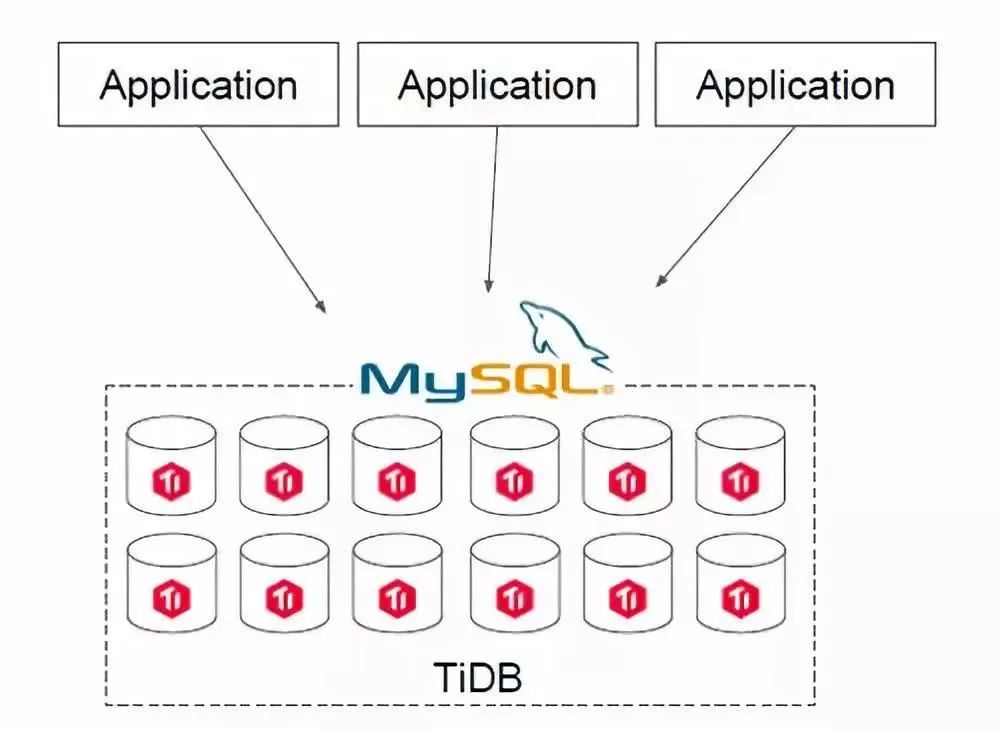
第二类场景是用 TiDB 直接去替换 MySQL。如果你的IT架构在搭建之初并未考虑分库分表的问题,全部用了 MySQL,随着业务的快速增长,海量高并发的 OLTP 场景越来越多,如何解决架构上的弊端呢?
在一个 TiDB 的数据库上,所有业务场景不需要做分库分表,所有的分布式工作都由数据库层完成。TiDB 兼容 MySQL 协议,所以可以直接替换 MySQL,而且基本做到了开箱即用,完全不用担心传统分库分表方案带来繁重的工作负担和复杂的维护成本,友好的用户界面让常规的技术人员可以高效地进行维护和管理。另外,TiDB 具有 NoSQL 类似的扩容能力,在数据量和访问流量持续增长的情况下能够通过水平扩容提高系统的业务支撑能力,并且响应延迟稳定。
黄东旭在演讲中提到了摩拜单车的案例,摩拜早期的数据库全部用 MySQL,随着业务的快速增长,MySQL 的弊端逐渐显现,摩拜单车于 2017 年初开始使用 TiDB 替换 MySQL。如今,摩拜的 IT 系统中已部署了数套 TiDB 集群,近百个节点,承载着数十 TB 的各类数据。
用例3:数据仓库
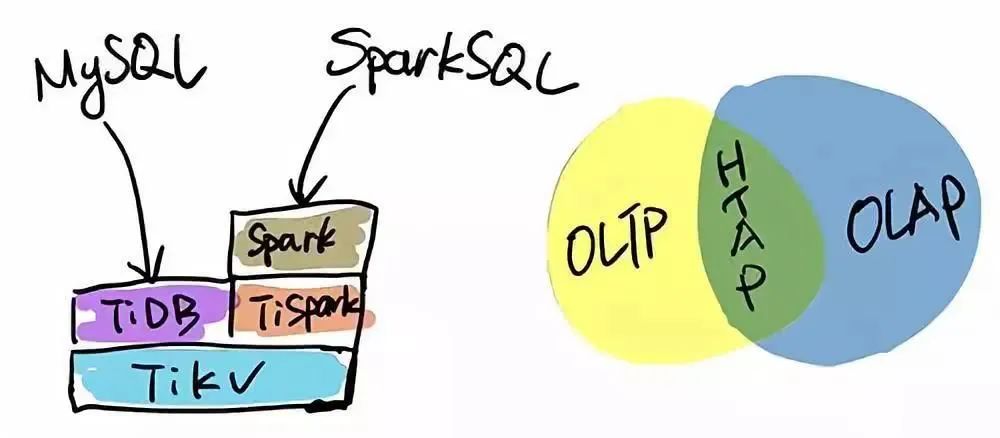
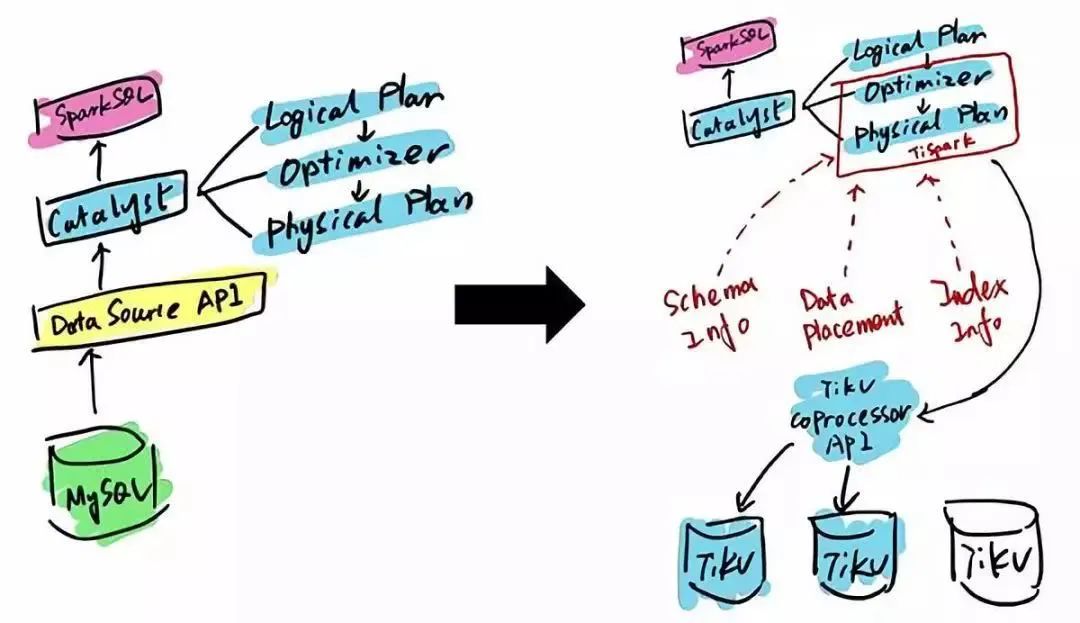
TiDB 本身是一个分布式系统,第三种使用场景是将 TiDB 当作数据仓库使用。TPC-H 是数据分析领域的一个测试集,TiDB 2.0 在 OLAP 场景下的性能有了大幅提升,原来只能在数据仓库里面跑的一些复杂的 Query,在 TiDB 2.0 里面跑,时间基本都能控制在 10 秒以内。当然,因为 OLAP 的范畴非常大,TiDB 的 SQL 也有搞不定的情况,为此 PingCAP 开源了 TiSpark,TiSpark 是一个 Spark 插件,用户可以直接用 Spark SQL 实时地在 TiKV 上做大数据分析。
用例4:作为其他系统的模块
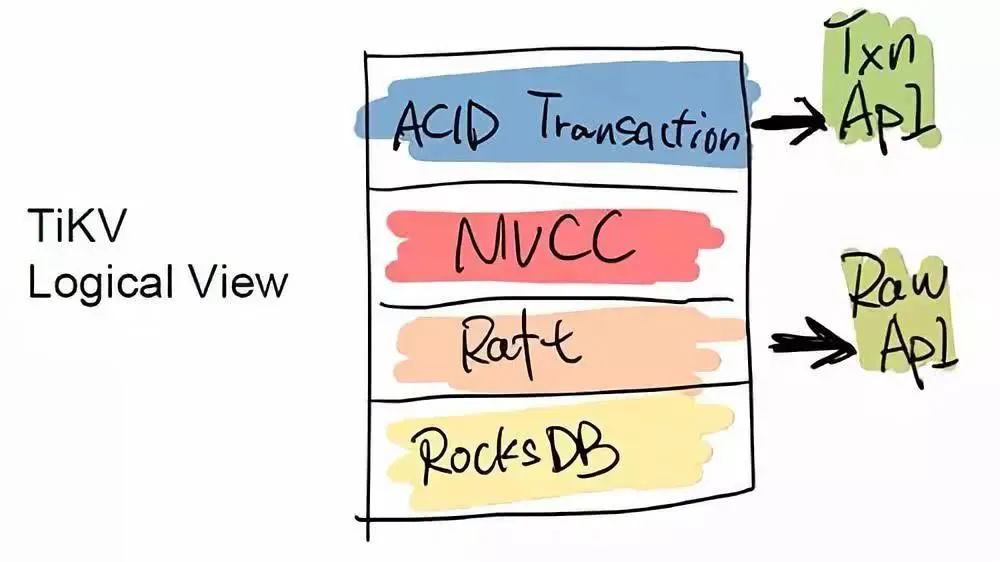
TiDB 是一个传统的存储跟计算分离的项目,其底层的 Key-Value 层,可以单独作为一个 HBase 的 Replacement 来用,它同时支持跨行事务。TiDB 对外提供两个 API 接口,一个是 ACID Transaction 的 API,用于支持跨行事务;另一个是 Raw API,它可以做单行的事务,换来的是整个性能的提升,但不提供跨行事务的 ACID 支持。用户可以根据自身的需求在两个 API 之间自行选择。例如有一些用户直接在 TiKV 之上实现了 Redis 协议,将 TiKV 替换一些大容量,对延迟要求不高的 Redis 场景。

本文分享自微信公众号 - 互联网后端架构(fullstack888)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。










