
一、Java NIO几个核心部分
- Channel
- Buffer
- Selector
二、IO和NIO的区别
IO 基于流(Stream oriented), 而 NIO 基于 Buffer (Buffer oriented)
在一般的 Java IO 操作中, 我们以流式的方式顺序地从一个 Stream 中读取一个或多个字节, 因此我们也就不能随意改变读取指针的位置
而 基于 Buffer 就显得有点不同了. 我们首先需要从 Channel 中读取数据到 Buffer 中, 当 Buffer 中有数据后, 我们就可以对这些数据进行操作了. 不像 IO 那样是顺序操作, NIO 中我们可以随意地读取任意位置的数据
IO 操作是阻塞的, 而 NIO是非阻塞的
Java 提供的各种 Stream 操作都是阻塞的, 例如我们调用一个 read 方法读取一个文件的内容, 那么调用 read 的线程会被阻塞住, 直到 read 操作完成.而 NIO 的非阻塞模式允许我们非阻塞地进行 IO 操作. 例如我们需要从网络中读取数据, 在 NIO 的非阻塞模式中, 当我们调用 read 方法时, 如果此时有数据, 则 read 读取并返回; 如果此时没有数据, 则 read 直接返回, 而不会阻塞当前线程
IO 没有 selector 概念, 而 NIO 有 selector 概念.
它是 Java NIO 之所以可以非阻塞地进行 IO 操作的关键.通过 Selector, 一个线程可以监听多个 Channel 的 IO 事件, 当我们向一个 Selector 中注册了 Channel 后, Selector 内部的机制就可以自动地为我们不断地查询(select) 这些注册的 Channel 是否有已就绪的 IO 事件(例如可读, 可写, 网络连接完成等). 通过这样的 Selector 机制, 我们就可以很简单地使用一个线程高效地管理多个 Channel了
三、Buffer
NIO Buffer 其实是这样的内存块的一个封装, 并提供了一些操作方法让我们能够方便地进行数据的读写.
3.1 Buffer 类型
- ByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
这些 Buffer 覆盖了能从 IO 中传输的所有的 Java 基本数据类型.
3.2 使用 NIO Buffer 的步骤
- 将数据写入到 Buffer 中.
- 调用 Buffer.flip()方法, 将 NIO Buffer 转换为读模式.
- 从 Buffer 中读取数据
- 调用 Buffer.clear() 或 Buffer.compact()方法, 将 Buffer 转换为写模式.
3.3 Buffer 属性
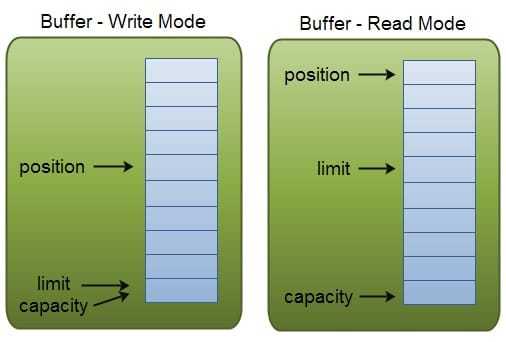
Capacity:一个内存块会有一个固定的大小, 即容量(capacity), 我们最多写入capacity 个单位的数据到 Buffer 中, 例如一个 DoubleBuffer, 其 Capacity 是100, 那么我们最多可以写入100个 double 数据.
Position:当从一个 Buffer 中写入数据时, 我们是从 Buffer 的一个确定的位置(position)开始写入的. 在最初的状态时, position 的值是0. 每当我们写入了一个单位的数据后, position 就会递增一. 当我们从 Buffer 中读取数据时, 我们也是从某个特定的位置开始读取的. 当我们调用了 filp()方法将 Buffer 从写模式转换到读模式时, position 的值会自动被设置为0, 每当我们读取一个单位的数据, position 的值递增1. position 表示了读写操作的位置指针.
limit:limit - position 表示此时还可以写入/读取多少单位的数据. 例如在写模式, 如果此时 limit 是10, position 是2, 则表示已经写入了2个单位的数据, 还可以写入 10 - 2 = 8 个单位的数据.
3.4 Buffer 方法
**Flip:**Flips this buffer. The limit is set to the current position and then the position is set to zero. If the mark is defined then it is discarded.,意思大概是这样的:调换这个buffer的当前位置,并且设置当前位置是0。说的意思就是:将缓存字节数组的指针设置为数组的开始序列即数组下标0。这样就可以从buffer开头,对该buffer进行遍历(读取)了。 flip方法将Buffer从写模式切换到读模式。调用flip()方法会将position设回0,并将limit设置成之前position的值。
**rewind:**Buffer.rewind()将position设回0,所以你可以重读Buffer中的所有数据。limit保持不变,仍然表示能从Buffer中读取多少个元素(byte、char等)
clear方法:一旦读完Buffer中的数据,需要让Buffer准备好再次被写入。可以通过clear()或compact()方法来完成。如果调用的是clear()方法,position将被设回0,limit被设置成 capacity的值。换句话说,Buffer 被清空了。Buffer中的数据并未清除,只是这些标记告诉我们可以从哪里开始往Buffer里写数据。如果Buffer中有一些未读的数据,调用clear()方法,数据将“被遗忘”,意味着不再有任何标记会告诉你哪些数据被读过,哪些还没有。
**compact()方法:**如果Buffer中仍有未读的数据,且后续还需要这些数据,但是此时想要先先写些数据,那么使用compact()方法。compact()方法将所有未读的数据拷贝到Buffer起始处。然后将position设到最后一个未读元素正后面。limit属性依然像clear()方法一样,设置成capacity。现在Buffer准备好写数据了,但是不会覆盖未读的数据。
mark方法:通过调用Buffer.mark()方法,可以标记Buffer中的一个特定position。之后可以通过调用Buffer.reset()方法恢复到这个position。例如:
3.4 Direct Buffer 和 Non-Direct Buffer 的区别
**Direct Buffer:**:所分配的内存不在 JVM 堆上, 不受 GC 的管理.(但是 Direct Buffer 的 Java 对象是由 GC 管理的, 因此当发生 GC, 对象被回收时, Direct Buffer 也会被释放) 因为 Direct Buffer 不在 JVM 堆上分配, 因此 Direct Buffer 对应用程序的内存占用的影响就不那么明显(实际上还是占用了这么多内存, 但是 JVM 不好统计到非 JVM 管理的内存.) 申请和释放 Direct Buffer 的开销比较大. 因此正确的使用 Direct Buffer 的方式是在初始化时申请一个 Buffer, 然后不断复用此 buffer, 在程序结束后才释放此 buffer. 使用 Direct Buffer 时, 当进行一些底层的系统 IO 操作时, 效率会比较高, 因为此时 JVM 不需要拷贝 buffer 中的内存到中间临时缓冲区中.
@Test
public void testDirectBuffer() throws IOException {
FileInputStream fis = new FileInputStream(this.infile);
FileChannel inChannel = fis.getChannel();
FileOutputStream fos = new FileOutputStream(this.outfile);
FileChannel outChannel = fos.getChannel();
/** * 分配一个直接缓冲区 * 给定一个直接字节缓冲区,Java虚拟机将尽最大努 力直接对它执行本机I/O操作。 * 也就是说,它会在每一次调用底层操作系统的本机I/O操作之前(或之后),尝试避免将缓冲区的内容拷贝到一个中间缓冲区中 或者从一个中间缓冲区中拷贝数据 */
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
while (true) {
//先清空缓冲区
buffer.clear();
int r = inChannel.read(buffer);
if (r == -1) {
break;
}
//从头开始
buffer.flip();
outChannel.write(buffer);
}
}
**Non-Direct Buffer:**:直接在 JVM 堆上进行内存的分配, 本质上是 byte[] 数组的封装. 因为 Non-Direct Buffer 在 JVM 堆中, 因此当进行操作系统底层 IO 操作中时, 会将此 buffer 的内存复制到中间临时缓冲区中. 因此 Non-Direct Buffer 的效率就较低.
@Test
public void testMappedBuffer() throws IOException {
RandomAccessFile accessFile = new RandomAccessFile(this.infile,"rw");
FileChannel fileChannel = accessFile.getChannel();
/** * 可以锁定文件的一部分, * 要获取文件的一部分上的锁,您要调用一个打开的 FileChannel 上的 lock() 方法。 * 注意,如果要获取一个排它锁,您必须以写方式打开文件。 */
FileLock lock=fileChannel.lock();
lock.release();
/** * 内存映射文件 I/O 是通过使文件中的数据神奇般地出现为内存数组的内容来完成的。 * 这其初听起来似乎不过就是将整个文件读到内存中,但是事实上并不是这样。 * 一般来说,只有文件中实际读取或者写入的部分才会送入(或者 映射 )到内存中 */
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, 1024);
byte[] ss = new byte[1024];
mappedByteBuffer.get(ss);
System.out.println(new String(ss));
fileChannel.close();
}
private void displayBuffer(Buffer buffer) {
System.out.println("capacity: " + buffer.capacity());
System.out.println("position: " + buffer.position());
System.out.println("limit: " + buffer.limit());
System.out.println("-------------------------");
}
private void displayBufferData(IntBuffer buffer) {
while (buffer.hasRemaining()) {
System.out.print(buffer.get());
}
System.out.println();
}
3.5 示例
@Test
public void testBuffer() {
//分配指定大小的缓冲区
IntBuffer buffer = IntBuffer.allocate(10);
//包装一个现有的数组
int[] arr = new int[10];
IntBuffer buffer1 = IntBuffer.wrap(arr);
this.displayBuffer(buffer);
for (int i = 0; i < 10; i++) {
buffer.put(i);
}
this.displayBuffer(buffer);
//把limit设为当前位置position,position设为0
this.displayBuffer(buffer.flip());
while (buffer.hasRemaining()) {
System.out.print(buffer.get());
}
this.displayBuffer(buffer);
//limit不变,position设为0
this.displayBuffer(buffer.rewind());
this.displayBuffer(buffer.limit(5));
//从头开始,把limit设为capacity,position设为0
this.displayBuffer(buffer.clear());
this.displayBufferData(buffer);
this.displayBuffer(buffer);
//创建子缓冲区,子缓冲区的数据与原缓冲区数据是共享的,修改子缓冲区数据,原缓冲区的部分数据也会发生变化
buffer.position(3);
buffer.limit(7);
IntBuffer sliceBuffer = buffer.slice();
displayBufferData(sliceBuffer);
//创建只读缓冲区,与原缓冲区一样数据共享,但只能读
IntBuffer readonlyBuffer = buffer.asReadOnlyBuffer();
}
四、Channel
Channel 类型有:
- FileChannel, 文件操作
- DatagramChannel, UDP 操作
- SocketChannel, TCP 操作
- ServerSocketChannel, TCP 操作, 使用在服务器端.这些通道涵盖了 UDP 和 TCP网络 IO以及文件 IO.
4.1 Java NIO FileChannel文件通道
Java NIO中的FileChannel是用于连接文件的通道。通过文件通道可以读、写文件的数据。Java NIO的FileChannel是相对标准Java IO API的可选接口。FileChannel不可以设置为非阻塞模式,他只能在阻塞模式下运行。
public class ChannelMain {
public static void main(String[] args) throws Exception {
String str = "this is channel main hello world";
// 构建一个输出流
FileOutputStream outputStream = new FileOutputStream("/Users/wangjun/Downloads/test.txt");
// 获取channel
FileChannel channel = outputStream.getChannel();
// 获取Byte Buffer
ByteBuffer buffer = ByteBuffer.wrap(str.getBytes());
// 写入到通道
channel.write(buffer);
// 关闭通道
channel.close();
}
}
force方法会把所有未写磁盘的数据都强制写入磁盘。这是因为在操作系统中出于性能考虑回把数据放入缓冲区,所以不能保证数据在调用write写入文件通道后就及时写到磁盘上了,除非手动调用force方法。 force方法需要一个布尔参数,代表是否把meta data也一并强制写入。
channel.force(true);
4.2 Java NIO SocketChannel套接字通道
在Java NIO体系中,SocketChannel是用于TCP网络连接的套接字接口,相当于Java网络编程中的Socket套接字接口。创建SocketChannel主要有两种方式,如下:
打开一个SocketChannel并连接网络上的一台服务器。
当ServerSocketChannel接收到一个连接请求时,会创建一个SocketChannel。
public class SocketChannelMain { public static void main(String[] args) throws Exception { SocketChannel socketChannel = SocketChannel.open(); socketChannel.connect(new InetSocketAddress("127.0.0.1", 3000)); ByteBuffer buffer = ByteBuffer.allocate(1024); int read = socketChannel.read(buffer); System.out.println(read); String newData = "New String to write to file..." + System.currentTimeMillis(); ByteBuffer buf = ByteBuffer.allocate(48); buf.clear(); buf.put(newData.getBytes()); buf.flip(); while (buf.hasRemaining()) { socketChannel.write(buf); } //设置 SocketChannel 为异步模式, 这样我们的 connect, read, write 都是异步的了 socketChannel.configureBlocking(false); socketChannel.connect(new InetSocketAddress("http://example.com", 80)); //在异步模式中, 或许连接还没有建立, connect 方法就返回了, 因此我们需要检查当前是否是连接到了主机, 因此通过一个 while 循环来判断 while (!socketChannel.finishConnect()) { //wait, or do something else... } } }
4.3 Java NIO ServerSocketChannel服务端套接字通道
在Java NIO中,ServerSocketChannel是用于监听TCP链接请求的通道,正如Java网络编程中的ServerSocket一样。
ServerSocketChannel实现类位于java.nio.channels包下面。 下面是一个示例程序:
public class ServerSocketChannelMain {
public static void main(String[] args) throws Exception {
blockModel();
notBlockModel();
}
private static void notBlockModel() throws Exception {
//非阻塞模式下, accept()是非阻塞的, 因此如果此时没有连接到来, 那么 accept()方法会返回null
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.socket().bind(new InetSocketAddress(9999));
serverSocketChannel.configureBlocking(false);
while(true){
SocketChannel socketChannel = serverSocketChannel.accept();
if(socketChannel != null){
//do something with socketChannel...
}
}
}
private static void blockModel() throws IOException {
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.socket().bind(new InetSocketAddress(9999));
ByteBuffer buffer = ByteBuffer.allocate(1024);
while (true) {
/* * 使用ServerSocketChannel.accept()方法来监听客户端的 TCP 连接请求, * accept()方法会阻塞, 直到有连接到来, 当有连接时, 这个方法会返回一个 SocketChannel 对象 */
SocketChannel socketChannel = serverSocketChannel.accept();
int read = socketChannel.read(buffer);
buffer.flip();
System.out.println(buffer.toString());
}
}
}
4.4 Java NIO DatagramChannel数据报通道
一个Java NIO DatagramChannel是一个可以发送、接收UDP数据包的通道。由于UDP是面向无连接的网络协议,我们不可用像使用其他通道一样直接进行读写数据。正确的做法是发送、接收数据包。
package com.tim.wang.sourcecode.netty.nio.channel;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.DatagramChannel;
/** * @author wangjun * @date 2020-07-22 */
public class DatagramChannelMain {
public static void main(String[] args) throws Exception {
//打开
DatagramChannel channel = DatagramChannel.open();
channel.socket().bind(new InetSocketAddress(9999));
//读取数据
ByteBuffer buf = ByteBuffer.allocate(48);
buf.clear();
channel.receive(buf);
//发送数据
String newData = "New String to write to file..."
+ System.currentTimeMillis();
ByteBuffer buffer = ByteBuffer.allocate(48);
buffer.clear();
buffer.put(newData.getBytes());
buffer.flip();
int bytesSent = channel.send(buf, new InetSocketAddress("example.com", 80));
/* *连接到指定地址 *因为 UDP 是非连接的, 因此这个的 connect 并不是向 TCP 一样真正意义上的连接, 而是它会讲 DatagramChannel 锁住, 因此我们仅仅可以从指定的地址中读取或写入数据. */
channel.connect(new InetSocketAddress("example.com", 80));
}
}
4.5 Java NIO Scatter / Gather
Java NIO发布时内置了对scatter / gather的支持。scatter / gather是通过通道读写数据的两个概念。
Scattering read指的是从通道读取的操作能把数据写入多个buffer,也就是sctters代表了数据从一个channel到多个buffer的过程。
gathering write则正好相反,表示的是从多个buffer把数据写入到一个channel中。
Scatter/gather在有些场景下会非常有用,比如需要处理多份分开传输的数据。举例来说,假设一个消息包含了header和body,我们可能会把header和body保存在不同独立buffer中,这种分开处理header与body的做法会使开发更简明。
4.5.1 Scattering Reads
"scattering read"是把数据从单个Channel写入到多个buffer,下面是示意图: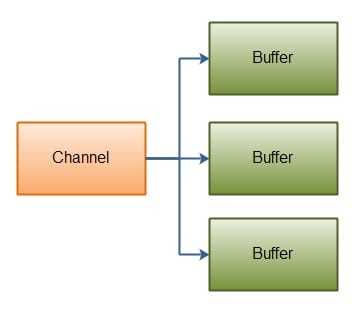
Java NIO: Scattering Read
ByteBuffer header = ByteBuffer.allocate(128);
ByteBuffer body = ByteBuffer.allocate(1024);
ByteBuffer[] bufferArray = { header, body };
channel.read(bufferArray);
观察代码可以发现,我们把多个buffer写在了一个数组中,然后把数组传递给channel.read()方法。read()方法内部会负责把数据按顺序写进传入的buffer数组内。一个buffer写满后,接着写到下一个buffer中。
实际上,scattering read内部必须写满一个buffer后才会向后移动到下一个buffer,因此这并不适合消息大小会动态改变的部分,也就是说,如果你有一个header和body,并且header有一个固定的大小(比如128字节),这种情形下可以正常工作。
4.5.2 Gathering Writes
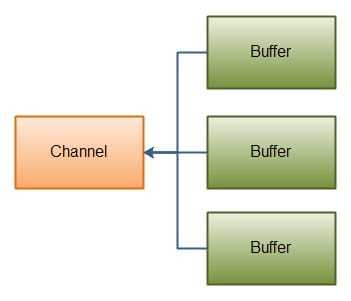
"gathering write"把多个buffer的数据写入到同一个channel中,下面是示意图:
Java NIO: Gathering Write
用代码表示的话如下:
ByteBuffer header = ByteBuffer.allocate(128);
ByteBuffer body = ByteBuffer.allocate(1024);
//write data into buffers
ByteBuffer[] bufferArray = { header, body };
channel.write(bufferArray);
类似的传入一个buffer数组给write,内部机会按顺序将数组内的内容写进channel,这里需要注意,写入的时候针对的是buffer中position到limit之间的数据。也就是如果buffer的容量是128字节,但它只包含了58字节数据,那么写入的时候只有58字节会真正写入。因此gathering write是可以适用于可变大小的message的,这和scattering reads不同。
4.6 Java NIO Channel to Channel Transfers通道传输接口
Java NIO发布时内置了对scatter / gather的支持。scatter / gather是通过通道读写数据的两个概念。
Scattering read指的是从通道读取的操作能把数据写入多个buffer,也就是sctters代表了数据从一个channel到多个buffer的过程。
gathering write则正好相反,表示的是从多个buffer把数据写入到一个channel中。
Scatter/gather在有些场景下会非常有用,比如需要处理多份分开传输的数据。举例来说,假设一个消息包含了header和body,我们可能会把header和body保存在不同独立buffer中,这种分开处理header与body的做法会使开发更简明。
https://github.com/guang19/framework-learning/blob/dev/netty-learning/ByteBuf%E5%AE%B9%E5%99%A8.md
https://github.com/bingbo/blog/wiki/Java\_nio
https://github.com/feixueck/whatsmars/wiki/NIO-NIO-vs.-IO
https://wiki.jikexueyuan.com/project/java-nio-zh/java-nio-buffer.html











