
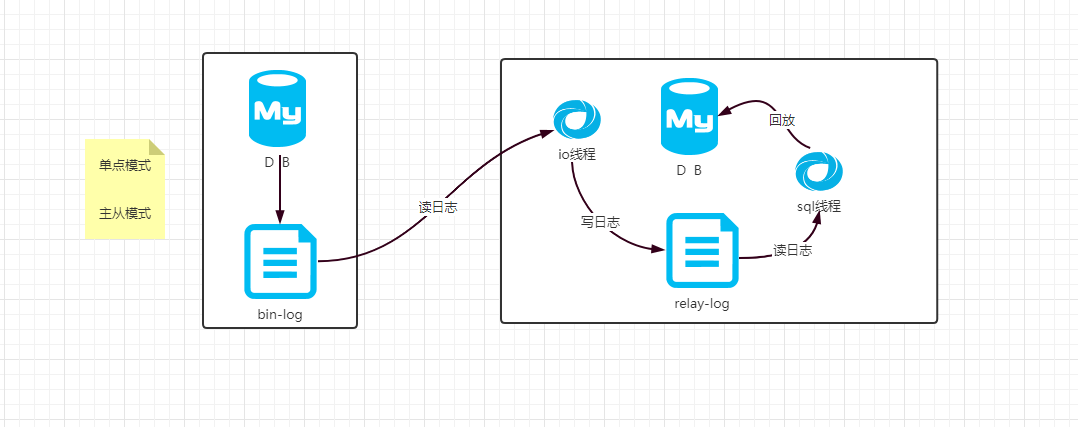
什么是主从复制
当mysql数据库的数据量太大的时候,查询数据就很吃力了,无论怎么优化都会产生瓶颈,这时我们需要增加服务器设备来实现分布式数据库,首先要了解主从数据库服务器的版本的需求,主从mysql的安装运行版本需一致。因此,我们利用mysql自带的REPLICATION来实现mysql多机主从同步的功能,mysql版本为5.7进行演示。
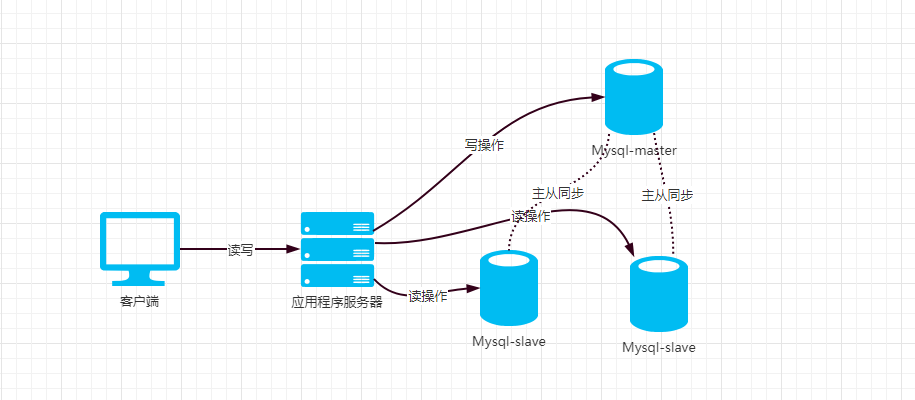
什么是读写分离
就是把对数据库的读操作和写操作分离开,将读写压力分担到多台服务器上,通常用于读远大于写的场景。读写分离的基本原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。数据多了之后,对数据库的读、写就会很多。写库就一个,读库可以有多个,利用主从复制负责主库和多个读库的数据同步。
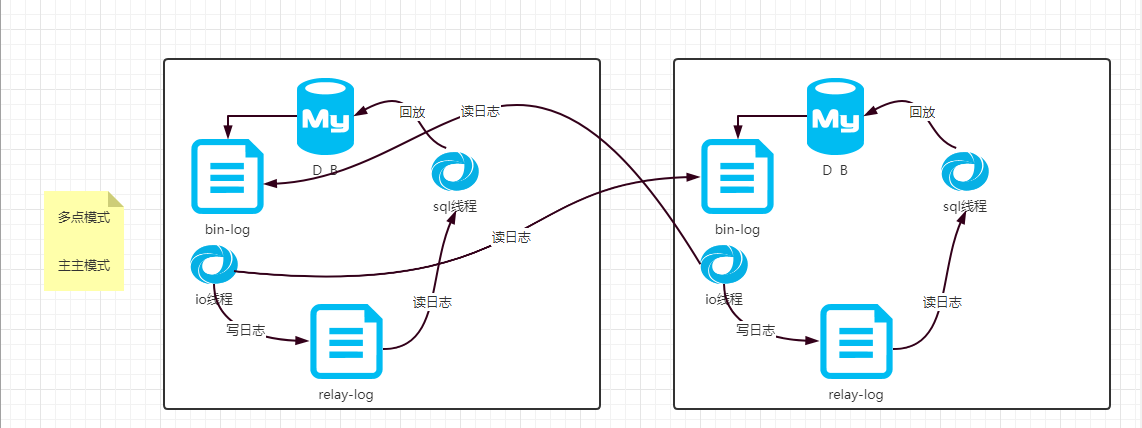
什么是双机热备(互为主从)
互为主从也叫主主同步,是在主从同步的基础上还增加了,主也同步从的bin-log,利用 keepalive的虚拟ip 也叫vip 他的作用就是监控两个数据库 默认设置是master1,如果master1挂了就去Master2 ,如果master2挂了就去master1,消除了以往一主一从和一主多从的 master单点问题,由此可以实现数据库的高可用。
主从同步配置的步骤
1、master:修改数据库配置文件vi /etc/my.cnf
2、master:给slave数据库放权,创建一个用于同步的账户,密码,并授予bin-log权限
3、slave:修改数据库配置文件vi /etc/my.cnf
4、slave:设置2创建的账户 master_host , master_user, master_password
主从同步方式
我们平时所提到的主从同步,主主同步默认采取的异步同步方式, 从MySQL5.5开始,MySQL以插件的形式支持半同步复制。如何理解半同步呢?首先我们来看看异步,全同步的概念
异步复制(Asynchronous replication)
MySQL默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主如果crash掉了,此时主上已经提交的事务可能并没有传到从上,如果此时,强行将从提升为主,可能导致新主上的数据不完整。
全同步复制(Fully synchronous replication)
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。
半同步复制(Semisynchronous replication)
介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。
下面来看看半同步复制的原理图:

java读写分离动态切换数据源
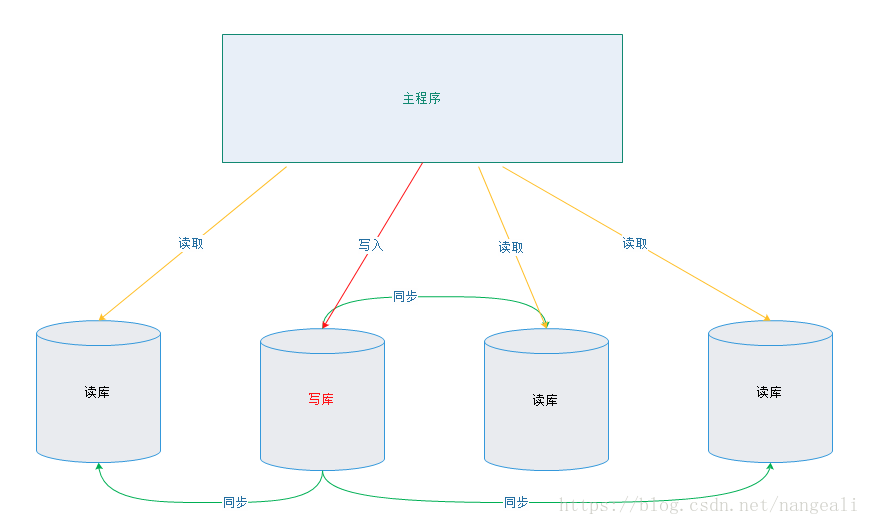
1.手写DynamicDataSource extends AbstractRoutingDataSource 实现determineCurrentLookupKey方法,HandleDataSource.get()取出值,可以是数据源名称也可以根据取出值实现多从的负载均衡
2.配置多个数据源名称master,salve1,salve2....,都组装到DynamicDataSource targetDateSource中去
3. 手写HandleDataSource用线程变量来存放当前线程数据源
4. 手写一个DataSourceAspect切面,切入点sql语句前缀(select,update,delete,insert) 或者注解自定义注解(如@DateSource("salve2"))将对应数据源名称或自定义值设置到HandleDataSource中











