
此文已由作者温正湖授权网易云社区发布。
欢迎访问网易云社区,了解更多网易技术产品运营经验。
一、RDS外部实例迁移需求
RDS(关系型数据库服务)作为网易云计算的基础性组件,已经承载了公司多个产品的数百个的数据库实例,且在可以预期的时间内,RDS线上的实例数量还会快速增加。在目前这些实例中有不少是从非云环境(物理机)迁移过来的,基本上由DBA手动完成。需要执行在物理机实例上使用xtrabackup备份MySQL实例的数据,创建新的RDS实例,将备份的数据覆盖掉空的MySQL数据目录等将近二十步的操作,且极易出错,效率较低。后续还将有大量(数百个)的杭州、北京和广州的业务实例会迁移到RDS上来,提供一个方便而又高效的备份和恢复工具,将DBA从繁琐的实例迁移中解放出来刻不容缓。
在调研业界相关产品时发现,Amazon RDS未提供成套的外部实例迁移到RDS的工具,Aliyun RDS提供了自建实例迁移到RDS的平台,通过使用和分析发现,其采用的备份工具是mysqldump,由于Aliyun RDS针对的用户数据量一般较小,使用mysqldump来进行数据迁移不会有太大的瓶颈问题,但网易的很多项目都是数据量很大的,举网易163博客为例,包含众多的数据库实例,实例很多都是几百G的数据量,云阅读、lofter等也是类似的情况,使用单线程的mysqldump效率不高。
我们曾计划使用xtrabackup作为迁移平台的工具,因为其物理数据拷贝性能更为优越,同时工具也非常成熟可靠。但xtrabackup目前还无法备份远端的数据库实例,仅支持将本地实例数据备份远端,所以使用xtrabackup就需要有远端数据库实例所在主机的登陆权限,这大大增加了系统的侵入性,不符合RDS的设计思想。同时逻辑备份相对于物理备份的一大好处是,备份集的大小一般远小于当前的数据库实例的数据大小,这样可以有效的减少网络资源的开销,对缩短备份时间也有不小帮助。举已经迁移的一个网易北京数据库实例为例,当前的数据大小为140G,mydumper导出的数据为37G,myloader恢复出来的实例大小为71G。减小了一半,这主要是因为逻辑备份和恢复潜在地具备系统库中无用的数据清理和存储碎片整理功能。
mydumper的多线程数据备份和恢复及非倾入性特点非常适用于网易RDS。目前,基于mydumper的RDS外部实例一键迁移平台已经开发完成并上线迁移了数十个实例,得到DBA兄弟们的认可。
二、RDS对mydumper改进优化
在将mydumper封装为RDS的外部实例一键迁移平台过程中,也发现了几个mydumper的不足,主要包括在schema导出功能上仍不够成熟、多线程导出(备份)可能影响备份实例的正常业务访问等,下面对其一一进行介绍并在RDS一键迁移平台中提供的解决方案。
首先是schema导出上,直到最新的mydumper 0.6.2版本,其代码实现为对MySQL实例执行“show create table dbname.tablename”。所以,视图、触发器、函数和存储过程无法通过mydumper导出。目前业界折中的办法是在备份时使用mysqldump来导出schema,再用mydumper来导出数据,但这既麻烦同时对schema和数据的一致性也多少说有些影响,RDS目前同样采用该方法来规避mydumper的这个缺陷。幸运的是,mydumper的下一个版本mydumper 0.9.1的主要优化点就是解决该问题,launchpad的mydumper项目(https://launchpad.net/mydumper/+milestone/0.9.1)是这么描述该版本的--“Add support all schema objects”,查看代码发现该功能已经实现,相信不久即可使用。
其次是多线程导出的自适应能力上,多线程导出固然好,但毕竟在备份时往往数据库还在正常提供对外服务,就像上述的那样,多线程全表select数据会占用很大部分的系统IO能力,导致正常的业务IO性能下降,此外,逻辑备份的全表select也会污染buffer pool的热点数据,导致缓存的热点数据被换出,降低了命中率的同时增大了业务的IO量。如何在高效导出数据的同时又能够兼顾到线上业务的性能呢? 我们主要从以下两个方面来减低对业务的影响:
第一点,也是很重要的一点是,多线程的自适应导出能力;我们优化了mydumper的多线程数据导出的行为。每个线程在每次数据导出前,都会首先观察实例的当前负载情况,举MySQL状态Thread_connected为例,其反映的是目前已连接到该实例的请求数,如果该数值大于我们设定的阈值,则本次导出操作会暂停,直到数值小于阈值才会恢复,这样就起到了根据线上的负载情况,灵活的调整用于数据导出的线程数来适应线上业务负载的作用。RDS一键迁移平台为用户提供了差异化的监控项选择,可以指定“show global status”中的任意一项或多项状态参数(非数值型状态除外)作为监控项。
第二点,尽量减小对InnoDB Buffer Pool的影响;通过调整Buffer Pool的热点算法,使得热点数据尽可能不被换出。修改的参数是innodb_old_blocks_time和innodb_old_blocks_pct,用于将全表select进入Buffer Pool放在其old sublist中,同时减小old sublist块在Buffer Pool中的比例,起到最小化污染的作用。其原理详见http://dev.mysql.com/doc/innodb-plugin/1.0/en/idm47548325357504.html
此外,在数据导出过程中,由于MyISAM表是非事务的,为了得到一致性的数据,导出MyISAM需要加锁。在通常的MySQL实例中,MyISAM表数据都是很少的,所以持锁时间很短,但若有实例存在大量的MyISAM表数据,那么就会因持锁时间过长对线上业务数据更新和插入造成影响。因此,RDS为mydumper加了-H的参数用来进行持锁时间超时判断,默认为60s,若超出这个值,mydumper返回失败。
目前,这些改进均已集成到RDS的迁移平台上,迁移平台为实例迁移提供了较大便利,相信不会令您失望。最后简单介绍下RDS的外部实例迁移操作。选择RDS的实例管理界面,你会发现“开始外部实例迁移”按钮,点击它就会弹出图1。
图1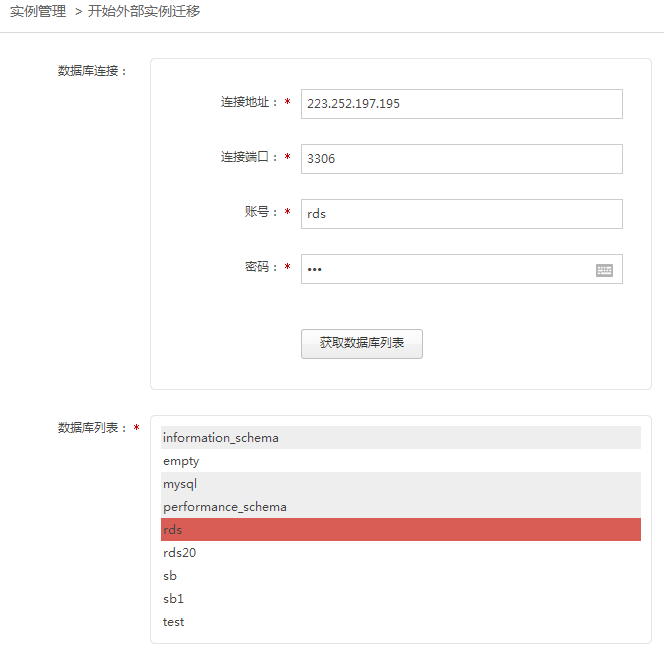
只需分别输入待迁移的外部实例的IP地址、端口、用户迁移的用户和密码(需要赋予该用户必要的迁移权限,最简单的方法就是赋予“all”权限了)。点击“获取数据库列表”,如果你输入的连接参数是对的,那么将出现数据库列表,你可以选中一个或多个需要迁移的数据库。再配置图2的这些参数,当然你也可以不配置,因为我们为你贴心准备了默认的值。
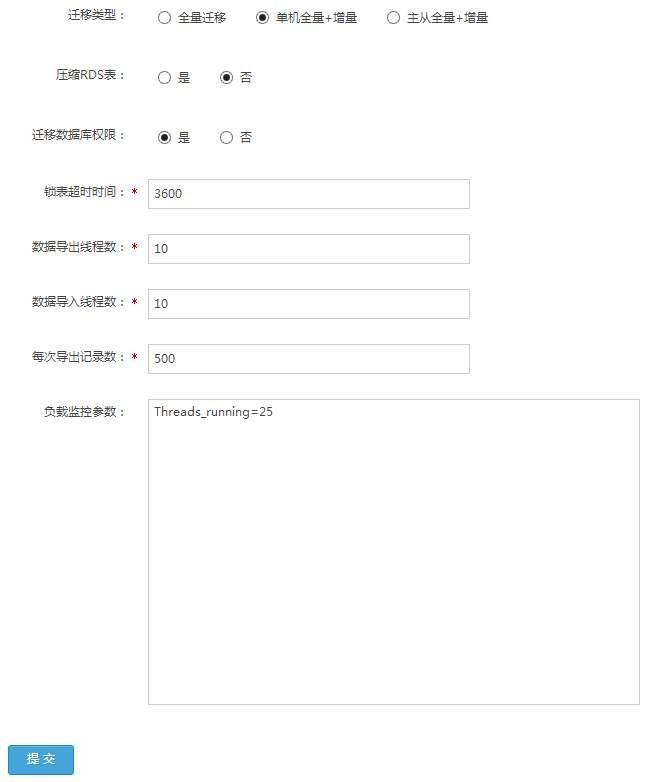
图2
如果确认这些参数无误,这么请点击“提交”开始迁移过程吧。在迁移中,你可以通过点击“查看外部实例迁移”来看迁移的进度(外部实例数据导出、数据导入到RDS和增量数据同步),界面如图3。
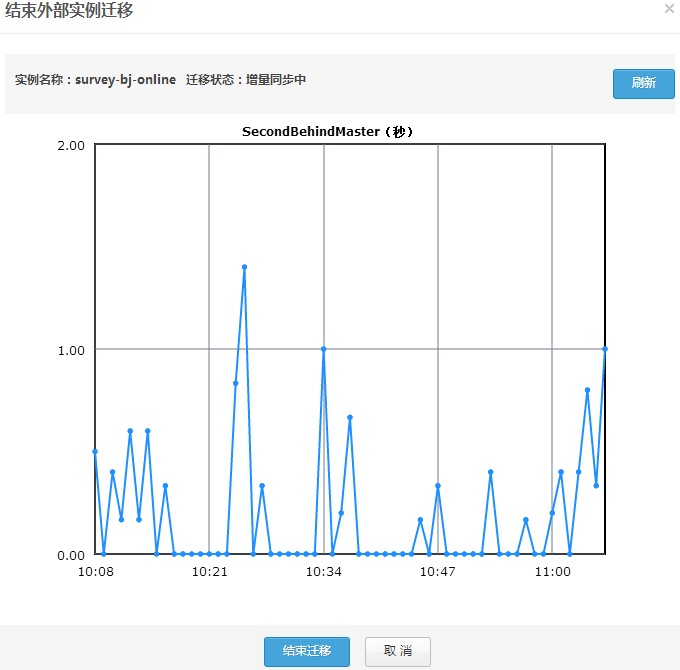
图3
如果到达增量数据同步阶段,且RDS实例已经基本上跟上外部实例。那么就可以考虑切应用的业务到RDS实例上了,完成后点击“结束迁移”即可。是不是很简单!!! 感兴趣的读者不凡试用下
网易云免费体验馆,0成本体验20+款云产品!
更多网易技术、产品、运营经验分享请点击。
相关文章:
【推荐】 DDoS 攻击与防御:从原理到实践
【推荐】 移动端爬虫工具与方法介绍












