
数据驱动模式的测试好处相比普通模式的测试就显而易见了吧!使用数据驱动的模式,可以根据业务分解测试数据,只需定义变量,使用外部或者自定义的数据使其参数化,从而避免了使用之前测试脚本中固定的数据。可以将测试脚本与测试数据分离,使得测试脚本在不同数据集合下高度复用。不仅可以增加复杂条件场景的测试覆盖,还可以极大减少测试脚本的编写与维护工作。
下面将使用Python下的数据驱动模式(ddt)库,结合unittest库以数据驱动模式创建百度搜索的测试。
ddt库包含一组类和方法用于实现数据驱动测试。可以将测试中的变量进行参数化。
可以通过python自带的pip命令进行下载并安装:pip install ddt . 更多关于ddt的信息可以参考:
一个简单的数据驱动测试
为了创建数据驱动测试,需要在测试类上使用@ddt装饰符,在测试方法上使用@data装饰符。@data装饰符把参数当作测试数据,参数可以是单个值、列表、元组、字典。对于列表,需要用@unpack装饰符把元组和列表解析成多个参数。
下面实现百度搜索测试,传入搜索关键词和期望结果,代码如下:
import unittest
from selenium import webdriver
from ddt import ddt, data, unpack
@ddt
class SearchDDT(unittest.TestCase):
'''docstring for SearchDDT'''
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.driver.maximize_window()
self.driver.get("https://www.baidu.com")
# specify test data using @data decorator
@data(('python', 'PyPI'))
@unpack
def test_search(self, search_value, expected_result):
search_text = self.driver.find_element_by_id('kw')
search_text.clear()
search_text.send_keys(search_value)
search_button = self.driver.find_element_by_id('su')
search_button.click()
tag = self.driver.find_element_by_link_text("PyPI").text
self.assertEqual(expected_result, tag)
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main(verbosity=2)
在test_search()方法中,search_value与expected_result两个参数用来接收元组解析的数据。当运行脚本时,ddt把测试数据转换为有效的python标识符,生成名称为更有意义的测试方法。结果如下:

使用外部数据的数据驱动测试
如果外部已经存在了需要的测试数据,如一个文本文件、电子表格或者数据库,那也可以用ddt来直接获取数据并传入测试方法进行测试。
下面将借助外部的CSV(逗号分隔值)文件和EXCLE表格数据来实现ddt。
通过CSV获取数据
同上在@data装饰符使用解析外部的CSV(testdata.csv)来作为测试数据(代替之前的测试数据)。其中数据如下:
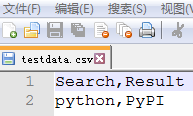
接下来,先要创建一个get_data()方法,其中包括路径(这里默认使用当前路径)、CSV文件名。调用CSV库去读取文件并返回一行数据。再使用@ddt及@data实现外部数据驱动测试百度搜索,代码如下:
import csv, unittest
from selenium import webdriver
from ddt import ddt, data, unpack
def get_data(file_name):
# create an empty list to store rows
rows = []
# open the CSV file
data_file = open(file_name, "r")
# create a CSV Reader from CSV file
reader = csv.reader(data_file)
# skip the headers
next(reader, None)
# add rows from reader to list
for row in reader:
rows.append(row)
return rows
@ddt
class SearchCSVDDT(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.driver.maximize_window()
self.driver.get("https://www.baidu.com")
# get test data from specified csv file by using the get_data funcion
@data(*get_data('testdata.csv'))
@unpack
def test_search(self, search_value, expected_result):
search_text = self.driver.find_element_by_id('kw')
search_text.clear()
search_text.send_keys(search_value)
search_button = self.driver.find_element_by_id('su')
search_button.click()
tag = self.driver.find_element_by_link_text("PyPI").text
self.assertEqual(expected_result, tag)
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main(verbosity=2)
测试执行时,@data将调用get_data()方法读取外部数据文件,并将数据逐行返回给@data。执行的结果也同上~
通过Excel获取数据
测试中经常用Excle存放测试数据,同上在也可以使用@data装饰符来解析外部的CSV(testdata.csv)来作为测试数据(代替之前的测试数据)。其中数据如下:
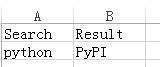
接下来,先要创建一个get_data()方法,其中包括路径(这里默认使用当前路径)、EXCEL文件名。调用xlrd库去读取文件并返回数据。再使用@ddt及@data实现外部数据驱动测试百度搜索,代码如下:
import xlrd, unittest
from selenium import webdriver
from ddt import ddt, data, unpack
def get_data(file_name):
# create an empty list to store rows
rows = []
# open the CSV file
book = xlrd.open_workbook(file_name)
# get the frist sheet
sheet = book.sheet_by_index(0)
# iterate through the sheet and get data from rows in list
for row_idx in range(1, sheet.nrows): #iterate 1 to maxrows
rows.append(list(sheet.row_values(row_idx, 0, sheet.ncols)))
return rows
@ddt
class SearchEXCLEDDT(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.driver.maximize_window()
self.driver.get("https://www.baidu.com")
# get test data from specified excle spreadsheet by using the get_data funcion
@data(*get_data('TestData.xlsx'))
@unpack
def test_search(self, search_value, expected_result):
search_text = self.driver.find_element_by_id('kw')
search_text.clear()
search_text.send_keys(search_value)
search_button = self.driver.find_element_by_id('su')
search_button.click()
tag = self.driver.find_element_by_link_text("PyPI").text
self.assertEqual(expected_result, tag)
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main(verbosity=2)
与上面读取CVS文件一样,测试执行时,@data将调用get_data()方法读取外部数据文件,并将数据逐行返回给@data。执行的结果也同上~
如果想从数据库的库表中获取数据,同样也需要一个get_data()方法,并且通过DB相关的库来连接数据库、SQL查询来获取测试数据。












