
0. 前言
近日我们在开发符合我们业务自身需求的微服务平台时,使用了 Kubernetes 的 Operator Pattern 来实现其中的运维系统,在本文,我们将实现过程中积累的主要知识点和技术细节做了一个整理。
读者在阅读完本文之后,会对 Operator Pattern 有一个基本的了解,并能将该模式应用到自己的业务中去。除此之外,我们也会分享要实现这一运维系统需要具备的一些相关知识。
注:阅读本文内容需要对 Kubernetes 和 Go 语言有基本了解。
1. 什么是 Operator Pattern
在解释什么是 Operator Pattern 之前,我们得先了解在我们使用一个 Kubernetes 客户端——这里以 kubectl 举例——向 Kubernetes 集群发出指令,直到这项指令被 Kubernetes 集群执行结束,这段时间之内到底都发生了什么。
这里以我们输入_ kubectl create -f ns-my-workspace.yaml_ 这条命令举例,这条命令的整条执行链路大致如下图所示:
### ns-my-workspace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: my-workspace
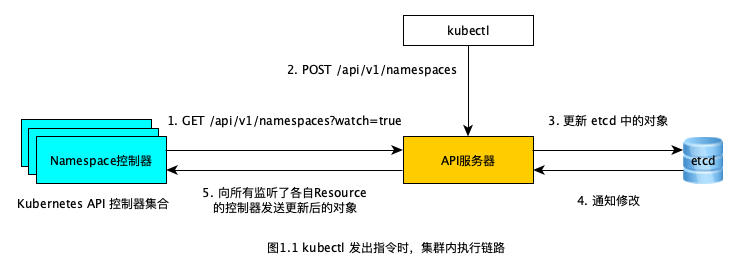 如上图所示,所有在 Kubernetes 集群中的组件交互都是通过 RESTful API 的形式完成的,包括第一步的控制器监听操作,以及第二步中 kubectl 发送的指令。虽说我们执行的是 _kubectl create -f ns-my-workspace.yaml _指令,但其实 kubectl 会向「API服务器」发送一个 POST 请求:
如上图所示,所有在 Kubernetes 集群中的组件交互都是通过 RESTful API 的形式完成的,包括第一步的控制器监听操作,以及第二步中 kubectl 发送的指令。虽说我们执行的是 _kubectl create -f ns-my-workspace.yaml _指令,但其实 kubectl 会向「API服务器」发送一个 POST 请求:
curl --request POST \
--url http://${k8s.host}:${k8s.port}/api/v1/namespaces \
--header 'content-type: application/json' \
--data '{
"apiVersion":"v1",
"kind":"Namespace",
"metadata":{
"name":"my-workspace"
}
}'
如上面的 cURL 指令,Kubernetes API 服务器接受的其实是 JSON 数据类型,而并非是 YAML。
然后所有这些创建的 resources 都会持久化到 etcd 组件中,「API服务器」也是 Kubernetes 集群中与「etcd」交互的唯一一个组件。
之后被创建的 my-workspace resource 就会被发送给监听了 namespaces resource 变更的 「Namespace控制器」中,最后就由「Namespace控制器」执行创建 my-workspace 命名空间的具体操作。那么同理,当创建 ReplicaSet resource 时就会由「ReplicaSet控制器」做具体执行,当创建 Pod 时,则会由「Pod控制器」具体执行,其他类型的 resource 与之类似,这些控制器共同组成了上图中的「Kubernetes API 控制器集合」。
说到这里,我们不难发现,实现 Kubernetes 中某一种领域类型——如上面提到的 Namespace、ReplicaSet、Pod,也即 Kubernetes 中的 Kind——的操作逻辑,需要具备两个因素:
- 对该领域类型的模型抽象,如上面的 ns-my-workspace.yaml 文件描述的 YAML 数据结构,这个抽象决定了 Kubernetes client 发送到 Kubernetes API server 的 RESTful API 请求,也描述了这个领域类型本身。
- 实际去处理这个领域类型抽象的控制器,如上面的「Namespace控制器」、「ReplicaSet控制器」、「Pod控制器」,这些控制器实现了这个抽象描述的具体业务逻辑,并通过 RESTful API 提供这些服务。
而当 Kubernetes 开发者需要扩展 Kubernetes 能力时,也可以遵循这种模式,即提供一份对想要扩展的能力的抽象,和实现了这个抽象具体逻辑的控制器。前者称作 CRD(Custom Resource Definition),后者称作 Controller。
Operator pattern 就是通过这种方式实现 Kubernetes 扩展性的一种模式,Operator 模式认为可以将一个领域问题的解决方案想像成是一个「操作者」,这个操作者在用户和集群之间,通过一份份「订单」,去操作集群的API,来达到完成这个领域各种需求的目的。这里的订单就是 CR(Custom Resource,即 CRD 的一个实例),而操作者就是控制器,是具体逻辑的实现者。之所以强调是 operator,而不是计算机领域里传统的 server 角色,则是因为 operator 本质上不创造和提供新的服务,他只是已有 Kubernetes API service 的组合。
而本文实践的「运维系统」,就是一个为了解决运维领域问题,而实现出来的 operator。
2. Operator Pattern 实战
在本节我们会通过使用 kubebuilder 工具,构建一个 Kubernetes Operator,在本节之后,我们会在自己的 Kubernetes 集群中获得一个 CRD 和其对应的 Kubernetes API 控制器,用于简单的部署一个微服务。即当我们 create 如下 YAML 时:
apiVersion: devops.my.domain/v1
kind: DemoMicroService
metadata:
name: demomicroservice-sample
spec:
image: stefanprodan/podinfo:0.0.1
可得到一个 Kubernetes 部署实例:
本节所有示例代码均提供在:https://github.com/l4wei/kubebuilder-example
2.1 Kubebuilder 实现
Kubebuilder(https://github.com/kubernetes-sigs/kubebuilder)是一个用 Go 语言构建 Kubernetes APIs 控制器和 CRD 的脚手架工具,通过使用 kubebuilder,用户可以遵循一套简单的编程框架,使用 Go 语言方便的实现一个 operator。
2.1.1 安装
在安装 kubebuilder 之前,需要先安装 Go 语言和 kustomize,并确保可以正常使用。
kustomize 是一个可定制化生成 Kubernetes YAML Configuration 文件的工具,你可以通过遵循一套 kustomize 的配置,批量的生成你需要的 Kubernetes YAML 配置。kubebuilder 使用了 kustomize 去生成控制器所需的一些 YAML 配置。mac 用户可使用 brew 方便地安装 kustomize。
然后使用使用下面的脚本安装 kubebuilder:
os=$(go env GOOS)
arch=$(go env GOARCH)
# download kubebuilder and extract it to tmp
curl -L https://go.kubebuilder.io/dl/2.2.0/${os}/${arch} | tar -xz -C /tmp/
# move to a long-term location and put it on your path
# (you'll need to set the KUBEBUILDER_ASSETS env var if you put it somewhere else)
sudo mv /tmp/kubebuilder_2.2.0_${os}_${arch} /usr/local/kubebuilder
export PATH=$PATH:/usr/local/kubebuilder/bin
使用 kubebuilder -h 若能看到帮助文档,则表示 kubebuilder 安装成功。
2.1.2 创建工程
使用下面的脚本创建一个 kubebuilder 工程:
mkdir example
cd example
go mod init my.domain/example
kubebuilder init --domain my.domain
上述命令的 my.domain 一般是你所在机构的域名,_example_ 一般是你这个 Go 语言项目的项目名。根据这样的设定,如果这个 Go 项目作为一个模块要被其他 Go 项目依赖,那么一般命名为 my.domain/example_。
如果你的 example 目录建立在 ${GOPATH} 目录之下,那么就不需要 _go mod init my.domain/example 这条命令,Go 语言也能找到该 example 目录下的 go pkg。
然后确保以下两条命令在你的开发机器上被执行过:
export GO111MODULE=on
sudo chmod -R 777 ${GOPATH}/go/pkg
以上两条命令的执行可以解决在开发时可能出现的cannot find package ... (from $GOROOT)这种问题。
在创建完工程之后,你的 example 目录结构会大致如下:
.
├── Dockerfile
├── Makefile
├── PROJECT
├── bin
│ └── manager
├── config
│ ├── certmanager
│ │ ├── certificate.yaml
│ │ ├── kustomization.yaml
│ │ └── kustomizeconfig.yaml
│ ├── default
│ │ ├── kustomization.yaml
│ │ ├── manager_auth_proxy_patch.yaml
│ │ ├── manager_webhook_patch.yaml
│ │ └── webhookcainjection_patch.yaml
│ ├── manager
│ │ ├── kustomization.yaml
│ │ └── manager.yaml
│ ├── prometheus
│ │ ├── kustomization.yaml
│ │ └── monitor.yaml
│ ├── rbac
│ │ ├── auth_proxy_role.yaml
│ │ ├── auth_proxy_role_binding.yaml
│ │ ├── auth_proxy_service.yaml
│ │ ├── kustomization.yaml
│ │ ├── leader_election_role.yaml
│ │ ├── leader_election_role_binding.yaml
│ │ └── role_binding.yaml
│ └── webhook
│ ├── kustomization.yaml
│ ├── kustomizeconfig.yaml
│ └── service.yaml
├── go.mod
├── go.sum
├── hack
│ └── boilerplate.go.txt
└── main.go
上面目录中的 bin 目录下的 manager 即工程编译出的二进制可执行文件,也就是这个控制器的可执行文件。
config 目录下都是 kustomize 的配置,例如 config/manager 目录下面的文件即生成控制器部署 YAML 配置文件的 kustomize 配置,如果你执行下面的指令:
kustomize build config/manager
就能看到 kustomize 生成的 YAML 配置:
apiVersion: v1
kind: Namespace
metadata:
labels:
control-plane: controller-manager
name: system
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
control-plane: controller-manager
name: controller-manager
namespace: system
spec:
replicas: 1
selector:
matchLabels:
control-plane: controller-manager
template:
metadata:
labels:
control-plane: controller-manager
spec:
containers:
- args:
- --enable-leader-election
command:
- /manager
image: controller:latest
name: manager
resources:
limits:
cpu: 100m
memory: 30Mi
requests:
cpu: 100m
memory: 20Mi
terminationGracePeriodSeconds: 10
上面就是将 bin/manager 部署到 Kubernetes 集群的 YAML configurations。
2.1.3 创建API
上面创建的工程仅仅只是一个空壳,还没有提供任何的 Kubernetes API,也不能处理任何的 CR。使用下面的脚本创建一个 Kubernetes API:
kubebuilder create api --group devops --version v1 --kind DemoMicroService
上述命令的 group 将与之前创建工程时输入的 domain 共同组成你创建的 Kubernetes API YAML resource 里 apiVersion 字段的前半部分,上面的 version 即后半部分,所以你自定义的 resource YAML 里的 apiVersion 就应该写作:devops.my.domain/v1。上面的 kind 就是你自定义 resource 里的 kind 字段。通过该条指令创建的 resource 看起来正如 kubebuilder 创建的 config/samples/devops_v1_demomicroservice.yaml 文件一样:
apiVersion: devops.my.domain/v1
kind: DemoMicroService
metadata:
name: demomicroservice-sample
spec:
# Add fields here foo: bar
输入该命令会提示你是否创建 Resource(即 CRD),是否创建 Controller(即控制器),全部输入「y」同意即可。
在执行完该命令之后,你的工程结构将变成这样:
.
├── Dockerfile
├── Makefile
├── PROJECT
├── api
│ └── v1
│ ├── demomicroservice_types.go
│ ├── groupversion_info.go
│ └── zz_generated.deepcopy.go
├── bin
│ └── manager
├── config
│ ├── certmanager
│ │ ├── certificate.yaml
│ │ ├── kustomization.yaml
│ │ └── kustomizeconfig.yaml
│ ├── crd
│ │ ├── kustomization.yaml
│ │ ├── kustomizeconfig.yaml
│ │ └── patches
│ │ ├── cainjection_in_demomicroservices.yaml
│ │ └── webhook_in_demomicroservices.yaml
│ ├── default
│ │ ├── kustomization.yaml
│ │ ├── manager_auth_proxy_patch.yaml
│ │ ├── manager_webhook_patch.yaml
│ │ └── webhookcainjection_patch.yaml
│ ├── manager
│ │ ├── kustomization.yaml
│ │ └── manager.yaml
│ ├── prometheus
│ │ ├── kustomization.yaml
│ │ └── monitor.yaml
│ ├── rbac
│ │ ├── auth_proxy_role.yaml
│ │ ├── auth_proxy_role_binding.yaml
│ │ ├── auth_proxy_service.yaml
│ │ ├── demomicroservice_editor_role.yaml
│ │ ├── demomicroservice_viewer_role.yaml
│ │ ├── kustomization.yaml
│ │ ├── leader_election_role.yaml
│ │ ├── leader_election_role_binding.yaml
│ │ └── role_binding.yaml
│ ├── samples
│ │ └── devops_v1_demomicroservice.yaml
│ └── webhook
│ ├── kustomization.yaml
│ ├── kustomizeconfig.yaml
│ └── service.yaml
├── controllers
│ ├── demomicroservice_controller.go
│ └── suite_test.go
├── go.mod
├── go.sum
├── hack
│ └── boilerplate.go.txt
└── main.go
比起创建 API 之前,增加了:
- api 目录——即定义了你创建的 Kubernetes API 的数据结构代码。
- controllers 目录——即控制器的实现代码。
- config/crd 目录——该目录里的 kustomize 配置可生成你要定义的 CRD 的 YAML 配置。
输入以下命令:
make manifests
即可在 config/crd/bases/devops.my.domain_demomicroservices.yaml 文件里看到你创建该 Kubernetes API 时创建的 CRD:
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
annotations:
controller-gen.kubebuilder.io/version: v0.2.4
creationTimestamp: null
name: demomicroservices.devops.my.domain
spec:
group: devops.my.domain
names:
kind: DemoMicroService
listKind: DemoMicroServiceList
plural: demomicroservices
singular: demomicroservice
scope: Namespaced
validation:
openAPIV3Schema:
description: DemoMicroService is the Schema for the demomicroservices API
properties:
apiVersion:
description: 'APIVersion defines the versioned schema of this representation
of an object. Servers should convert recognized schemas to the latest
internal value, and may reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources'
type: string
kind:
description: 'Kind is a string value representing the REST resource this
object represents. Servers may infer this from the endpoint the client
submits requests to. Cannot be updated. In CamelCase. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds'
type: string
metadata:
type: object
spec:
description: DemoMicroServiceSpec defines the desired state of DemoMicroService
properties:
foo:
description: Foo is an example field of DemoMicroService. Edit DemoMicroService_types.go
to remove/update
type: string
type: object
status:
description: DemoMicroServiceStatus defines the observed state of DemoMicroService
type: object
type: object
version: v1
versions:
- name: v1
served: true
storage: true
status:
acceptedNames:
kind: ""
plural: ""
conditions: []
storedVersions: []
2.1.4 API属性定义
Kubernetes API 创建好了,现在我们需要定义该 API 的属性,这些属性才真正描述了创建出的 CRD 的抽象特征。
在我们这个 DemoMicroService Kind 例子中,我们只简单的抽象出一个微服务的部署 CRD,所以我们这个 CRD 只有一个属性,即该服务的容器镜像地址。
为此,我们只需要修改 api/v1/demomicroservice_types.go 文件: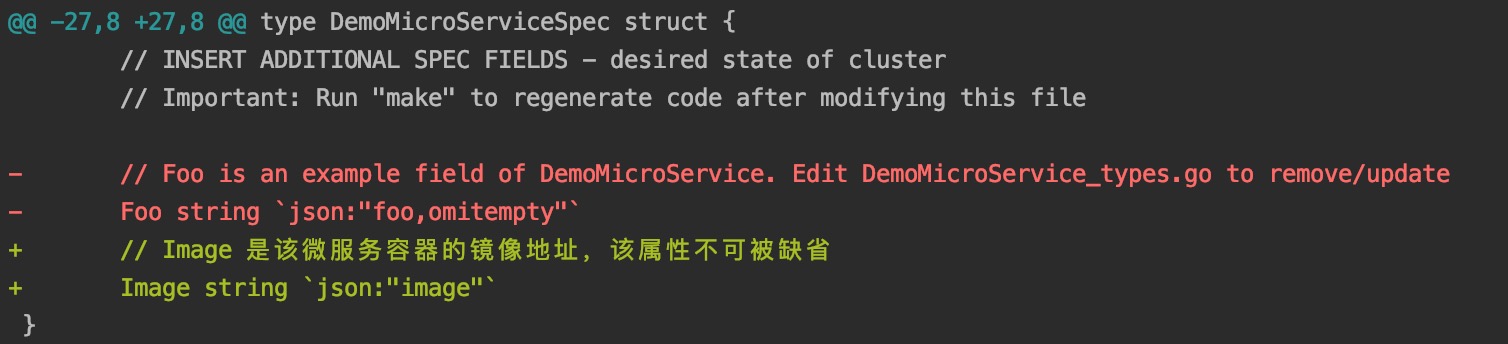
上面的 git diff 显示我们将原来示例的 Foo 属性改成了我们需要的 Image 属性。对 API 属性的定义和对 CRD 的定义基本上只需要修改该文件即可。
再次执行:
make manifests
即可看到生成的 CRD resource 发生了变更,这里不再赘述。
现在我们也修改一下 config/samples/devops_v1_demomicroservice.yaml 文件,后面需要使用该文件测试我们实现的控制器:
apiVersion: devops.my.domain/v1
kind: DemoMicroService
metadata:
name: demomicroservice-sample
spec:
image: stefanprodan/podinfo:0.0.1
2.1.5 控制器逻辑实现
CRD 定义好了,现在开始实现控制器。
我们在这次示例中要实现的控制器逻辑非常简单,基本可以描述成:
- 当我们执行 kubectl create -f config/samples/devops_v1_demomicroservice.yaml 时,控制器会在集群中创建一个 Kubernetes Deployment resource,用于实现该 DemoMicroService 的部署。
- 当我们执行 kubectl delete -f config/samples/devops_v1_demomicroservice.yaml 时,控制器会将在集群中创建的 Deployment resource 删掉,表示该 DemoMicroService 的下线。
2.1.5.1 部署的实现
写代码之前,我们需要先了解 kubebuilder 程序的开发方式。
因为我们要实现的是 DemoMicroService 的控制器,所以我们需要先将注意力集中在 _controllers/demomicroservice_controller.go_ 文件,如果不是复杂的功能,通常我们只需改该文件即可。而在文件中,我们最需要关心的就是 Reconcile 方法:
func (r *DemoMicroServiceReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
_ = context.Background()
_ = r.Log.WithValues("demomicroservice", req.NamespacedName)
// your logic here
return ctrl.Result{}, nil
}
简单来说,每当 kubernetes 集群监控到 DemoMicroService CR 的变化时,都会调用到这个 Reconcile 方法,并将变更的 DemoMicroService resource name 及其所在的 namespace 作为 Reconcile 方法的参数,用于定位到变更的 resource。即上面的 req 参数,该参数的结构为:
type Request struct {
// NamespacedName is the name and namespace of the object to reconcile.
types.NamespacedName
}
type NamespacedName struct {
Namespace string
Name string
}
熟悉前端开发的朋友可能会联想到 React 的开发方式,两者确实很像,都是监听对象的变化,再根据监听对象的变化来执行一些逻辑。不过 kubebuilder 做的更加极端,他没有抽象出生命周期的概念,只提供一个 Reconcile 方法,开发者需要自己在这个方法中判断出 CRD 的生命周期,并在不同的生命周期中执行不同的逻辑。
以下的代码实现了部署的功能:
func (r *DemoMicroServiceReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
ctx := context.Background()
log := r.Log.WithValues("demomicroservice", req.NamespacedName)
dms := &devopsv1.DemoMicroService{}
if err := r.Get(ctx, req.NamespacedName, dms); err != nil {
if err := client.IgnoreNotFound(err); err == nil {
log.Info("此时没有找到对应的 DemoMicroService resource, 即此处进入了 resource 被删除成功后的生命周期")
return ctrl.Result{}, nil
} else {
log.Error(err, "不是未找到的错误,那么就是意料之外的错误,所以这里直接返回错误")
return ctrl.Result{}, err
}
}
log.Info("走到这里意味着 DemoMicroService resource 被找到,即该 resource 被成功创建,进入到了可根据该 resource 来执行逻辑的主流程")
podLabels := map[string]string{
"app": req.Name,
}
deployment := appv1.Deployment{
TypeMeta: metav1.TypeMeta{
Kind: "Deployment",
APIVersion: "apps/v1",
},
ObjectMeta: metav1.ObjectMeta{
Name: req.Name,
Namespace: req.Namespace,
},
Spec: appv1.DeploymentSpec{
Selector: &metav1.LabelSelector{
MatchLabels: podLabels,
},
Template: corev1.PodTemplateSpec{
ObjectMeta: metav1.ObjectMeta{
Labels: podLabels,
},
Spec: corev1.PodSpec{
Containers: []corev1.Container{
{
Name: req.Name,
Image: dms.Spec.Image,
ImagePullPolicy: "Always",
Ports: []corev1.ContainerPort{
{
ContainerPort: 9898,
},
},
},
},
},
},
},
}
if err := r.Create(ctx, &deployment); err != nil {
log.Error(err, "创建 Deployment resource 出错")
return ctrl.Result{}, err
}
return ctrl.Result{}, nil
}
上述代码展现了生命周期中的两个阶段:即第8行中代表 DemoMicroService resource 被成功删除之后的阶段,此时我们什么都没有做。以及在第16行,进入到创建/更新完 DemoMicroService resource 之后的阶段,此时我们构建了一个 Deployment resource,并将其创建到了 Kubernetes 集群中。
这段代码有个问题,即无法实现 DemoMicroService resource 的更新,如果同一个 DemoMicroService resource 的 spec.image 被改变了,那么在上述代码中会再次 create 相同的 Deployment resource,这会导致一个 "already exists" 的报错。这里为了方便说明开发逻辑,没有处理这个问题,请读者注意。
2.1.5.1 下线的实现
其实在上一节我们说明部署逻辑的时候,就能实现下线的逻辑:我们只需在「删除成功后」的生命周期阶段将创建的 Deployment 删掉即可。但是这样做有一个问题,我们是在 DemoMicroService resource 删除成功之后再删的 Deployment,如果删除 Deployment 的逻辑出错了,没有将 Deployment 删除成功,那么就会出现 Deployment 还在,DemoMicroService 却不再的情况,如果我们需要用 DemoMicroService 管理 Deployment,那么这就不是我们想要的结果。
所以我们最好在 DemoMicroService 真正消失之前(即「删除 DemoMicroService」到「DemoMicroService 完全消失」这段时间)去删除 Deployment,那么要怎么做呢?请看下面的代码示例:
const (
demoMicroServiceFinalizer string = "demomicroservice.finalizers.devops.my.domain"
)
func (r *DemoMicroServiceReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
ctx := context.Background()
log := r.Log.WithValues("demomicroservice", req.NamespacedName)
dms := &devopsv1.DemoMicroService{}
if err := r.Get(ctx, req.NamespacedName, dms); err != nil {
if err := client.IgnoreNotFound(err); err == nil {
log.Info("此时没有找到对应的 DemoMicroService resource, 即此处进入了 resource 被删除成功后的生命周期")
return ctrl.Result{}, nil
} else {
log.Error(err, "不是未找到的错误,那么就是意料之外的错误,所以这里直接返回错误")
return ctrl.Result{}, err
}
}
if dms.ObjectMeta.DeletionTimestamp.IsZero() {
log.Info("进入到 apply 这个 DemoMicroService CR 的逻辑")
log.Info("此时必须确保 resource 的 finalizers 里有控制器指定的 finalizer")
if !util.ContainsString(dms.ObjectMeta.Finalizers, demoMicroServiceFinalizer) {
dms.ObjectMeta.Finalizers = append(dms.ObjectMeta.Finalizers, demoMicroServiceFinalizer)
if err := r.Update(ctx, dms); err != nil {
return ctrl.Result{}, err
}
}
if _, err := r.applyDeployment(ctx, req, dms); err != nil {
return ctrl.Result{}, nil
}
} else {
log.Info("进入到删除这个 DemoMicroService CR 的逻辑")
if util.ContainsString(dms.ObjectMeta.Finalizers, demoMicroServiceFinalizer) {
log.Info("如果 finalizers 被清空,则该 DemoMicroService CR 就已经不存在了,所以必须在次之前删除 Deployment")
if err := r.cleanDeployment(ctx, req); err != nil {
return ctrl.Result{}, nil
}
}
log.Info("清空 finalizers,在此之后该 DemoMicroService CR 才会真正消失")
dms.ObjectMeta.Finalizers = util.RemoveString(dms.ObjectMeta.Finalizers, demoMicroServiceFinalizer)
if err := r.Update(ctx, dms); err != nil {
return ctrl.Result{}, err
}
}
return ctrl.Result{}, nil
}
为了方便展示主逻辑,我将创建 Deployment 和删除 Deployment 的代码封装到 applyDeployment 和 cleanDeployment 两个方法中了。
如上面代码所示,想要判断「删除 DemoMicroService」到「DemoMicroService 完全消失」这段生命周期的阶段,关键点在于判断 DemoMicroService.ObjectMeta.DeletionTimestam 和 DemoMicroService.ObjectMeta.Finalizers 这两个元信息。前者表示「删除 DemoMicroService」这一行为的具体发生时间,如果不为0则表示「删除 DemoMicroService」指令已经下达;而后者表示在真正删除 DemoMicroService 之前,即「DemoMicroService 完全消失」之前,还有哪些逻辑没有被执行,如果 Finalizers 不为空,那么该 DemoMicroService 则不会真正消失。
任何 resource 的 ObjectMeta.Finalizers 都是一个字符串的列表,每一个字符串都表示一段 pre-delete 逻辑尚未被执行。如上面的「demomicroservice.finalizers.devops.my.domain」所示,表示着 DemoMicroService 控制器对 DemoMicroService resource 的 pre-delete 逻辑,该 Finalizer 会在 DemoMicroService 被创建之后,迅速被 DemoMicroService 控制器给种上,并在下达「删除 DemoMicroService」指令后,且 pre-delete 逻辑(在这里即删除 Deployment)被正确执行完后,再由 DemoMicroService 控制器将该 Finalizer 抹除。至此 DemoMicroService 上的 Finalizers 为空,此时 Kubernetes 才会让该 DemoMicroService 完全消失。Kubernetes 正是通过这种机制创造出了 resource 的「对该 resource 下达删除指令」到「该 resource 完全消失」这段生命周期的阶段。
如果因为各种原因导致 Finalizers 不可能为空,那么会发生什么?答案是会导致这个 resource 永远无法被删掉,如果你使用 kubectl delete 去删,那么这个指令将永远不会返回。这也是使用 Finalizers 机制时会经常碰到的问题,如果你发现有一个 resource 始终无法被删掉,那么请检查一下你是否种上了某个不会被删掉的 Finalizer。
2.1.6 调试与发布
2.1.5.1 调试
在我们开始运行&调试我们编写的控制器之前,我们最好为我们的 DemoMicroService CRD 设置一个缩写名称,这是为了我们后面的操作不用输入"demomicroservice"这么长的名称。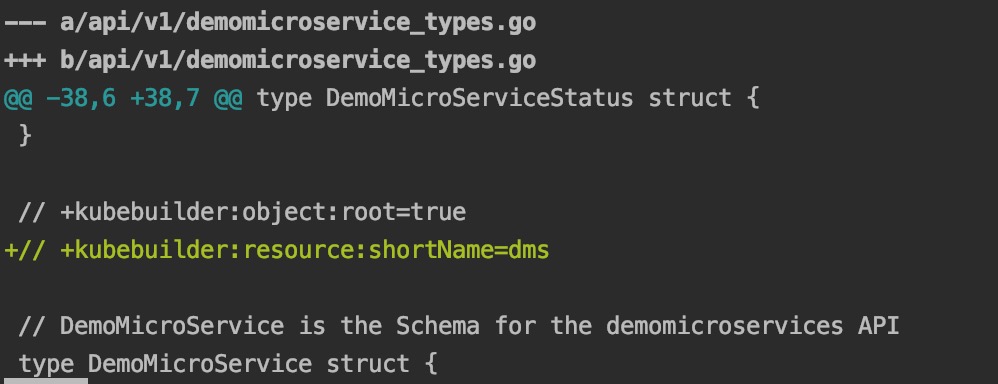
如上图在 _api/v1/demomicroservice_types.go_ 文件里加上一行注释,我们将"demomicroservice"的缩写设置成"dms"。
顺带一提,kubebuilder 中,所有带"+kubebuilder"的注释都是有用的,不要轻易删掉,他们是对该 kubebuilder 工程的一些配置。
改完之后再执行"make manifests"指令,会发现 kubebuiler 生成的 CRD 文件被修改,添加了缩写的配置: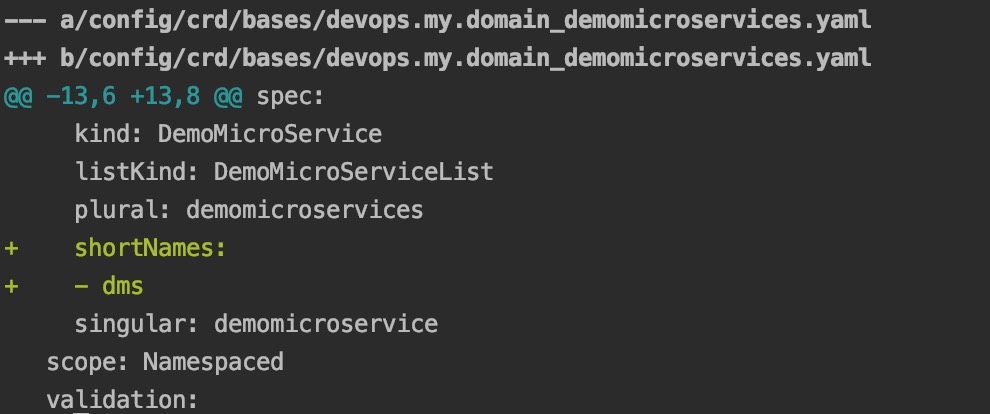
再设置缩写之后,我们执行以下命令,将 CRD 安装到你开发机器当前连接的 Kubernetes 集群:
make install
之后就能看到你的集群里被安装了自己定义的 CRD:
现在我们可以启动我们的控制器程序了,由于笔者使用的是 GoLand IDE,所以我直接点击启动了 main.go 里的 main 函数:
读者可根据自己的开发工具,选择使用自己的启动方式,总之就是运行该 Go 程序即可。也可以直接使用下面的命令启动:
make run
在本地启动控制器之后,你的开发机器就是该 DemoMicroService 的控制器了,你连接的 Kubernetes 集群会将有关 DemoMicroService resource 的变更发送到你的开发机器上执行,所以打断点也会断住。
接下来我们验收一下我们之前写的代码是否正常工作,执行命令:
kubectl apply -f ./config/samples/devops_v1_demomicroservice.yaml
我们会看到 Kubernetes 集群中出现了该 resource:
以上的"dms"即我们刚才设置的"demomicroservice"的缩写。
以及伴随着 DemoMicroService 创建的 Deployment 及其创建的 Pod:
当我们执行删除 dms 的命令时,这些 deployment 和 pod 也会被删掉。
2.1.5.1 发布
使用如下命令将控制器发布到你开发机器当前连接的 Kubernetes 集群:
make deploy
之后 kubebuilder 会在集群中创建一个专门用于放该控制器的 namespace,在我们这个例子里,该 namespace 为 example-system,之后可以通过如下命令看到自己的控制器已经被发布到你当前连接的集群:
kubectl get po -n example-system
如果该 pod 发布失败,那么多半是国内连接不上 gcr.io 的镜像仓库导致的,在工程内搜索"gcr.io"的镜像仓库,将其替换成你方便访问的镜像仓库即可。
2.2 总结
我们在本节大致了解了 kubebuilder 脚手架的使用方法,和 kubebuilder 程序的开发方法。并实践了一个实现了微服务的部署和下线的控制器。
或许读者会问,为什么不直接创建一个 Deployment,而要用这么麻烦的方式来实现。那是因为自定义的 CRD 能更好的抽象开发者的业务场景,比如在我们的这个例子中,我们的微服务只关心镜像地址,其他的 Deployment 属性全部可以默认,那么我们的 DemoMicroService 看上去就比 Deployment 清爽很多。
除此之外,这样做还有如下优点:
Kubernetes 的 resource 保证了执行结果的一致性:Kubernetes 对于执行 resource 天然的符合幂等性,并且其内提供的 resourceVersion 机制也解决了并发执行时带来的结果不一致的问题,这些问题如果开发者自己去解,往往会费时费力,而且吃力不讨好。
kubebuilder 的开发模型帮助开发者节省了大量工作量,这些工作量包括:监听 resource 变化,出错 resource 的重试,以及必要的 YAML configurations 生成。
- 这里值得一提的是 kubebuilder 的重试机制,如果你自定的 resource 执行失败,那么 kubebuilder 会帮助你重试直到该 resource 被成功执行,这省去了你自己实现重试逻辑的工作量。
调用链路安全可控,通过将你的业务逻辑沉淀成 CRD 和控制器,可以完全享受 Kubernetes 的 rbac 权限管控系统,能更安全,方便和精细的管控你开发的控制器接口。
由于我们的示例过于简单,所以这些优势听起来可能比较苍白,在下一节我们到更复杂的运维场景里之后,我们能对以上描述的这些优势有更深的体会。
3. 运维系统实现
如果你只对 operator pattern 及其实践感兴趣,并不关心运维系统如何实现,那么可以不读本节。
下图展示了在我们开发的微服务平台中,微服务运维控制器所做的事情,读者可以看到实现的这样一个 operator 在整个微服务平台中的位置:
上图中的 dmsp 表示我们的微服务平台,而 dmsp-ops-operator 即该运维系统的控制器。可以看到因为 dmsp-ops-operator 的存在,用户操作管控台要下达的指令就很简单,实际的运维操作都由 dmsp-ops-operator 执行即可。并且 dmsp-ops-operator 也作为 Kubernetes 集群里的能力沉淀到了技术栈的最下层,与上层的业务逻辑完全清晰的分离了开来。
3.1 微服务的完整抽象
在第2节,我们实现了一个 demo 微服务,事实上那个 demo 微服务只关心镜像地址,这明显是不够的,所以我们实现了 MicroServiceDeploy CRD 及其控制器,能抽象和实现更多的运维功能,一个 MicroServiceDeploy CR 看起来如下所示:
apiVersion: custom.ops/v1
kind: MicroServiceDeploy
metadata:
name: ms-sample-v1s0
spec:
msName: "ms-sample" # 微服务名称
fullName: "ms-sample-v1s0" # 微服务实例名称
version: "1.0" # 微服务实例版本
path: "v1" # 微服务实例的大版本,该字符串将出现在微服务实例的域名中
image: "just a image url" # 微服务实例的镜像地址
replicas: 3 # 微服务实例的 replica 数量
autoscaling: true # 该微服务是否开启自动扩缩容功能
needAuth: true # 访问该微服务实例时,是否需要租户 base 认证
config: "password=88888888" # 该微服务实例的运行时配置项
creationTimestamp: "1535546718115" # 该微服务实例的创建时间戳
resourceRequirements: # 该微服务实例要求的机器资源
limits: # 该微服务实例会使用到的最大资源配置
cpu: "2"
memory: 4Gi
requests: # 该微服务实例至少要用到的资源配置
cpu: "2"
memory: 4Gi
idle: false # 是否进入空载状态
而以上一个 resource 实际上创建了很多其他的 Kubernetes resource,这些 Kubernetes resource 才真正构成了该微服务实际的能力。创建这些 Kubernetes resource 的方式基本上就是第2节讲解的方式。
下面我将分开介绍这些 Kubernetes resource,并分别说明这些 Kubernetes resource 的意义和作用。
3.2 Service&ServiceAccount&Deployment
首先是对于一个微服务而言必备的 Service, ServiceAccount 和 Deployment。这三种 resource 大家应该已经很熟悉了,这里就不过多说明,直接贴出由 MicroServiceDeploy 控制器创建出的 YAML 配置。
3.2.1 Service&ServiceAccount
apiVersion: v1
kind: Service
metadata:
labels:
app: ms-sample
my-domain-ops-controller-make: "true"
name: ms-sample
spec:
ports:
- name: http
port: 9898
protocol: TCP
targetPort: 9898
selector:
app: ms-sample
status:
loadBalancer: {}
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
my-domain-ops-controller-make: "true"
name: ms-sample
上面的 my-domain-ops-controller-make 是自定义控制器自己打上的 label,用于区分该 resource 是我们的自定义控制器创建的。
3.2.2 Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
app.ops.my.domain/last-rollout-at: "1234"
labels:
app: ms-sample
my-domain-ops-controller-make: "true"
name: ms-sample-v1s0
spec:
replicas: 1
selector:
matchLabels:
app: ms-sample
type: RollingUpdate
template:
metadata:
annotations:
app.ops.my.domain/create-at: "1234"
prometheus.io/scrape: "true"
labels:
app: ms-sample
spec:
containers:
- env:
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: SERVICE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.labels['app']
image: "just a image url"
imagePullPolicy: Always
name: ms-sample
ports:
- containerPort: 9898
protocol: TCP
resources:
limits:
cpu: 100m
memory: 400Mi
requests:
cpu: 100m
memory: 400Mi
volumeMounts:
- mountPath: /home/admin/logs
name: log
- mountPath: /home/admin/conf
name: config
initContainers:
- command:
- sh
- -c
- chmod -R 777 /home/admin/logs || exit 0
image: busybox
imagePullPolicy: Always
name: log-volume-mount-hack
volumeMounts:
- mountPath: /home/admin/logs
name: log
volumes:
- hostPath:
path: /data0/logs/ms-sample/1.0
type: DirectoryOrCreate
name: log
- configMap:
defaultMode: 420
name: ms-sample-v1s0
name: config
上面的 Deployment 有三点需要说明:
- Pod 里 app.ops.my.domain/create-at 的 annotation 是控制器给 Pod 打上的注释,用于强制让该 Deployment 下的 Pods重启,这样即使 Deployment apply 时没有其他变化,这些 Pods 也会被重启,这在需要 Pods 被强制重启时很有用。
- 上面 name 为 log 的 volume 表示日志的 volume 挂载,代表容器内的 /home/admin/logs 目录里收集的日志会同步到宿主机的 /data0/logs/ms-sample/1.0 目录下。要让这个机制成立,需要你容器里的服务确保将日志打到 /home/admin/logs 目录下。
- 上面 name 为 config 的 volume 挂载,表示将 name 为 ms-sample-v1s0 的 ConfigMap 配置挂载到容器里的 /home/admin/conf 目录下,这样你在你的容器里通过读取 /home/admin/conf 目录下的配置文件,就能在容器中读取到运行时配置。详情将在 3.3 节里说明。
3.3 代表运行时配置项的ConfigMap
在 3.2.2 节提到的 ms-sample-v1s0 ConfigMap 如下所示:
apiVersion: v1
data:
ms.properties: name=foo
kind: ConfigMap
metadata:
labels:
app: ms-sample
my-domain-ops-controller-make: "true"
name: ms-sample-v1s0
上述 ConfigMap 当 mount 到容器内的 /home/admin/conf 下时,就会在 /home/admin/conf 下创建一个 ms.properties 文件,该文件的内容就是"name=foo"。此时容器内部便可以通过读取该文件来获取运行时配置。而且该配置是动态实时更新的,即 ConfigMap 变化了,容器里的文件内容也会变化,这样就可以做到即使容器不重启,最新的配置也会生效。
3.3 资源管理
在 Kubernetes 中,资源这一名词一般指代系统默认的机器资源,即:cpu 与 memory。
这里的资源管理是指对微服务部署的 namespace 进行资源总量的管控,以及对每个微服务部署的容器做资源限制。用于实现这一目的的 YAML 为:
apiVersion: v1
kind: ResourceQuota
metadata:
labels:
my-domain-ops-controller-make: "true"
name: default-resource-quota
namespace: default
spec:
hard:
requests.cpu: "88"
limits.cpu: "352"
requests.memory: 112Gi
limits.memory: 448Gi
---
apiVersion: v1
kind: LimitRange
metadata:
labels:
my-domain-ops-controller-make: "true"
name: default-limit-range
namespace: default
spec:
limits:
- default:
cpu: 400m
memory: 2Gi
defaultRequest:
cpu: 100m
memory: 500Mi
max:
cpu: "2"
memory: 8Gi
type: Container
与其他的 Kubernetes resource 不同的是,上面两个 resource 并不是在部署 MicroServiceDeploy CR 时创建的,而是在控制器部署时创建的,作为针对集群内某一 namespace 的配置。所以你需要在控制器的 init 方法中去 create 上面两个 resource。
上面的 ResourceQuota 限制了 default namespace 所能占用的资源额度总量。
而 LimitRange 限制了 default namespace 中所有没有限制资源量的容器所能占用的资源额度。之所以要为每个让容器有缺省的资源额度,原因在于 Kubernetes 会对根据资源配置的情况对 Pod 做分级:如果一个 Pod 没有被配置资源量,则该 Pod 重要性最低;其次是分配了资源配置,但是 limits != requests 的 Pod;最后是分配了资源配置,而且 limits == requests 的 Pod,其重要性最高。Kubernetes 会在资源总量不足时,将重要性更低的 Pod 释放掉,用于调度更重要的 Pod。
以上描述的三个等级分别称作:BestEffort(优先级最低),Burstable,Guaranteed(优先级最高)。该等级称作 QoS(Quality of Service) 等级。你可以在 Kubernetes Pod resource 的 status.qosClass 字段里查看该 Pod 的 QoS 等级。
3.4 HPA自动扩缩容
用于实现自动扩缩容的 HPA(HorizontalPodAutoscaler) resource 也是在部署 MicroServiceDeploy CR 时创建的,他针对的是这个 MicroServiceDeploy CR 代表的微服务:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
labels:
app: ms-sample
my-domain-ops-controller-make: "true"
name: ms-sample-v1s0
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ms-sample-v1s0
targetCPUUtilizationPercentage: 81
上面的 HPA resource 表示将根据 cpu 使用率来对 ms-sample-v1s0 Deployment 下的 Pod 进行扩缩容,并且 Pod 数的区间在:[1, 10]。
关于自动扩缩容可以讲的比较多,我会单写一篇文章详细的来说明这一块内容。











