- 为何HotSpot虚拟机要使用解释器与编译器并存的架构?
- 为何HotSpot虚拟机要实现两个不同的即时编译器?
- 程序何时使用解释器执行?何时使用编译器执行?
- 哪些程序代码会被编译为本地代码?如何编译为本地代码?
- 如何从外部观察即时编译器的编译过程和编译结果?
解释器与编译器两者各有优势:
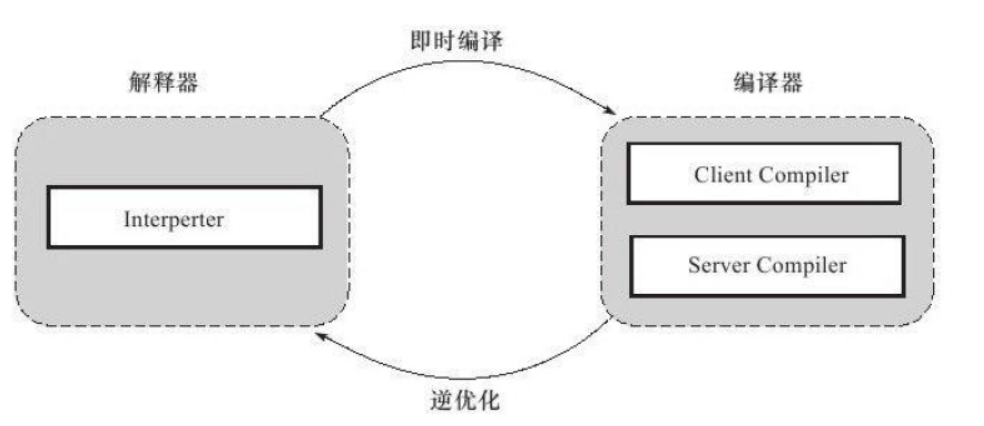
当_程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即执行。在程序运行后,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码之后,可以获取更高的执行效率。当程序运行环境中内存资源限制较大(如部分嵌入式系统中),可以使用解释执行节约内存,反之可以使用编译执行来提升效率。同时,解释器还可以作为编译器激进优化时的一个“逃生门”,让编译器根据概率选择一些大多数时候都能提升运行速度的优化手段,当激进优化的假设不成立,如加载了新类后类型继承结构出现变化、出现“罕见陷阱”(Uncommon Trap)时可以通过逆优化(Deoptimization)退回到解释状态继续执行(部分没有解释器的虚拟机中也会采用不进行激进优化的C1编译器[2]担任“逃生门”的角色),_
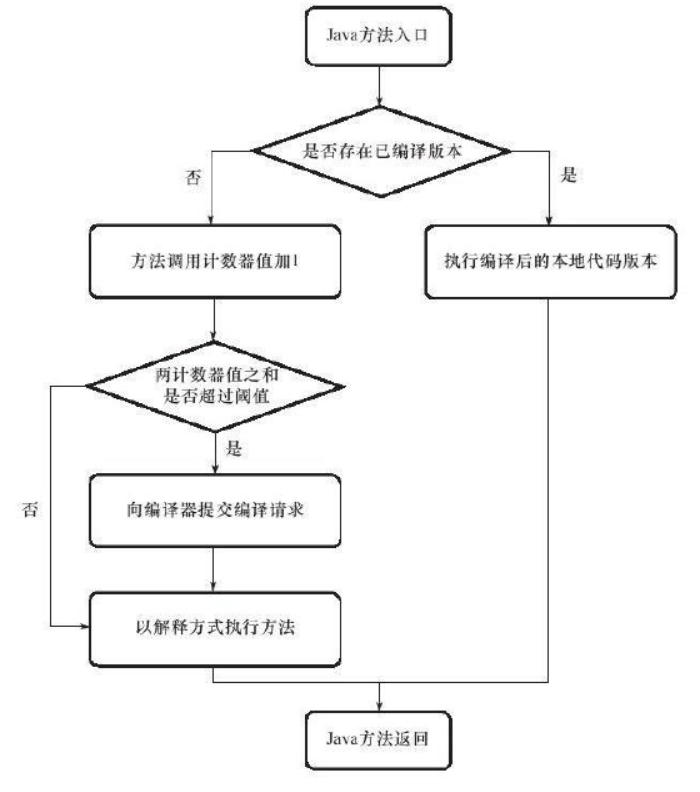
因此,在整个虚拟机执行架构中,解释器与编译器经常配合工作,如图11-1所示。
热点探测:
判断一段代码是不是热点代码,是不是需要触发即时编译,这样的行为称为热点探测,主要的热点探测有两种方法:
- 基于采样的热点探测,
- 基于计数器的热点探测(HotSpot使用此方式)
使用过程;
当一个方法被调用时,会先检查该方法是否存在被JIT编译过的版本,如果存在,则优先使用编译后的本地代码来执行。如果不存在已被编译过的版本,则将此方法的调用计数器值加1,然后判断方法调用计数器与回边计数器值之和是否超过方法调用计数器的阈值。如果已超过阈值,那么将会向即时编译器提交一个该方法的代码编译请求。