

先给结论吧:HBase利用compaction机制,通过大量的读延迟毛刺和一定的写阻塞,来换取整体上的读取延迟的平稳。
1.为什么要compaction
在上一篇 HBase读写 中我们提到了,HBase在读取过程中,会创建多个scanner去抓去数据。
其中,会创建多个storefilescanner去load HFile中的指定data block。所以,我们很容易就想到,如果说HFile太多的话,那么就会涉及到很多磁盘IO,这个就是常说的“读放大”现象。
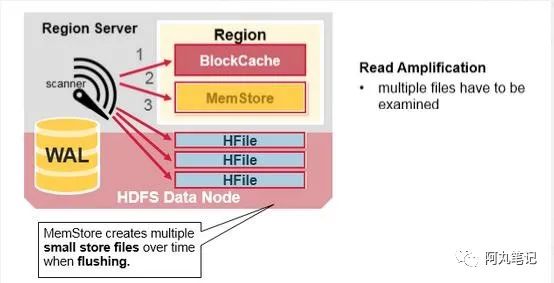
因此,就有了今天的主题,HBase的核心特性——compaction。
通过执行compaction,可以使得HFile的数量基本稳定,使得IO seek次数稳定,然后每次的查询rt才能稳定在一定范围内。
2.compaction的分类
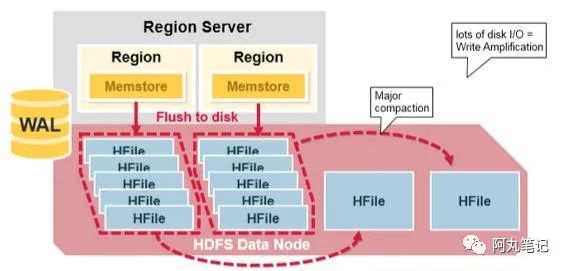
compaction分为两种,minor compaction和major compaction。
Minor compaction主要是将一些相邻的小文件合并为大文件,这个过程仅仅做文件的合并,并不会删除deleted type的数据和ttl过期的数据。

Major compaction是指将一个HStore下的所有文件合并为一个HFile,这个过程会消耗大量系统资源,一般线上会关闭自动定期major compaction的功能(将参数hbase.hregion.majorcompaction设为0即可关闭,但是flush的触发还是会进行),改为手动低峰执行。这个过程会删除三类数据:标记为删除的数据、TTL过期的数据、版本号不满足要求的数据。
具体什么时候触发哪种类型的compaction呢?
满足以下任意条件会触发major compaction,否则就是minor compaction:
用户强制执行major compaction
长时间没有compact,且候选文件小于阈值(hbase.hstore.compaction.max)
Store中含有reference文件(split产生的临时文件),需要通过 major compact进行数据迁移,删除临时文件
3.compaction的触发时机
compaction的触发时机一共有三种:
1)MemStore flush:
这个在一开始就提到了,相信也很容易理解。因为每次MemStore flush会产生新的HFile文件,而文件数量超过限制,自然就触发了compaction。这里需要注意的是,我们在 深入HBase架构 一文中已经提到,memstore是以region为单位进行flush的,也就是说,一个region内的任意一个HStore下面的memstore满了,这个region下的所有HStore的memstore都会触发flush。然后每个HStore都有可能触发compaction。
2)后台线程周期性检查
HBase有一个后台线程CompactionChecker,会定期巡检触发检查,是否进行compaction。
这里和flush触发的compaction有所不同,这里先检查文件树是否大于阈值,大于就触发compaction。如果没有大于阈值,还会检查下HFile里面的最早更新时间,是否早于某个阈值(hbase.hregion.majorcompaction),如果早于,就触发major compaction来达到清理无用数据的目的。
3)手动触发:
由于我们担心major compaction会影响业务,因此会选择业务低峰期进行手动触发。
还有一部分原因,是用户执行ddl后,希望理解生效,也会执行手动触发major compaction。
最后,可能是因为磁盘容量不够了,需要major compaction来手动清理无效数据,合并文件。
4.HFile合并过程
1)读取待合并的HFile的key value,写入临时文件中
2)将临时文件移动到对应的region的数据目录
3) 将compaction的输入文件路径和输出文件路径写入WAL日志,然后强行执行sync
4)将对应region数据目录下的输入文件全部删除
5.compaction的副作用分析
当然,compaction本身也要涉及到大量文件的读写,在表现上就是会有一定的读延迟毛刺。因此,我们可以认为,compaction过程是使用短时间的大量IO消耗来换取后续查询的低延迟。
另一方面,假设处于长时间的高写入量,HFile的数量一直增长,compaction的速度赶不上HFile增长的速度,那么,HBase会暂时阻塞写请求。当每次memstore进行flush的时候,如果一个HStore中的HFile的数量超过了hbase.hstore.blockingStoreFIles(默认为7),那么就会暂时阻塞flush的动作,阻塞时间为abase.hstore.blockingWaitTime。当阻塞时间过去后,观察HFile的数量下降到上述值,那么就会继续flush的操作。这样,就保证了HFile数量的稳定,但是对写入会有一定的速度影响。
原创:阿丸笔记(微信公众号:aone_note),欢迎 分享,转载请保留出处。
扫描下方二维码可以关注我哦~

觉得不错,就点个 再看 吧👇
本文分享自微信公众号 - 阿丸笔记(aone_note)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











