
「数仓宝贝库」,带你学数据!
导读:Pandas是Python数据分析的利器,也是各种数据建模的标准工具。本文带大家入门Pandas,将介绍Python语言、Python数据生态和Pandas的一些基本功能。

在Python语言应用生态中,数据科学领域近年来十分热门。作为数据科学中一个非常基础的库,Pandas受到了广泛关注。Pandas可以将现实中来源多样的数据进行灵活处理和分析。
0**1**
Pandas是什么
很多初学者可能有这样一个疑问:“我想学的是Python数据分析,为什么经常会被引导到Pandas上去?”虽然这两个东西都是以P开头的,但它们并不是同一个层面的东西。简单来说,Pandas是Python这门编程语言中一个专门用来做数据分析的工具,它们的关系如图1所示。接下来我们就说说Python是什么,Pandas又是什么。
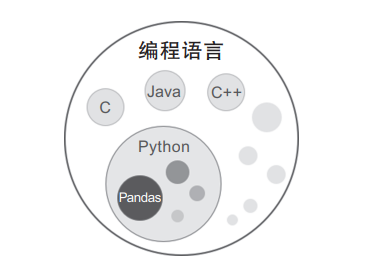
图1 Pandas和Python的关系
Python简介
Python是一门强大的编程语言,它简单易学,提供众多高级数据结构,让我们可以面向对象编程。Python是一门解释型语言,语法优雅贴近人类自然语言,符合人类的认知习惯。
Python支持跨平台,能够运行在所有的常见操作系统上。Python在近期热门的大数据、科学研究、机器学习、人工智能等领域大显身手,并且几乎在所有领域都有应用,因此学习它十分划算。
Python由荷兰人吉多·范罗苏姆(Guido van Rossum)创造,第一版发布于1991年。关于为何有Python这个项目,吉多·范罗苏姆在1996年曾写道:6年前,也就是1989年12月,我在寻找一门“课余”编程项目来打发圣诞节前后的时间。到时我的办公室会关门,而我只有一台家用电脑,没有什么其他东西。我决定为我当时正在构思的新的脚本语言写一个解释器,它是ABC语言的后代,对UNIX/C程序员会有吸引力。当时我对项目叫什么名字并不太在乎,由于我是《蒙提·派森的飞行马戏团》的狂热爱好者,我就选择了用Python作为项目的名字。
《蒙提·派森的飞行马戏团》(Monty Python’s Flying Circus)是BBC播出的英国电视喜剧剧集,蒙提·派森(Monty Python)是创作该剧的六人喜剧团队,由此可见,Python虽原意为蟒蛇,但吉多·范罗苏姆用它来命名一门开发语言,并非出于他对蟒蛇的喜爱,大家不必恐惧。
Python 2.0于2000年10月16日发布。Python 3.0于2008年12月3日发布,此版不完全兼容之前的Python源代码。目前Python的正式版已经更新到3.9版本,且官方不再维护2.0版本,因此建议初学者(包括已经在学习的)至少从3.6版本开始学习Python,之后的版本功能差异不会太大。
Pandas简介
Pandas是使用Python语言开发的用于数据处理和数据分析的第三方库。它擅长处理数字型数据和时间序列数据,当然文本型的数据也能轻松处理。
作为Python的三方库,Pandas是建构在Python的基础上的,它封装了一些复杂的代码实现过程,我们只要调用它的方法就能轻松实现我们的需求。
Python中的库、框架、包意义基本相同,都是别人造好的轮子,我们可以直接使用,以减少重复的逻辑代码。正是由于有众多覆盖各个领域的框架,我们使用起Python来才能简单高效,而不用关注技术实现细节。
Pandas由Wes McKinney于2008年开发。McKinney当时在纽约的一家金融服务机构工作,金融数据分析需要一个健壮和超快速的数据分析工具,于是他就开发出了Pandas。
Pandas的命名跟熊猫无关,而是来自计量经济学中的术语“面板数据”(Panel data)。面板数据是一种数据集的结构类型,具有横截面和时间序列两个维度。不过,我们不必了解它,它只是一种灵感、思想来源。Pandas目前已经更新到1.2.1版本。
02
Pandas的使用人群
Pandas对数据的处理是为数据分析服务的,它所提供的各种数据处理方法、工具是基于数理统计学的,包含了日常应用中的众多数据分析方法。我们学习它不仅要掌控它的相应技术,还要从它的数据处理思路中学习数据分析的理论和方法。
特别地,如果你想要成为数据分析师、数据产品经理、数据开发工程师等与数据相关的工作者,学习Pandas能让你深入数据理论和实践,更好地理解和应用数据。
Pandas可以轻松应对白领们日常工作中的各种表格数据处理需求,还应用在金融、统计、数理研究、物理计算、社会科学、工程等领域。
Pandas可以实现复杂的处理逻辑,这些往往是Excel等工具无法完成的,还可以自动化、批量化,免去我们在处理相同的大量数据时的重复工作。
Pandas可以实现非常震撼的可视化效果,它对接众多令人赏心悦目的可视化库,可以实现动态数据交互效果。
03
Pandas的基本功能
Pandas常用的基本功能如下:
从Excel、CSV、网页、SQL、剪贴板等文件或工具中读取数据;
合并多个文件或者电子表格中的数据,将数据拆分为独立文件;
数据清洗,如去重、处理缺失值、填充默认值、补全格式、处理极端值等;
建立高效的索引;
支持大体量数据;
按一定业务逻辑插入计算后的列、删除列;
灵活方便的数据查询、筛选;
分组聚合数据,可独立指定分组后的各字段计算方式;
数据的转置,如行转列、列转行变更处理;
连接数据库,直接用SQL查询数据并进行处理;
对时序数据进行分组采样,如按季、按月、按工作小时,也可以自定义周期,如工作日;
窗口计算,移动窗口统计、日期移动等;
灵活的可视化图表输出,支持所有的统计图形;
为数据表格增加展示样式,提高数据识别效率。
04
Pandas快速入门
1、安装导入
首先安装pandas库。打开“终端”并执行以下命令:
pip install pandas matplotlib
# 如网络慢,可指定国内源快速下载安装
pip install pandas matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple安装完成后,在终端中启动Jupyter Notebook,给文件命名,如pandas-01。在Jupyter Notebook中导入Pandas,按惯例起别名pd:
# 引入 Pandas库,按惯例起别名pd
import pandas as pd这样,我们就可以使用pd调用Pandas的所有功能了。
2、准备数据集
数据集(Data set或dataset),又称为资料集、数据集合或资料集合,是一种由数据组成的集合,可以简单理解成一个Excel表格。在分析处理数据时,我们要先了解数据集。对所持有数据各字段业务意义的理解是分析数据的前提。
介绍下我们后面会经常用的数据集team.xlsx,可以从网址 https://www.gairuo.com/file/data/dataset/team.xlsx下载。它的内容见表1。
表1 team.xlsx的部分内容
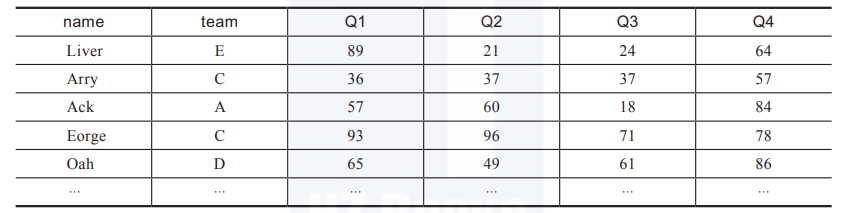
这是一个学生各季度成绩总表(节选),各列说明如下。
name:学生的姓名,这列没有重复值,一个学生一行,即一条数据,共100条。
team:所在的团队、班级,这个数据会重复。
Q1~Q4:各个季度的成绩,可能会有重复值。
3、读取数据
了解了数据集的意义后,我们将数据读取到Pandas里,变量名用df(DataFrame的缩写,后续会介绍),它是Pandas二维数据的基础结构。
import pandas as pd # 引入Pandas库,按惯例起别名pd
# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取
这样就把数据读取到变量df中,输入df看一下内容,在Jupyter Notebook中的执行效果如图2所示。
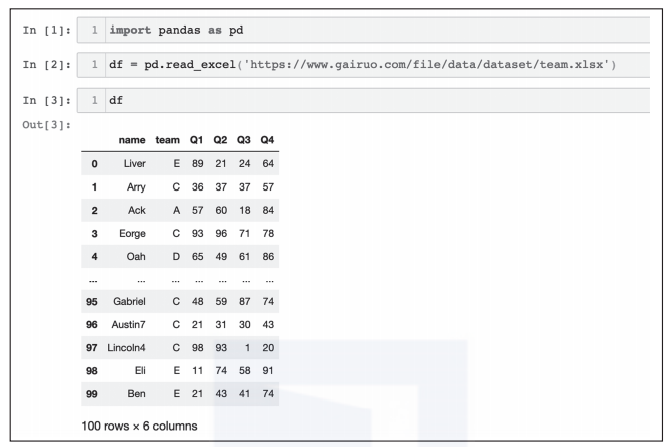
图2 读取数据的执行效果
其中:
自动增加了第一列,是Pandas为数据增加的索引,从0开始,程序不知道我们真正的业务索引,往往需要后面重新指定,使它有一定的业务意义;
由于数据量大,自动隐藏了中间部分,只显示前后5条;
底部显示了行数和列数。
4、查看数据
读取完数据后我们来查看一下数据:
df.head() # 查看前5条,括号里可以写明你想看的条数
df.tail() # 查看尾部5条
df.sample(5) # 随机查看5条
查看前5条时的结果如图3所示。
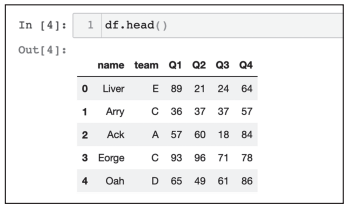
图3 查看df前5条数据
5、验证数据
拿到数据,我们还需要验证一下数据是否加载正确,数据大小是否正常。下面是一些常用的代码,可以执行看看效果(一次执行一行):
df.shape # (100, 6) 查看行数和列数
df.info() # 查看索引、数据类型和内存信息
df.describe() # 查看数值型列的汇总统计
df.dtypes # 查看各字段类型
df.axes # 显示数据行和列名
df.columns # 列名
df.info()显示有数据类型、索引情况、行列数、各字段数据类型、内存占用等:
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 100 entries, 0 to 99
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 100 non-null object
1 team 100 non-null object
2 Q1 100 non-null int64
3 Q2 100 non-null int64
4 Q3 100 non-null int64
5 Q4 100 non-null int64
dtypes: int64(4), object(2)
memory usage: 4.8+ KB
df.describe()会计算出各数字字段的总数(count)、平均数(mean)、标准差(std)、最小值(min)、四分位数和最大值(max):
Out:
Q1 Q2 Q3 Q4
count 100.000000 100.000000 100.000000 100.000000
mean 49.200000 52.550000 52.670000 52.780000
std 29.962603 29.845181 26.543677 27.818524
min 1.000000 1.000000 1.000000 2.000000
25% 19.500000 26.750000 29.500000 29.500000
50% 51.500000 49.500000 55.000000 53.000000
75% 74.250000 77.750000 76.250000 75.250000
max 98.000000 99.000000 99.000000 99.000000
6、建立索引
以上数据真正业务意义上的索引是name列,所以我们需要使它成为索引:
df.set_index('name', inplace=True) # 建立索引并生效
其中可选参数inplace=True会将指定好索引的数据再赋值给df使索引生效,否则索引不会生效。注意,这里并没有修改原Excel,从我们读取数据后就已经和它没有关系了,我们处理的是内存中的df变量。
将name建立索引后,就没有从0开始的数字索引了,如图4所示。
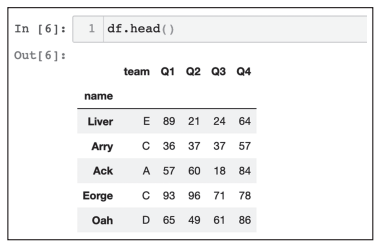
图4 将name设置为索引的执行效果
7、数据选取
接下来,我们像Excel那样,对数据做一些筛选操作。
(1)选择列
选择列的方法如下:
# 查看指定列
df['Q1']
df.Q1 # 同上,如果列名符合Python变量名要求,可使用
显示如下内容:
df.Q1
Out:
0 89
1 36
2 57
3 93
4 65
..
95 48
96 21
97 98
98 11
99 21
Name: Q1, Length: 100, dtype: int64
这里返回的是一个Series类型数据,可以理解为数列,它也是带索引的。之前建立的索引在这里发挥出了作用,否则我们的索引是一个数字,无法知道与之对应的是谁的数据。
选择多列的可以用以下方法:
# 选择多列
df[['team', 'Q1']] # 只看这两列,注意括号
df.loc[:, ['team', 'Q1']] # 和上一行效果一样
df.loc[x, y]是一个非常强大的数据选择函数,其中x代表行,y代表列,行和列都支持条件表达式,也支持类似列表那样的切片(如果要用自然索引,需要用df.iloc[])。下面的例子中会进行演示。
(2)选择行
选择行的方法如下:
# 用指定索引选取
df[df.index == 'Liver'] # 指定姓名
# 用自然索引选择,类似列表的切片
df[0:3] # 取前三行
df[0:10:2] # 在前10个中每两个取一个
df.iloc[:10,:] # 前10个
(3)指定行和列
同时给定行和列的显示范围:
df.loc['Ben', 'Q1':'Q4'] # 只看Ben的四个季度成绩
df.loc['Eorge':'Alexander', 'team':'Q4'] # 指定行区间
(4)条件选择
按一定的条件显示数据:
# 单一条件
df[df.Q1 > 90] # Q1列大于90的
df[df.team == 'C'] # team列为'C'的
df[df.index == 'Oscar'] # 指定索引即原数据中的name
# 组合条件
df[(df['Q1'] > 90) & (df['team'] == 'C')] # and关系
df[df['team'] == 'C'].loc[df.Q1>90] # 多重筛选
8、排序
Pandas的排序非常方便,示例如下:
df.sort_values(by='Q1') # 按Q1列数据升序排列
df.sort_values(by='Q1', ascending=False) # 降序
df.sort_values(['team', 'Q1'], ascending=[True, False]) # team升序,Q1降序
9、分组聚合
我们可以实现类似SQL的groupby那样的数据透视功能:
df.groupby('team').sum() # 按团队分组对应列相加
df.groupby('team').mean() # 按团队分组对应列求平均
# 不同列不同的计算方法
df.groupby('team').agg({'Q1': sum, # 总和
'Q2': 'count', # 总数
'Q3':'mean', # 平均
'Q4': max}) # 最大值
统一聚合执行后的效果如图5所示。
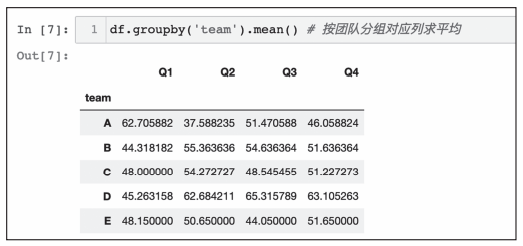
图5 按team分组后求平均数
不同计算方法聚合执行后的效果如图6所示。
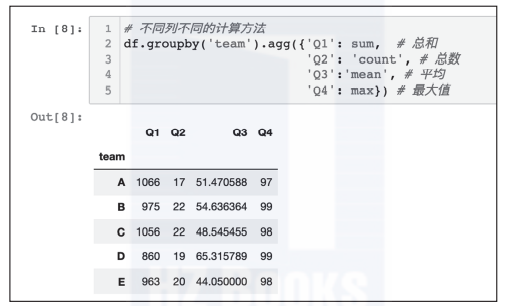
图6 分组后每列用不同的方法聚合计算
10、数据转换
对数据表进行转置,对类似图6中的数据以A-Q1、E-Q4两点连成的折线为轴对数据进行翻转,效果如图7所示,不过我们这里仅用sum聚合。
df.groupby('team').sum().T
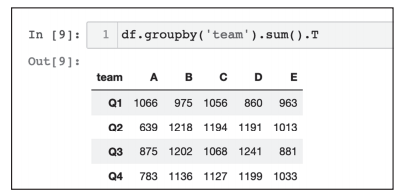
图7 对聚合后的数据进行翻转
也可以试试以下代码,看有什么效果:
df.groupby('team').sum().stack()
df.groupby('team').sum().unstack()
11、增加列
用Pandas增加一列非常方便,就与新定义一个字典的键值一样。
df['one'] = 1 # 增加一个固定值的列
df['total'] = df.Q1 + df.Q2 + df.Q3 + df.Q4 # 增加总成绩列
# 将计算得来的结果赋值给新列
df['total'] = df.loc[:,'Q1':'Q4'].apply(lambda x:sum(x), axis=1)
df['total'] = df.sum(axis=1) # 可以把所有为数字的列相加
df['avg'] = df.total/4 # 增加平均成绩列
12、统计分析
根据你的数据分析目标,试着使用以下函数,看看能得到什么结论。
df.mean() # 返回所有列的均值
df.mean(1) # 返回所有行的均值,下同
df.corr() # 返回列与列之间的相关系数
df.count() # 返回每一列中的非空值的个数
df.max() # 返回每一列的最大值
df.min() # 返回每一列的最小值
df.median() # 返回每一列的中位数
df.std() # 返回每一列的标准差
df.var() # 方差
s.mode() # 众数
13、绘图
Pandas利用plot()调用Matplotlib快速绘制出数据可视化图形。注意,第一次使用plot()时可能需要执行两次才能显示图形。如图8所示,可以使用plot()快速绘制折线图。
df['Q1'].plot() # Q1成绩的折线分布
图8 利用plot()快速绘制折线图
如图9所示,可以先选择要展示的数据,再绘图。
df.loc['Ben','Q1':'Q4'].plot() # ben四个季度的成绩变化

图9 选择部分数据绘制折线图
如图10所示,可以使用plot.bar绘制柱状图。
df.loc[ 'Ben','Q1':'Q4'].plot.bar() # 柱状图
df.loc[ 'Ben','Q1':'Q4'].plot.barh() # 横向柱状图
图10 利用plot.bar绘制的柱状图
如果想绘制横向柱状图,可以将bar更换为barh,如图11所示。
图11 利用barh绘制的横向柱状图
对数据聚合计算后,可以绘制成多条折线图,如图12所示。
# 各Team四个季度总成绩趋势
df.groupby('team').sum().T.plot()

图12 多条折线图
也可以用pie绘制饼图,如图13所示。
# 各组人数对比
df.groupby('team').count().Q1.plot.pie()

图13 饼图的绘制效果
14、导出
可以非常轻松地导出Excel和CSV文件。
df.to_excel('team-done.xlsx') # 导出 Excel文件
df.to_csv('team-done.csv') # 导出 CSV文件
导出的文件位于notebook文件的同一目录下,打开看看。
本文我们了解了编程语言Python的特点,为什么要学Python,Pandas库的功能,快速感受了一下Pandas强大的数据处理和数据分析能力。这些是我们进入数据科学领域的基础。
本文摘编于《深入浅出Pandas:利用Python进行数据处理与分析》,经出版方授权发布。
作者:李庆辉
数据产品专家,某电商公司数据产品团队负责人,擅长通过数据治理、数据分析、数据化运营提升公司的数据应用水平。
**-----**------**-----**---**** 送书 **-----**--------**-----**-****
欢迎各位大佬点击链接加入群聊【helloworld开发者社区】:https://jq.qq.com/?_wv=1027&k=mBlk6nzX进群交流IT技术热点。
往期精彩文章推荐:













