
本文源码:GitHub·点这里 || GitEE·点这里
一、工作机制
1、基础描述
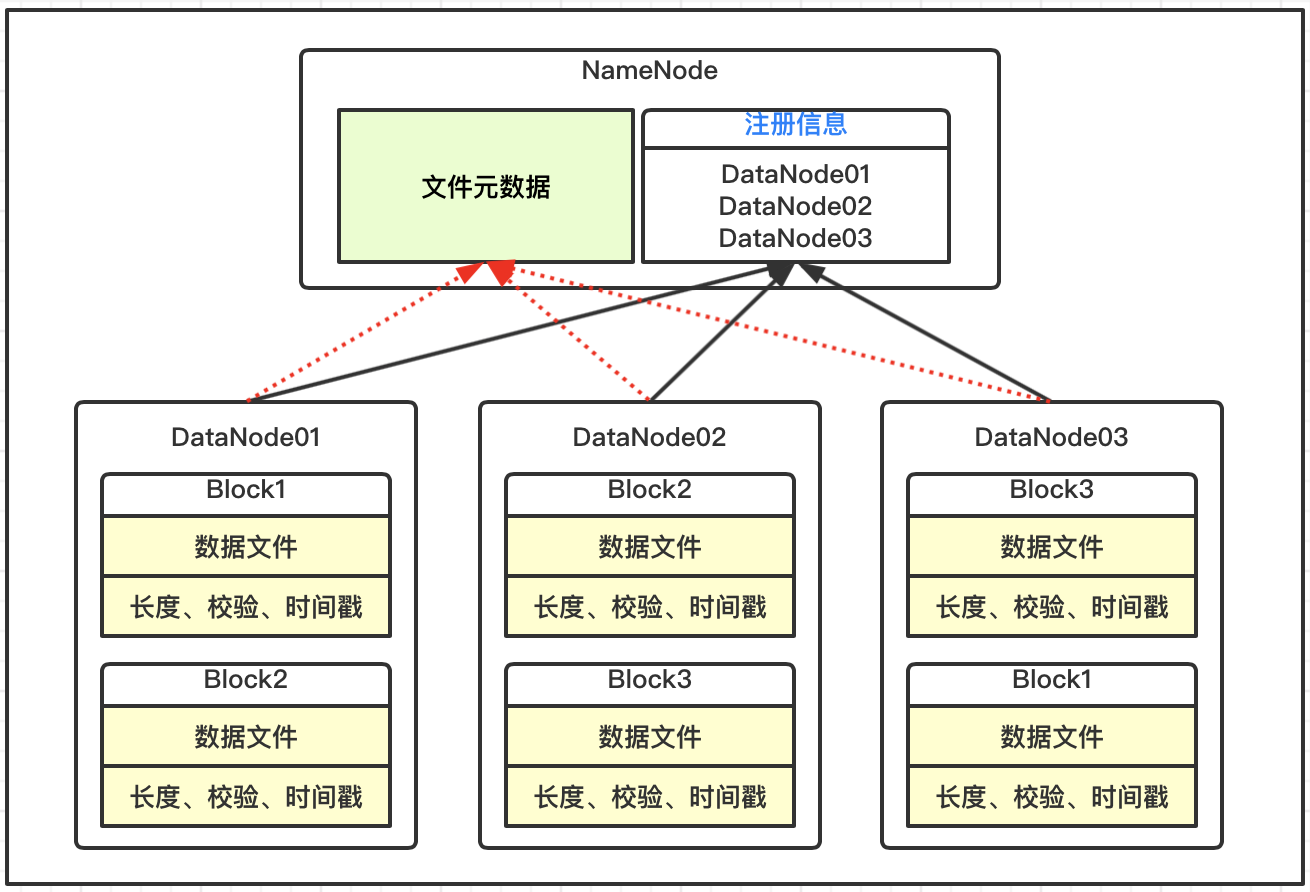
DataNode上数据块以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是数据块元数据包括长度、校验、时间戳;
DataNode启动后向NameNode服务注册,并周期性的向NameNode上报所有的数据块元数据信息;
DataNode与NameNode之间存在心跳机制,每3秒一次,返回结果带有NameNode给该DataNode的执行命令,例如数据复制删除等,如果超过10分钟没有收到DataNode的心跳,则认为该节点不可用。
2、自定义时长
通过hdfs-site.xml配置文件,修改超时时长和心跳,其中中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>600000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>6</value>
</property>
3、新节点上线
当前机器的节点为hop01、hop02、hop03,在此基础上新增节点hop04。
基本步骤
基于当前一个服务节点克隆得到hop04环境;
修改Centos7相关基础配置,并删除data和log文件;
启动DataNode,即可关联到集群;
4、多目录配置
该配置同步集群下服务,格式化启动hdfs及yarn,上传文件测试。
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data01,file:///${hadoop.tmp.dir}/dfs/data02</value>
</property>
二、黑白名单配置
1、白名单设置
配置白名单,该配置分发到集群服务下;
[root@hop01 hadoop]# pwd
/opt/hadoop2.7/etc/hadoop
[root@hop01 hadoop]# vim dfs.hosts
hop01
hop02
hop03
配置hdfs-site.xml,该配置分发到集群服务下;
<property>
<name>dfs.hosts</name>
<value>/opt/hadoop2.7/etc/hadoop/dfs.hosts</value>
</property>
刷新NameNode
[root@hop01 hadoop2.7]# hdfs dfsadmin -refreshNodes
刷新ResourceManager
[root@hop01 hadoop2.7]# yarn rmadmin -refreshNodes
2、黑名单设置
配置黑名单,该配置分发到集群服务下;
[root@hop01 hadoop]# pwd
/opt/hadoop2.7/etc/hadoop
[root@hop01 hadoop]# vim dfs.hosts.exclude
hop04
配置hdfs-site.xml,该配置分发到集群服务下;
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/hadoop2.7/etc/hadoop/dfs.hosts.exclude</value>
</property>
刷新NameNode
[root@hop01 hadoop2.7]# hdfs dfsadmin -refreshNodes
刷新ResourceManager
[root@hop01 hadoop2.7]# yarn rmadmin -refreshNodes
三、文件存档
1、基础描述
HDFS存储的特点,适合海量数据的大文件,如果每个文件都很小,会产生大量的元数据信息,占用过多的内存,并且在NaemNode和DataNode交互的时候变的缓慢。
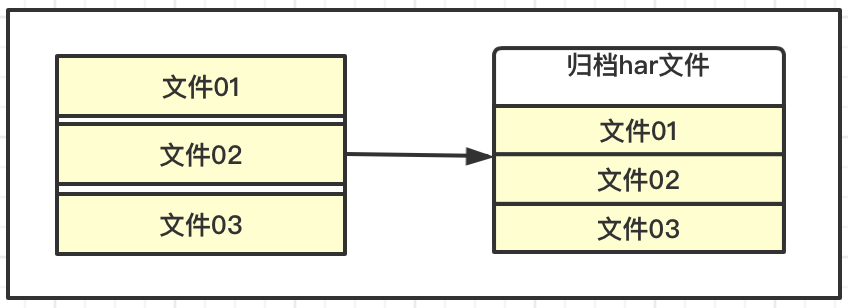
HDFS可以对一些小的文件进行归档存储,这里可以理解为压缩存储,即减少NameNode的消耗,也较少交互的负担,同时还允许对归档的小文件访问,提高整体的效率。
2、操作流程
创建两个目录
# 存放小文件
[root@hop01 hadoop2.7]# hadoop fs -mkdir -p /hopdir/harinput
# 存放归档文件
[root@hop01 hadoop2.7]# hadoop fs -mkdir -p /hopdir/haroutput
上传测试文件
[root@hop01 hadoop2.7]# hadoop fs -moveFromLocal LICENSE.txt /hopdir/harinput
[root@hop01 hadoop2.7]# hadoop fs -moveFromLocal README.txt /hopdir/harinput
归档操作
[root@hop01 hadoop2.7]# bin/hadoop archive -archiveName output.har -p /hopdir/harinput /hopdir/haroutput
查看归档文件
[root@hop01 hadoop2.7]# hadoop fs -lsr har:///hopdir/haroutput/output.har

这样就可以把原来的那些小文件块删除即可。
解除归档文件
# 执行解除
[root@hop01 hadoop2.7]# hadoop fs -cp har:///hopdir/haroutput/output.har/* /hopdir/haroutput
# 查看文件
[root@hop01 hadoop2.7]# hadoop fs -ls /hopdir/haroutput
四、回收站机制
1、基础描述
如果开启回收站功能,被删除的文件在指定的时间内,可以执行恢复操作,防止数据被误删除情况。HDFS内部的具体实现就是在NameNode中启动一个后台线程Emptier,这个线程专门管理和监控系统回收站下面的文件,对于放进回收站的文件且超过生命周期,就会自动删除。
2、开启配置
该配置需要同步到集群下的所有服务;
[root@hop01 hadoop]# vim /opt/hadoop2.7/etc/hadoop/core-site.xml
# 添加内容
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
fs.trash.interval=0,表示禁用回收站机制,=1表示开启。
五、源代码地址
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parent






