
本文源码:GitHub·点这里 || GitEE·点这里
一、Yarn基本结构
Hadoop三大核心组件:分布式文件系统HDFS、分布式计算框架MapReduce,分布式集群资源调度框架Yarn。Yarn并不是在Hadoop初期就有的,是在Hadoop升级发展才诞生的,典型的Master-Slave架构。
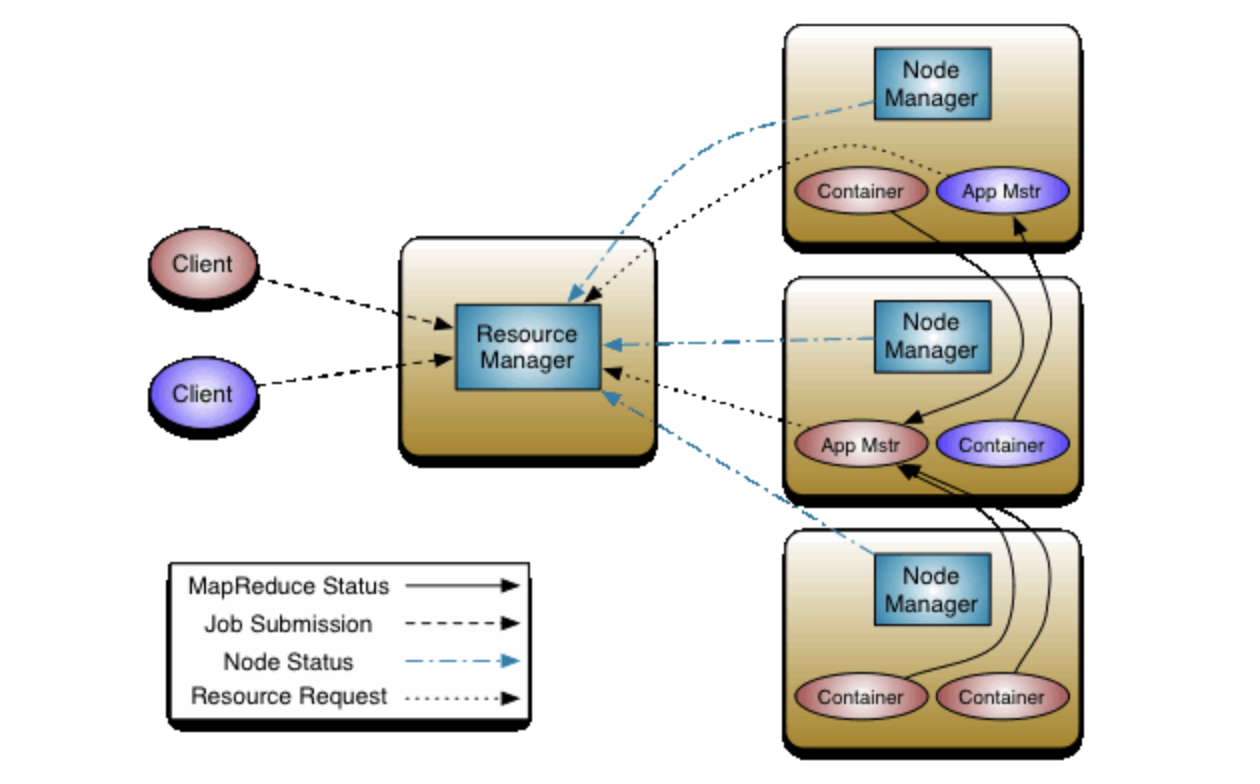
Yarn包括两个主要进程:资源管理器Resource-Manager,节点管理器Node-Manager。
资源管理器
- 通常部署在独立的服务器,处理客户端请求;
- 处理集群中的资源分配和调度管理;
节点管理器
- 管理当前节点上的资源;
- 执行处理各种具体的命令;
- 监视节点资源情况,并上报资源管理器;
ApplicationMaster
- 提供容错能力,切割数据;
- 给应用程序申请资源并分配任务;
Container
- Yarn中的一个动态资源分配的概念;
- 容器包含了一定量的内存、CPU等计算资源;
- 由NodeManager进程启动和管理;
二、基本执行流程
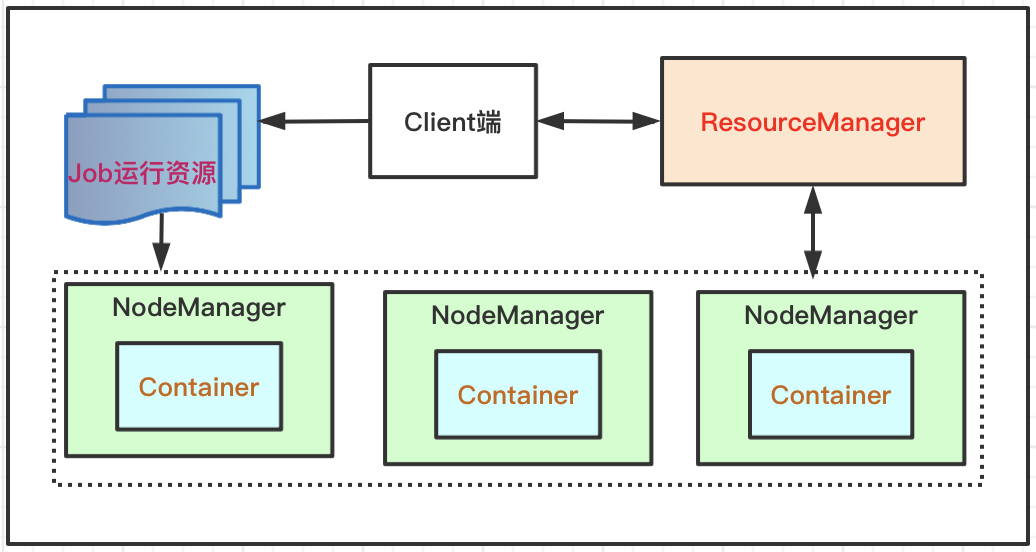
- 向Yarn提交MapReduce应用程序程序进行调度;
- RM组件返回资源提交路径和ApplicationId;
- RM进程NM进程通信,根据集群资源分配容器;
- 将MRAppMaster分发到上面分配的容器上面;
- 运行所需资源提交到HDFS上申请运行MRAppMaster;
- RM经过上述操作把客户端请求转换为Task任务;
- 容器中运行的就是Map或者Reduce任务;
- 任务在运行期间和MRAppMaster通信上报状态;
- 任务执行结束后进程注销并且释放容器资源;
MapReduce应用开发遵循Yarn规范的MapReduceApplicationMaster,所以可以在Yarn上运行,其它计算框架如果也遵守该规范,这样就实现资源的统一调度管理。
三、资源调度器
调度器的基本作用就是根据节点资源的使用情况和作业需求,将任务调度到各个节点上执行。单理解任务队列的话关键的因素有如下几个:进出方式,优先级,容量等。
Hadoop作业调度器主要有三种:FIFO、CapacityScheduler和FairScheduler,默认的资源调度器是CapacityScheduler。
先进先出调度器
FIFO一种批处理调度器,调度策略先按照作业的优先级高低,再按照到达时间的先后选择被执行的作业。
容量调度器
CapacityScheduler支持多个队列,每个队列可配置一定的资源量,每个队列采用FIFO调度策略,计算队列中正在运行的任务书和计算资源的比值,选中比值小相对空闲的队列,然后安装作业优先级和提交时间的排序。为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
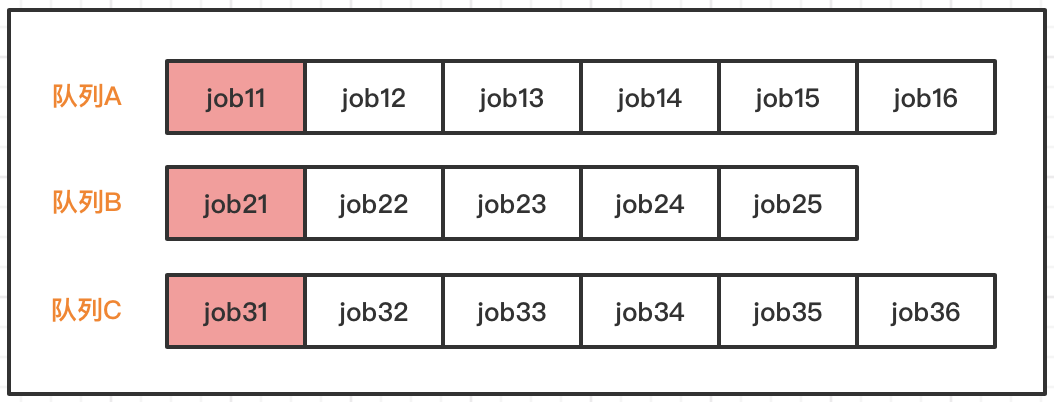
例如上面图例,假设100个slot分为三个队列(ABC),按照如下分配规则:队列A给20%的资源,队列B给50%的资源,队列C给30%的资源;三个队列都按照任务的先后顺序依次执行,上面的job11、job21、job31是最先运行,也是并行运行。
公平调度器
和容量调度器原理类似,支持多队列多用户,每个队列中的资源量可以配置,同一队列中的作业公平共享队列中所有资源。
比如有三个队列(ABC),每个队列中的job按照优先级分配资源,优先级越高分配的资源越多,但是每个job都会分配到资源以确保公平。在资源有限的情况下,每个job理想情况下获得的计算资源与实际获得的计算资源存在一种差距,,这个差距就叫做缺额。在同一个队列中,job的资源缺额越大,越先获得资源优先执行,作业是按照缺额的高低来先后执行的。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parent












