
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
下面是单机安装采坑记,直接上配置和问题解决。
找一台干净的机器,把hadoop hive hbase从原有节点分别拷贝一份,主要目的是配置文件,可以不在kylin所在机器启动相关进程。
开源版本搭建,非整合HDP和CDH。
个别问题解决参考其他博客。
官网http://kylin.apache.org/cn/docs/
MapReduce构建Cube的问题也已解决,所以使用MapReduce构建Cube也是正常的。
版本
java-1.8.0-openjdk-1.8.0.191.b12-1.el7_6.x86_64hadoop-2.8.5【官网下载】hbase-1.4.10【官网下载】hive-2.3.5【官网下载】apache-kylin-2.6.3-bin-hbase1x【官网下载】spark-2.3.2【$KYLIN_HOME/spark 通过$KYLIN_HOME/bin/download-spark.sh下载】spark-2.3.2-yarn-shuffle.jar【https://github.com/apache/spark/releases/tag/v2.3.2下载Source code自行编译(Oracle JDK1.8.0_181 hadoop2.7.3)】
环境变量
JAVA_HOME等。
123456789101112131415161718
export HADOOP_HOME=/home/admin/hadoop-2.8.5export PATH="$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH"export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport HBASE_HOME=/home/admin/hbase-1.4.10export PATH="$HBASE_HOME/bin:$HBASE_HOME/sbin:$PATH"export HIVE_HOME=/home/admin/hive-2.3.5export PATH="$HIVE_HOME/bin:$HIVE_HOME/sbin:$PATH"export HCAT_HOME=$HIVE_HOME/hcatalogexport KYLIN_HOME=/home/admin/kylin-2.6.3export KYLIN_CONF_HOME=$KYLIN_HOME/confexport CATALINA_HOME=$KYLIN_HOME/tomcatexport PATH=:$PATH:$KYLIN_HOME/bin:$CATALINE_HOME/binexport tomcat_root=$KYLIN_HOME/tomcatexport hive_dependency=$HIVE_HOME/conf:$HIVE_HOME/lib/*:$HCAT_HOME/share/hcatalog/hive-hcatalog-core-2.3.5.jar
下载spark和上传spark的依赖包
从v2.6.1开始, Kylin不再包含Spark二进制包;需要另外下载Spark,然后设置SPARK_HOME系统变量到Spark安装目录(可以不设置,详见$KYLIN_HOME/bin/find-spark-dependency.sh)
使用脚本下载Spark[下载后的目录位于$KYLIN_HOME/spark]:
1
$ $KYLIN_HOME/bin/download-spark.sh
把Spark依赖的jars打包成一个jar上传到HDFS上面,这里参照官网,另外打包成zip也是可以的:
123
$ jar cv0f spark-libs.jar -C $KYLIN_HOME/spark/jars/ .$ hadoop fs -mkdir -p /kylin/spark/$ hadoop fs -put spark-libs.jar /kylin/spark/
并在$KYLIN_HOME/conf/kylin.properties里面或者$KYLIN_HOME/spark/conf/spark-defaults.conf里面进行配置:
分别是kylin.engine.spark-conf.spark.yarn.archive和
spark.yarn.archive,配置其一即可。
主要配置
$KYLIN_HOME/conf/kylin.properties
有些虽然解除了注释#,但并非必须的,默认值也可以;
另外在环境变量都设置好的情况下,比如HADOOP_CONF_DIR,不需要再配置kylin.env.hadoop-conf-dir。
说明:
SPARK ENGINE CONFIGS下面kylin.engine.spark-conf.xxxx
后面xxxx这种配置,完全可以在$KYLIN_HOME/spark/conf下的spark-defaults.conf里面进行配置。
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167168169170171172173174175176177178179180181182183184185186187188189190191192193194195196197198199200201202203204205206207208209210211212213214215216217218219220221222223224225226227228229230231232233234235236237238239240241242243244245246247248249250251252253254255256257258259260261262263264265266267268269270271272273274275276277278279280281282283284285286287288289290291292293294295296297298299300301302303304305306307308309310311312313314315316317318319320321322323324325326327328329330331332333334335336337338339340341342343344345346347348349
##### METADATA | ENV ###### The metadata store in hbasekylin.metadata.url=kylin_metadata@hbase### metadata cache sync retry timeskylin.metadata.sync-retries=3### Working folder in HDFS, better be qualified absolute path, make sure user has the right permission to this directorykylin.env.hdfs-working-dir=/kylin### DEV|QA|PROD. DEV will turn on some dev features, QA and PROD has no difference in terms of functions.kylin.env=QA### kylin zk base pathkylin.env.zookeeper-base-path=/kylin##### SERVER | WEB | RESTCLIENT ###### Kylin server mode, valid value [all, query, job]kylin.server.mode=all### List of web servers in use, this enables one web server instance to sync up with other servers.kylin.server.cluster-servers=192.168.100.2:7070### Display timezone on UI,format like[GMT+N or GMT-N]kylin.web.timezone=GMT+8### Timeout value for the queries submitted through the Web UI, in millisecondskylin.web.query-timeout=300000#kylin.web.cross-domain-enabled=true###allow user to export query resultkylin.web.export-allow-admin=truekylin.web.export-allow-other=true### Hide measures in measure list of cube designer, separate by commakylin.web.hide-measures=RAW###max connections of one route#kylin.restclient.connection.default-max-per-route=20###max connections of one rest-client#kylin.restclient.connection.max-total=200##### PUBLIC CONFIG ####kylin.engine.default=2#kylin.storage.default=2#kylin.web.hive-limit=20#kylin.web.help.length=4#kylin.web.help.0=start|Getting Started|http://kylin.apache.org/docs/tutorial/kylin_sample.html#kylin.web.help.1=odbc|ODBC Driver|http://kylin.apache.org/docs/tutorial/odbc.html#kylin.web.help.2=tableau|Tableau Guide|http://kylin.apache.org/docs/tutorial/tableau_91.html#kylin.web.help.3=onboard|Cube Design Tutorial|http://kylin.apache.org/docs/howto/howto_optimize_cubes.html#kylin.web.link-streaming-guide=http://kylin.apache.org/#kylin.htrace.show-gui-trace-toggle=false#kylin.web.link-hadoop=#kylin.web.link-diagnostic=#kylin.web.contact-mail=#kylin.server.external-acl-provider=##### SOURCE ###### Hive client, valid value [cli, beeline]#kylin.source.hive.client=cli### Absolute path to beeline shell, can be set to spark beeline instead of the default hive beeline on PATH#kylin.source.hive.beeline-shell=beeline### Parameters for beeline client, only necessary if hive client is beeline##kylin.source.hive.beeline-params=-n root --hiveconf hive.security.authorization.sqlstd.confwhitelist.append='mapreduce.job.*|dfs.*' -u jdbc:hive2://localhost:10000### While hive client uses above settings to read hive table metadata,## table operations can go through a separate SparkSQL command line, given SparkSQL connects to the same Hive metastore.#kylin.source.hive.enable-sparksql-for-table-ops=false##kylin.source.hive.sparksql-beeline-shell=/path/to/spark-client/bin/beeline##kylin.source.hive.sparksql-beeline-params=-n root --hiveconf hive.security.authorization.sqlstd.confwhitelist.append='mapreduce.job.*|dfs.*' -u jdbc:hive2://localhost:10000##kylin.source.hive.keep-flat-table=false### Hive database name for putting the intermediate flat tableskylin.source.hive.database-for-flat-table=kylin_flat_db### Whether redistribute the intermediate flat table before building#kylin.source.hive.redistribute-flat-table=true###### STORAGE ###### The storage for final cube file in hbasekylin.storage.url=hbase### The prefix of hbase tablekylin.storage.hbase.table-name-prefix=KYLIN_### The namespace for hbase storagekylin.storage.hbase.namespace=default### Compression codec for htable, valid value [none, snappy, lzo, gzip, lz4]kylin.storage.hbase.compression-codec=none### HBase Cluster FileSystem, which serving hbase, format as hdfs://hbase-cluster:8020## Leave empty if hbase running on same cluster with hive and mapreduce##kylin.storage.hbase.cluster-fs=### The cut size for hbase region, in GB.kylin.storage.hbase.region-cut-gb=5### The hfile size of GB, smaller hfile leading to the converting hfile MR has more reducers and be faster.## Set 0 to disable this optimization.kylin.storage.hbase.hfile-size-gb=2##kylin.storage.hbase.min-region-count=1#kylin.storage.hbase.max-region-count=500### Optional information for the owner of kylin platform, it can be your team's email## Currently it will be attached to each kylin's htable attribute#kylin.storage.hbase.owner-tag=whoami@kylin.apache.org##kylin.storage.hbase.coprocessor-mem-gb=3### By default kylin can spill query's intermediate results to disks when it's consuming too much memory.## Set it to false if you want query to abort immediately in such condition.#kylin.storage.partition.aggr-spill-enabled=true### The maximum number of bytes each coprocessor is allowed to scan.## To allow arbitrary large scan, you can set it to 0.#kylin.storage.partition.max-scan-bytes=3221225472### The default coprocessor timeout is (hbase.rpc.timeout * 0.9) / 1000 seconds,## You can set it to a smaller value. 0 means use default.## kylin.storage.hbase.coprocessor-timeout-seconds=0### clean real storage after delete operation## if you want to delete the real storage like htable of deleting segment, you can set it to true#kylin.storage.clean-after-delete-operation=false##### JOB ###### Max job retry on error, default 0: no retrykylin.job.retry=0### Max count of concurrent jobs runningkylin.job.max-concurrent-jobs=10### The percentage of the sampling, default 100%#kylin.job.sampling-percentage=100### If true, will send email notification on job complete##kylin.job.notification-enabled=true##kylin.job.notification-mail-enable-starttls=true##kylin.job.notification-mail-host=smtp.office365.com##kylin.job.notification-mail-port=587##kylin.job.notification-mail-username=kylin@example.com##kylin.job.notification-mail-password=mypassword##kylin.job.notification-mail-sender=kylin@example.com###### ENGINE ###### Time interval to check hadoop job statuskylin.engine.mr.yarn-check-interval-seconds=10##kylin.engine.mr.reduce-input-mb=500##kylin.engine.mr.max-reducer-number=500##kylin.engine.mr.mapper-input-rows=1000000### Enable dictionary building in MR reducer#kylin.engine.mr.build-dict-in-reducer=true### Number of reducers for fetching UHC column distinct values#kylin.engine.mr.uhc-reducer-count=3### Whether using an additional step to build UHC dictionary#kylin.engine.mr.build-uhc-dict-in-additional-step=false###### CUBE | DICTIONARY #####kylin.cube.cuboid-scheduler=org.apache.kylin.cube.cuboid.DefaultCuboidScheduler#kylin.cube.segment-advisor=org.apache.kylin.cube.CubeSegmentAdvisor### 'auto', 'inmem', 'layer' or 'random' for testing#kylin.cube.algorithm=layer### A smaller threshold prefers layer, a larger threshold prefers in-mem#kylin.cube.algorithm.layer-or-inmem-threshold=7### auto use inmem algorithm:## 1, cube planner optimize job## 2, no source record#kylin.cube.algorithm.inmem-auto-optimize=true##kylin.cube.aggrgroup.max-combination=32768##kylin.snapshot.max-mb=300##kylin.cube.cubeplanner.enabled=true#kylin.cube.cubeplanner.enabled-for-existing-cube=true#kylin.cube.cubeplanner.expansion-threshold=15.0#kylin.cube.cubeplanner.recommend-cache-max-size=200#kylin.cube.cubeplanner.mandatory-rollup-threshold=1000#kylin.cube.cubeplanner.algorithm-threshold-greedy=8#kylin.cube.cubeplanner.algorithm-threshold-genetic=23###### QUERY ###### Controls the maximum number of bytes a query is allowed to scan storage.## The default value 0 means no limit.## The counterpart kylin.storage.partition.max-scan-bytes sets the maximum per coprocessor.#kylin.query.max-scan-bytes=0##kylin.query.cache-enabled=true### Controls extras properties for Calcite jdbc driver## all extras properties should undder prefix "kylin.query.calcite.extras-props."## case sensitive, default: true, to enable case insensitive set it to false## @see org.apache.calcite.config.CalciteConnectionProperty.CASE_SENSITIVE#kylin.query.calcite.extras-props.caseSensitive=true## how to handle unquoted identity, defualt: TO_UPPER, available options: UNCHANGED, TO_UPPER, TO_LOWER## @see org.apache.calcite.config.CalciteConnectionProperty.UNQUOTED_CASING#kylin.query.calcite.extras-props.unquotedCasing=TO_UPPER## quoting method, default: DOUBLE_QUOTE, available options: DOUBLE_QUOTE, BACK_TICK, BRACKET## @see org.apache.calcite.config.CalciteConnectionProperty.QUOTING#kylin.query.calcite.extras-props.quoting=DOUBLE_QUOTE## change SqlConformance from DEFAULT to LENIENT to enable group by ordinal## @see org.apache.calcite.sql.validate.SqlConformance.SqlConformanceEnum#kylin.query.calcite.extras-props.conformance=LENIENT### TABLE ACL#kylin.query.security.table-acl-enabled=true### Usually should not modify this#kylin.query.interceptors=org.apache.kylin.rest.security.TableInterceptor##kylin.query.escape-default-keyword=false### Usually should not modify this#kylin.query.transformers=org.apache.kylin.query.util.DefaultQueryTransformer,org.apache.kylin.query.util.KeywordDefaultDirtyHack##### SECURITY ###### Spring security profile, options: testing, ldap, saml## with "testing" profile, user can use pre-defined name/pwd like KYLIN/ADMIN to login#kylin.security.profile=testing### Admin roles in LDAP, for ldap and saml#kylin.security.acl.admin-role=admin### LDAP authentication configuration#kylin.security.ldap.connection-server=ldap://ldap_server:389#kylin.security.ldap.connection-username=#kylin.security.ldap.connection-password=### LDAP user account directory;#kylin.security.ldap.user-search-base=#kylin.security.ldap.user-search-pattern=#kylin.security.ldap.user-group-search-base=#kylin.security.ldap.user-group-search-filter=(|(member={0})(memberUid={1}))### LDAP service account directory#kylin.security.ldap.service-search-base=#kylin.security.ldap.service-search-pattern=#kylin.security.ldap.service-group-search-base=#### SAML configurations for SSO## SAML IDP metadata file location#kylin.security.saml.metadata-file=classpath:sso_metadata.xml#kylin.security.saml.metadata-entity-base-url=https://hostname/kylin#kylin.security.saml.keystore-file=classpath:samlKeystore.jks#kylin.security.saml.context-scheme=https#kylin.security.saml.context-server-name=hostname#kylin.security.saml.context-server-port=443#kylin.security.saml.context-path=/kylin##### SPARK ENGINE CONFIGS ###### Hadoop conf folder, will export this as "HADOOP_CONF_DIR" to run spark-submit## This must contain site xmls of core, yarn, hive, and hbase in one folder# kylin.env.hadoop-conf-dir=/home/admin/hadoop-2.8.5/etc/hadoop### Estimate the RDD partition numberskylin.engine.spark.rdd-partition-cut-mb=100### Minimal partition numbers of rdd#kylin.engine.spark.min-partition=1### Max partition numbers of rdd#kylin.engine.spark.max-partition=5000### Spark conf (default is in spark/conf/spark-defaults.conf)kylin.engine.spark-conf.spark.master=yarnkylin.engine.spark-conf.spark.submit.deployMode=clusterkylin.engine.spark-conf.spark.yarn.queue=defaultkylin.engine.spark-conf.spark.driver.memory=2Gkylin.engine.spark-conf.spark.executor.memory=1Gkylin.engine.spark-conf.spark.executor.instances=40kylin.engine.spark-conf.spark.yarn.executor.memoryOverhead=1024kylin.engine.spark-conf.spark.shuffle.service.enabled=truekylin.engine.spark-conf.spark.eventLog.enabled=truekylin.engine.spark-conf.spark.eventLog.dir=hdfs\:///kylin/spark-historykylin.engine.spark-conf.spark.history.fs.logDirectory=hdfs\:///kylin/spark-historykylin.engine.spark-conf.spark.hadoop.yarn.timeline-service.enabled=false##### Spark conf for specific jobkylin.engine.spark-conf-mergedict.spark.executor.memory=2Gkylin.engine.spark-conf-mergedict.spark.memory.fraction=0.2### manually upload spark-assembly jar to HDFS and then set this property will avoid repeatedly uploading jar at runtimekylin.engine.spark-conf.spark.yarn.archive=hdfs://master:9000/kylin/spark/spark-libs.jar##kylin.engine.spark-conf.spark.io.compression.codec=org.apache.spark.io.SnappyCompressionCodec### uncomment for HDP##kylin.engine.spark-conf.spark.driver.extraJavaOptions=-Dhdp.version=current##kylin.engine.spark-conf.spark.yarn.am.extraJavaOptions=-Dhdp.version=current##kylin.engine.spark-conf.spark.executor.extraJavaOptions=-Dhdp.version=current###### QUERY PUSH DOWN ######kylin.query.pushdown.runner-class-name=org.apache.kylin.query.adhoc.PushDownRunnerJdbcImpl###kylin.query.pushdown.update-enabled=false##kylin.query.pushdown.jdbc.url=jdbc:hive2://sandbox:10000/default##kylin.query.pushdown.jdbc.driver=org.apache.hive.jdbc.HiveDriver##kylin.query.pushdown.jdbc.username=hive##kylin.query.pushdown.jdbc.password=###kylin.query.pushdown.jdbc.pool-max-total=8##kylin.query.pushdown.jdbc.pool-max-idle=8##kylin.query.pushdown.jdbc.pool-min-idle=0##### JDBC Data Source##kylin.source.jdbc.connection-url=##kylin.source.jdbc.driver=##kylin.source.jdbc.dialect=##kylin.source.jdbc.user=##kylin.source.jdbc.pass=##kylin.source.jdbc.sqoop-home=##kylin.source.jdbc.filed-delimiter=|kylin.job.jar=$KYLIN_HOME/lib/kylin-job-2.6.3.jarkylin.coprocessor.local.jar=$KYLIN_HOME/lib/kylin-coprocessor-2.6.3.jar
检查运行环境
1
$ $KYLIN_HOME/bin/check-env.sh
trouble shooting
日志目录:$KYLIN_HOME/logs下面有kylin.log、kylin.out 还有gc日志
问题0:默认使用hbase配置里的ZK-UnknownHostException
检查运行环境就会报。
1
Caused by: java.net.UnknownHostException: 192.168.100.5:12181: invalid IPv6 address
说明hbase里zk的配置是host:port;kylin读取zk配置的方式是单独读取host和port,修改为host和port分开配置。
修改hbase的配置文件,kylin所在机器的配置文件修改一下就行,为了保持一致,全部修改下再重启hbase。
$HBASE_HOME/conf/hbase-site.xml
12345678
<property> <name>hbase.zookeeper.property.clientPort</name> <value>12181</value></property><property> <name>hbase.zookeeper.quorum</name> <value>192.168.100.5,192.168.100.6,192.168.100.7</value></property>
环境正常后,加载示例数据并启动kylin server
123456
$ $KYLIN_HOME/bin/sample.sh$ $KYLIN_HOME/bin/kylin.sh start...A new Kylin instance is started by admin. To stop it, run 'kylin.sh stop'Check the log at /home/admin/kylin-2.6.3/logs/kylin.logWeb UI is at http://slave1:7070/kylin
问题1:访问http://192.168.100.2:7070/kylin 404
12345
SEVERE: Failed to load keystore type JKS with path conf/.keystore due to /home/admin/kylin-2.6.3/tomcat/conf/.keystore (No such file or directory)java.io.FileNotFoundException: /home/admin/kylin-2.6.3/tomcat/conf/.keystore (No such file or directory)SEVERE: Context [/kylin] startup failed due to previous errorsInvalid character found in method name. HTTP method names must be tokens
https CA证书问题,注释掉$KYLIN_HOME/tomcat/conf/server.xml里https的部分。
123456
<!--<Connector port="7443" protocol="org.apache.coyote.http11.Http11Protocol" maxThreads="150" SSLEnabled="true" scheme="https" secure="true" keystoreFile="conf/.keystore" keystorePass="changeit" clientAuth="false" sslProtocol="TLS" />-->
停止kylin server然后再启动,处理其他问题类似。
12
$ $KYLIN_HOME/bin/kylin.sh stop$ $KYLIN_HOME/bin/kylin.sh start
问题2:jackson jar包冲突
12
2019-08-13T15:44:18,486 ERROR [localhost-startStop-1] org.springframework.web.context.ContextLoader - Context initialization failedorg.springframework.beans.factory.BeanCreationException: Error creating bean with name 'org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter': Instantiation of bean failed; nested exception is org.springframework.beans.BeanInstantiationException: Failed to instantiate [org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter]: Constructor threw exception; nested exception is java.lang.ClassCastException: com.fasterxml.jackson.datatype.joda.JodaModule cannot be cast to com.fasterxml.jackson.databind.Module
hive的依赖版本:
/home/admin/hive-2.3.5/lib/jackson-datatype-joda-2.4.6.jar
kylin的依赖版本:
/home/admin/kylin-2.6.3/tomcat/webapps/kylin/WEB-INF/lib/jackson-databind-2.9.5.jar
将hive的删除[重命名]。
1
mv $HIVE_HOME/lib/jackson-datatype-joda-2.4.6.jar $HIVE_HOME/lib/jackson-datatype-joda-2.4.6.jarback
使用默认ADMIN/KYLIN[全大写]进行登录
用户名密码见$KYLIN_HOME/tomcat/webapps/kylin/WEB-INF/classes/kylinSecurity.xml。
123456789101112131415161718
<bean class="org.springframework.security.core.userdetails.User" id="adminUser"> <constructor-arg value="ADMIN"/> <constructor-arg value="$2a$10$o3ktIWsGYxXNuUWQiYlZXOW5hWcqyNAFQsSSCSEWoC/BRVMAUjL32"/> <constructor-arg ref="adminAuthorities"/></bean><bean class="org.springframework.security.core.userdetails.User" id="modelerUser"> <constructor-arg value="MODELER"/> <constructor-arg value="$2a$10$Le5ernTeGNIARwMJsY0WaOLioNQdb0QD11DwjeyNqqNRp5NaDo2FG"/> <constructor-arg ref="modelerAuthorities"/></bean><bean class="org.springframework.security.core.userdetails.User" id="analystUser"> <constructor-arg value="ANALYST"/> <constructor-arg value="$2a$10$s4INO3XHjPP5Vm2xH027Ce9QeXWdrfq5pvzuGr9z/lQmHqi0rsbNi"/> <constructor-arg ref="analystAuthorities"/></bean>
问题3:使用MapReduce构建示例Cube报 10020 failed
12345678910
org.apache.kylin.engine.mr.exception.MapReduceException: Exception: java.net.ConnectException: Call From slave1/192.168.100.2 to 0.0.0.0:10020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefusedjava.net.ConnectException: Call From slave1/192.168.100.2 to 0.0.0.0:10020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused at org.apache.kylin.engine.mr.common.MapReduceExecutable.doWork(MapReduceExecutable.java:173) at org.apache.kylin.job.execution.AbstractExecutable.execute(AbstractExecutable.java:167) at org.apache.kylin.job.execution.DefaultChainedExecutable.doWork(DefaultChainedExecutable.java:71) at org.apache.kylin.job.execution.AbstractExecutable.execute(AbstractExecutable.java:167) at org.apache.kylin.job.impl.threadpool.DefaultScheduler$JobRunner.run(DefaultScheduler.java:114) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
10020端口,需要启动MapReduce JobHistory Server。
查看hadoop的mapred-site.xml有无以下配置:
12345678910111213141516
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> <description>MapReduce JobHistory Server IPC host:port</description> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> <description>MapReduceJobHistory Server Web UI host:port</description> </property></configuration>
master节点:
1
$ mr-jobhistory-daemon.sh start historyserver
问题4:spark构建cube点击build后报错
1234567891011121314151617
Caused by: java.lang.NoClassDefFoundError: org/apache/spark/api/java/function/Function at org.apache.kylin.engine.spark.SparkBatchCubingJobBuilder2.<init>(SparkBatchCubingJobBuilder2.java:53) ~[kylin-engine-spark-2.6.3.jar:2.6.3] at org.apache.kylin.engine.spark.SparkBatchCubingEngine2.createBatchCubingJob(SparkBatchCubingEngine2.java:44) ~[kylin-engine-spark-2.6.3.jar:2.6.3] at org.apache.kylin.engine.EngineFactory.createBatchCubingJob(EngineFactory.java:60) ~[kylin-core-job-2.6.3.jar:2.6.3] at org.apache.kylin.rest.service.JobService.submitJobInternal(JobService.java:234) ~[kylin-server-base-2.6.3.jar:2.6.3] at org.apache.kylin.rest.service.JobService.submitJob(JobService.java:202) ~[kylin-server-base-2.6.3.jar:2.6.3] at org.apache.kylin.rest.controller.CubeController.buildInternal(CubeController.java:395) ~[kylin-server-base-2.6.3.jar:2.6.3] ... 77 moreCaused by: java.lang.ClassNotFoundException: org.apache.spark.api.java.function.Function at org.apache.catalina.loader.WebappClassLoaderBase.loadClass(WebappClassLoaderBase.java:1928) ~[catalina.jar:7.0.91] at org.apache.catalina.loader.WebappClassLoaderBase.loadClass(WebappClassLoaderBase.java:1771) ~[catalina.jar:7.0.91] at org.apache.kylin.engine.spark.SparkBatchCubingJobBuilder2.<init>(SparkBatchCubingJobBuilder2.java:53) ~[kylin-engine-spark-2.6.3.jar:2.6.3] at org.apache.kylin.engine.spark.SparkBatchCubingEngine2.createBatchCubingJob(SparkBatchCubingEngine2.java:44) ~[kylin-engine-spark-2.6.3.jar:2.6.3] at org.apache.kylin.engine.EngineFactory.createBatchCubingJob(EngineFactory.java:60) ~[kylin-core-job-2.6.3.jar:2.6.3] at org.apache.kylin.rest.service.JobService.submitJobInternal(JobService.java:234) ~[kylin-server-base-2.6.3.jar:2.6.3] at org.apache.kylin.rest.service.JobService.submitJob(JobService.java:202) ~[kylin-server-base-2.6.3.jar:2.6.3] at org.apache.kylin.rest.controller.CubeController.buildInternal(CubeController.java:395) ~[kylin-server-base-2.6.3.jar:2.6.3]
kylin源码的engine-spark模块,pom.xml中有一些provided的依赖,但是在kylin server启动后并没有在CLASSPATH中找到,所以,简单的方法是把找不到的依赖jar包直接拷贝到$KYLIN_HOME/tomcat/lib下面。
kylin-2.5.2/tomcat/lib/spark-core_2.11-2.1.2.jar(Caused by: java.lang.ClassNotFoundException: org.apache.spark.api.java.function.Function)kylin-2.5.2/tomcat/lib/scala-library-2.11.8.jar(Caused by: java.lang.ClassNotFoundException: scala.Serializable)
12
$ cp $KYLIN_HOME/spark/jars/spark-core_2.11-2.1.2.jar $KYLIN_HOME/tomcat/lib$ cp $KYLIN_HOME/spark/jars/scala-library-2.11.8.jar $KYLIN_HOME/tomcat/lib
重启kylin server生效。
问题5:spark构建cube第二步,找不到HiveConf
在$KYLIN_HOME/bin/kylin.sh中配置HBASE_CLASSPATH_PREFIX。
1234
org.apache.kylin.job.exception.ExecuteException: org.apache.kylin.job.exception.ExecuteException: java.lang.NoClassDefFoundError: org/apache/hadoop/hive/conf/HiveConfCaused by: org.apache.kylin.job.exception.ExecuteException: java.lang.NoClassDefFoundError: org/apache/hadoop/hive/conf/HiveConfCaused by: java.lang.NoClassDefFoundError: org/apache/hadoop/hive/conf/HiveConfCaused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf
配置HBASE_CLASSPATH_PREFIX,用到了环境变量里的tomcat_root和$hive_dependency。
1
export HBASE_CLASSPATH_PREFIX=${tomcat_root}/bin/bootstrap.jar:${tomcat_root}/bin/tomcat-juli.jar:${tomcat_root}/lib/*:$hive_dependency:$HBASE_CLASSPATH_PREFIX
问题6:spark构建cube第三步,The auxService:spark_shuffle does not exist
日志位置:
/home/admin/hadoop-2.8.5/logs/userlogs/application_1565839225073_0008/container_1565839225073_0008_01_000001
123456789101112131415161718192021222324252627282930313233343536
19/08/15 16:52:06 ERROR yarn.YarnAllocator: Failed to launch executor 87 on container container_1565839225073_0008_01_000088org.apache.spark.SparkException: Exception while starting container container_1565839225073_0008_01_000088 on host slave2 at org.apache.spark.deploy.yarn.ExecutorRunnable.startContainer(ExecutorRunnable.scala:126) at org.apache.spark.deploy.yarn.ExecutorRunnable.run(ExecutorRunnable.scala:66) at org.apache.spark.deploy.yarn.YarnAllocator$$anonfun$runAllocatedContainers$1$$anon$1.run(YarnAllocator.scala:520) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)Caused by: org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:spark_shuffle does not exist at sun.reflect.GeneratedConstructorAccessor24.newInstance(Unknown Source) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBImpl.java:168) at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java:106) at org.apache.hadoop.yarn.client.api.impl.NMClientImpl.startContainer(NMClientImpl.java:205) at org.apache.spark.deploy.yarn.ExecutorRunnable.startContainer(ExecutorRunnable.scala:123) ... 5 more19/08/15 16:52:07 WARN cluster.YarnClusterScheduler: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources19/08/15 16:52:09 INFO yarn.ApplicationMaster: Final app status: FAILED, exitCode: 11, (reason: Max number of executor failures (80) reached)19/08/15 16:52:09 ERROR yarn.ApplicationMaster: User class threw exception: java.lang.RuntimeException: error execute org.apache.kylin.engine.spark.SparkFactDistinct. Root cause: nulljava.lang.RuntimeException: error execute org.apache.kylin.engine.spark.SparkFactDistinct. Root cause: null at org.apache.kylin.common.util.AbstractApplication.execute(AbstractApplication.java:42) at org.apache.kylin.common.util.SparkEntry.main(SparkEntry.java:44) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$2.run(ApplicationMaster.scala:636)Caused by: java.lang.InterruptedException at java.util.concurrent.locks.AbstractQueuedSynchronizer.doAcquireSharedInterruptibly(AbstractQueuedSynchronizer.java:998) at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireSharedInterruptibly(AbstractQueuedSynchronizer.java:1304) at scala.concurrent.impl.Promise$DefaultPromise.tryAwait(Promise.scala:202) at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:218) at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:153) at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:619) at org.apache.spark.SparkContext.runJob(SparkContext.scala:1928)
修改hadoop的yarn-site.xml
12345678
<property> <name>yarn.nodemanager.aux-services</name> <value>spark_shuffle,mapreduce_shuffle</value></property><property> <name>yarn.nodemanager.aux-services.spark_shuffle.class</name> <value>org.apache.spark.network.yarn.YarnShuffleService</value></property>
需要引入YarnShuffleService所在的jar包,否则Class org.apache.spark.network.yarn.YarnShuffleService not found。
下载spark源码,编译一下。
1234
$ wget https://github.com/apache/spark/archive/v2.3.2.tar.gz$ tar zxvf v2.3.2.tar.gz$ cd spark-2.3.2/$ ./build/mvn -Pyarn -Phadoop-2.7 -Dhadoop.version=2.7.3 -DskipTests clean package
需要用到的jar包位置在spark-2.3.2/common/network-yarn/target/scala-2.11目录下,spark-2.3.2-yarn-shuffle.jar。
分发到/home/admin/hadoop-2.8.5/share/hadoop/yarn/lib,重启yarn集群。
以上参考Spark官方文档http://spark.apache.org/docs/2.3.2/running-on-yarn.html
123456789
Configuring the External Shuffle ServiceTo start the Spark Shuffle Service on each NodeManager in your YARN cluster, follow these instructions:1. Build Spark with the YARN profile. Skip this step if you are using a pre-packaged distribution.2. Locate the spark-<version>-yarn-shuffle.jar. This should be under $SPARK_HOME/common/network-yarn/target/scala-<version> if you are building Spark yourself, and under yarn if you are using a distribution.3. Add this jar to the classpath of all NodeManagers in your cluster.4. In the yarn-site.xml on each node, add spark_shuffle to yarn.nodemanager.aux-services, then set yarn.nodemanager.aux-services.spark_shuffle.class to org.apache.spark.network.yarn.YarnShuffleService.5. Increase NodeManager's heap size by setting YARN_HEAPSIZE (1000 by default) in etc/hadoop/yarn-env.sh to avoid garbage collection issues during shuffle.6. Restart all NodeManagers in your cluster.
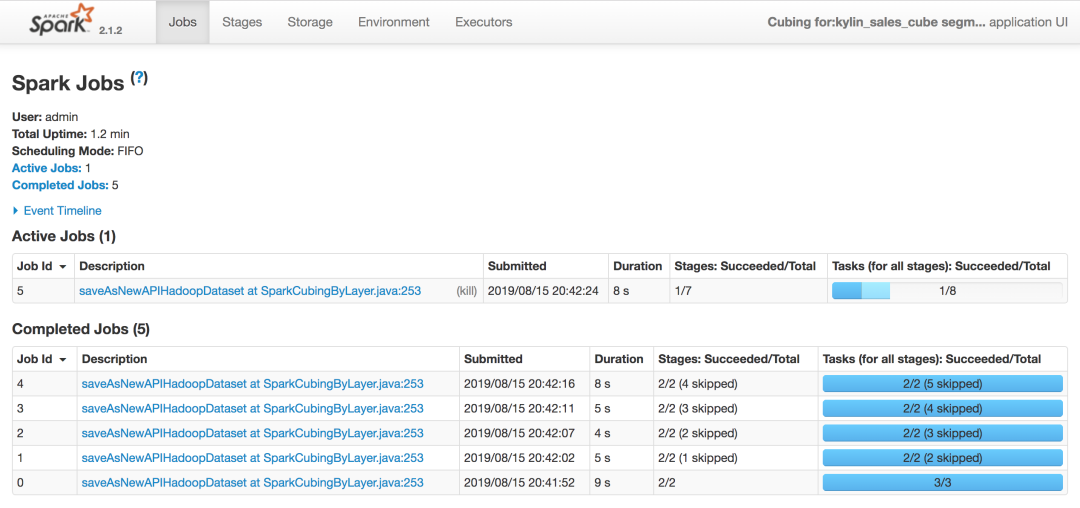
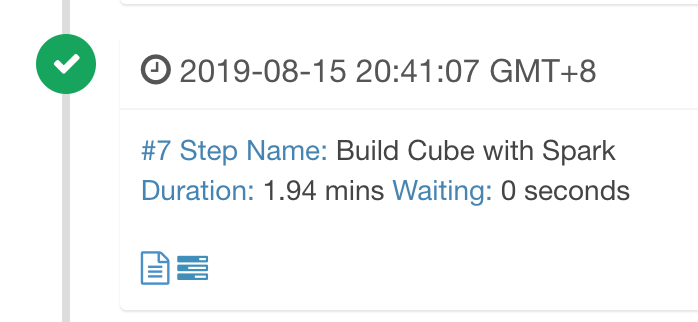
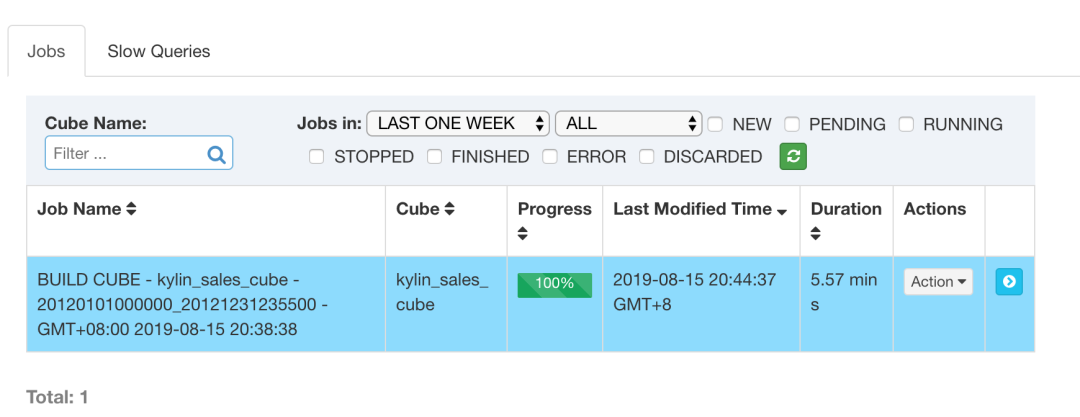
运行截图【spark2.1.2是kylin2.5.2自带的spark版本,上述遇到的问题kylin2.3.6和kylin2.5.2是一致的】
本文作者:知了小巷https://blog.icocoro.me/2019/08/16/1908-kylin-cube-build/
欢迎点赞+收藏+转发朋友圈素质三连

文章不错?点个【在看】吧!** 👇**
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











