
Kubernetes 开发了一个 Elasticsearch 附加组件来实现集群的日志管理。这是一个 Elasticsearch、Fluentd 和 Kibana 的组合。Elasticsearch 是一个搜索引擎,负责存储日志并提供查询接口;Fluentd 负责从 Kubernetes 搜集日志并发送给 Elasticsearch;Kibana 提供了一个 Web GUI,用户可以浏览和搜索存储在 Elasticsearch 中的日志。

部署
Elasticsearch 附加组件本身会作为 Kubernetes 的应用在集群里运行,其 YAML 配置文件可从 https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/fluentd-elasticsearch 获取。
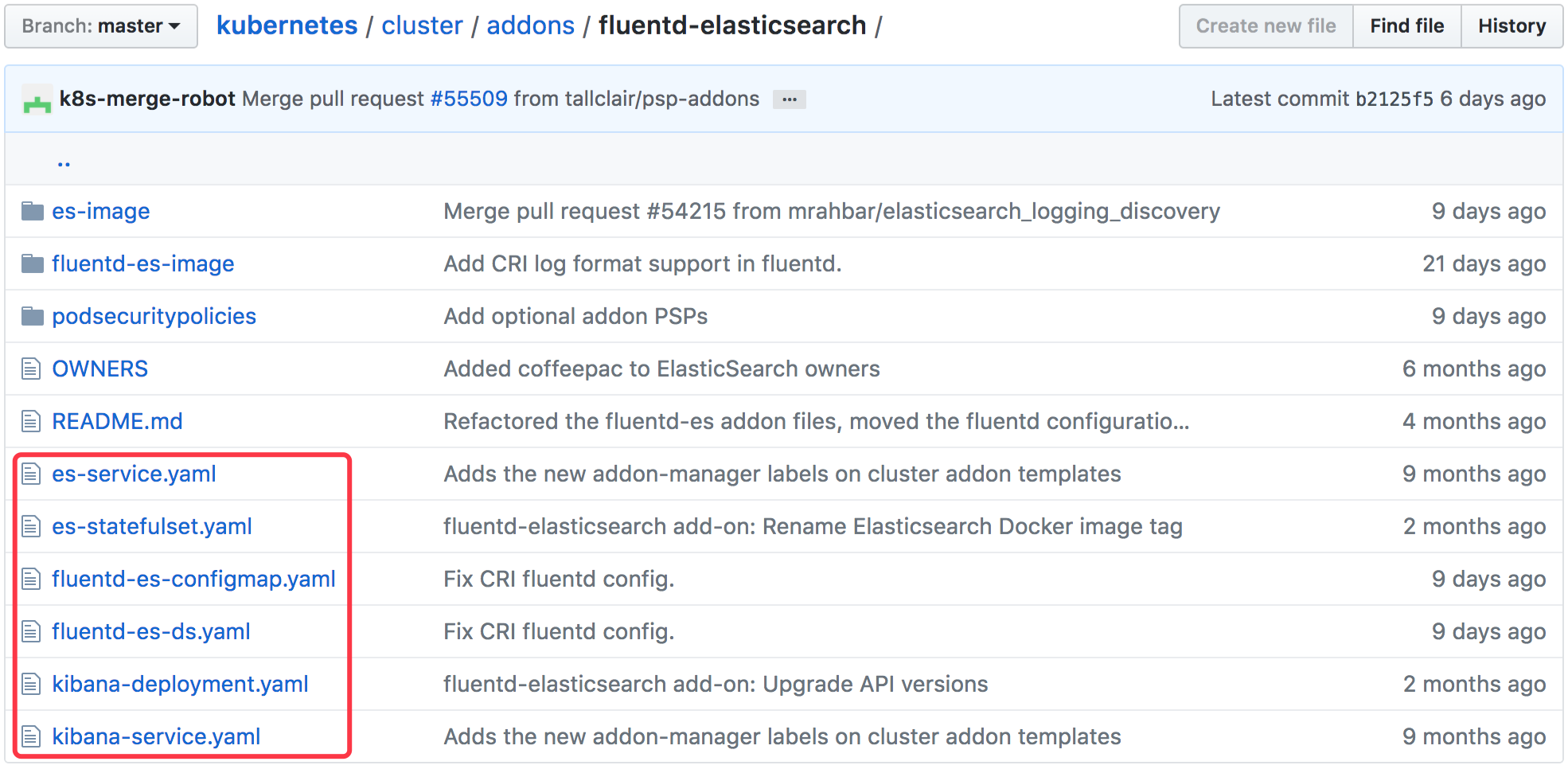
可将这些 YAML 文件下载到本地目录,比如 addons ,通过 kubectl apply -f addons/ 部署。

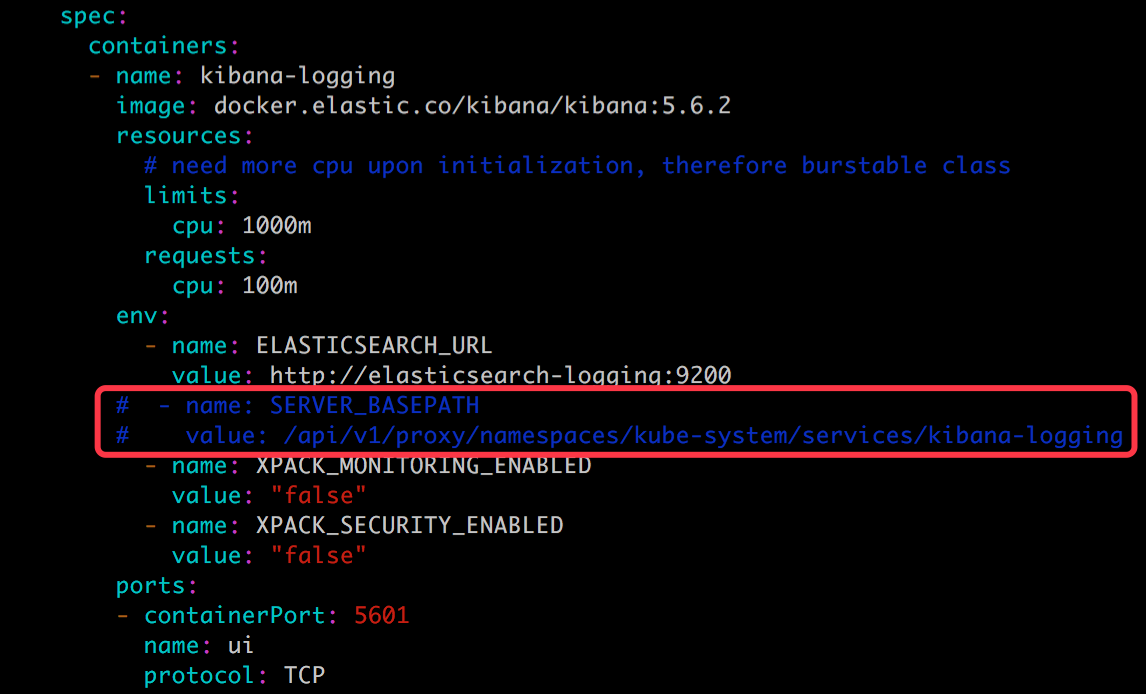
这里有一点需要注意:后面我们会通过 NodePort 访问 Kibana,需要注释掉 kibana-deployment.yaml 中的环境变量 SERVER_BASEPATH,否则无法访问。
所有的资源都部署在 kube-system Namespace 里。
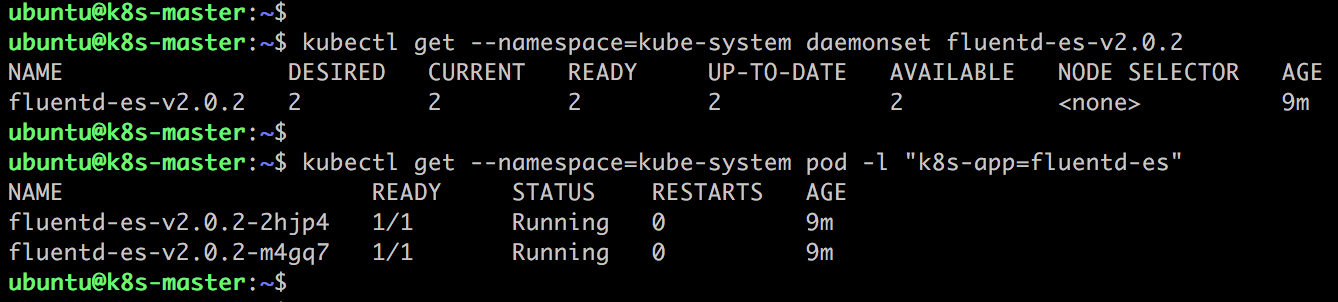
DaemonSet fluentd-es 从每个节点收集日志,然后发送给 Elasticsearch。

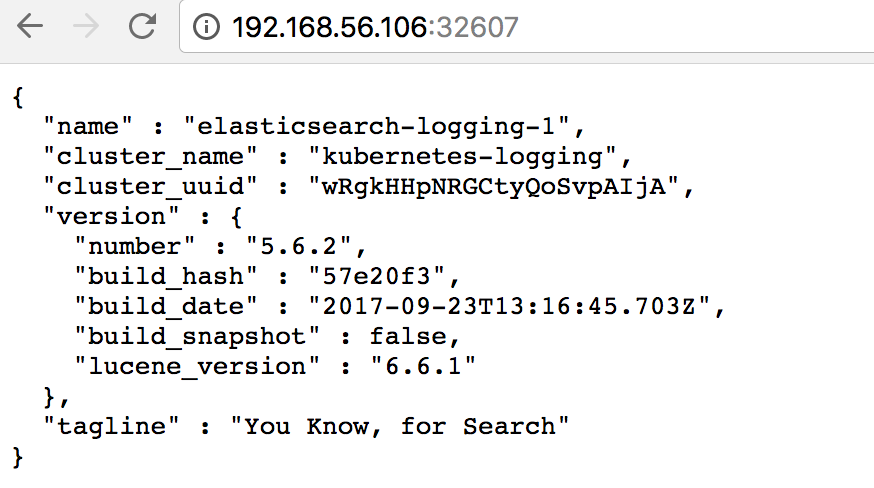
Elasticsearch 以 StatefulSet 资源运行,并通过 Service elasticsearch-logging 对外提供接口。这里已经将 Service 的类型通过 kubectl edit 修改为 NodePort。
可通过 http://192.168.56.106:32607/ 验证 Elasticsearch 已正常工作。
Kibana 以 Deployment 资源运行,用户可通过 Service kibana-logging 访问其 Web GUI。这里已经将 Service 的类型修改为 NodePort。
通过 http://192.168.56.106:30319/ 访问 Kibana。
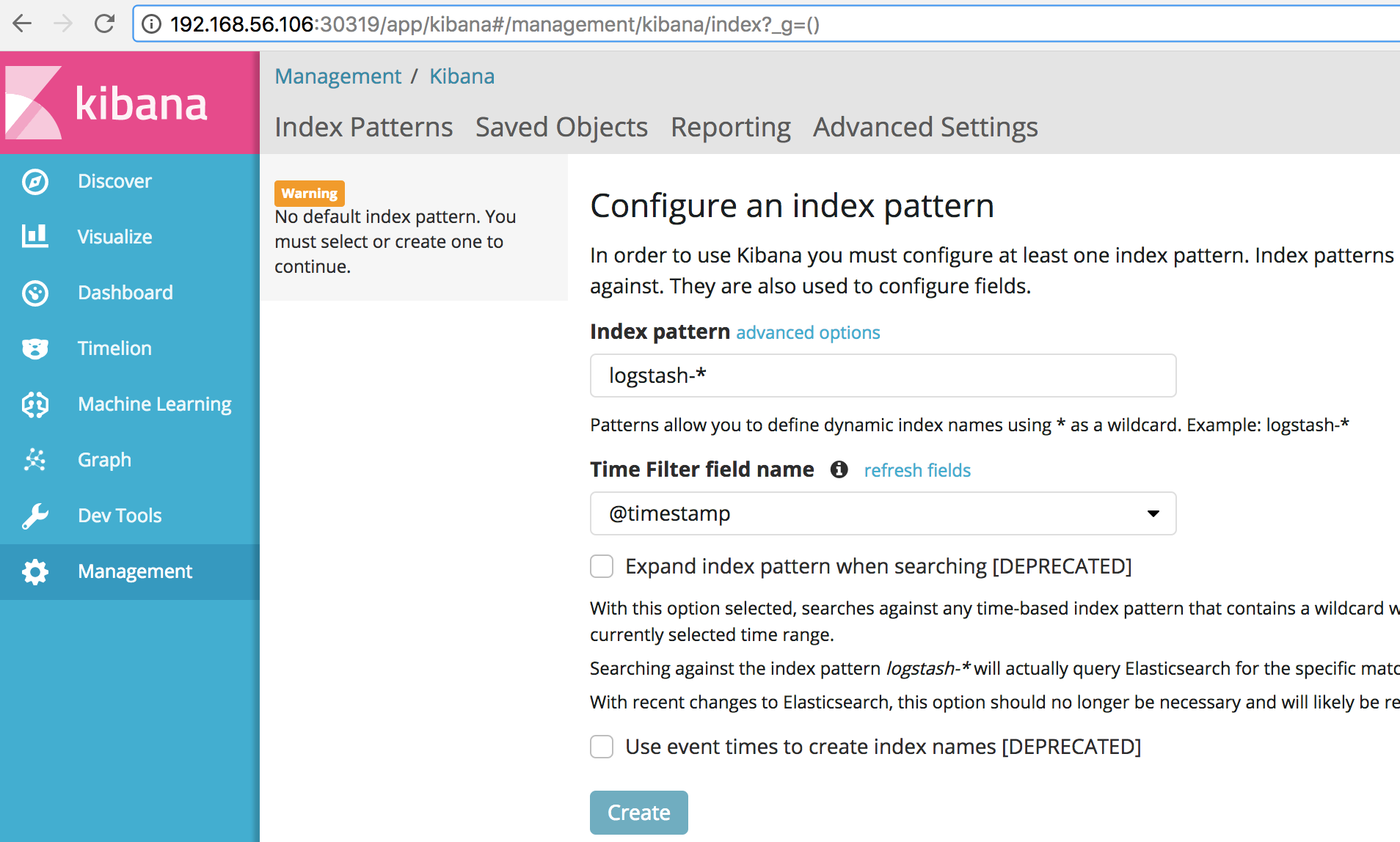
Kibana 会显示 Index Pattern 创建页面。直接点击 Create,Kibana 会自动完成后续配置。
这时,点击左上角的 Discover 就可以查看和检索 Kubernetes 日志了。
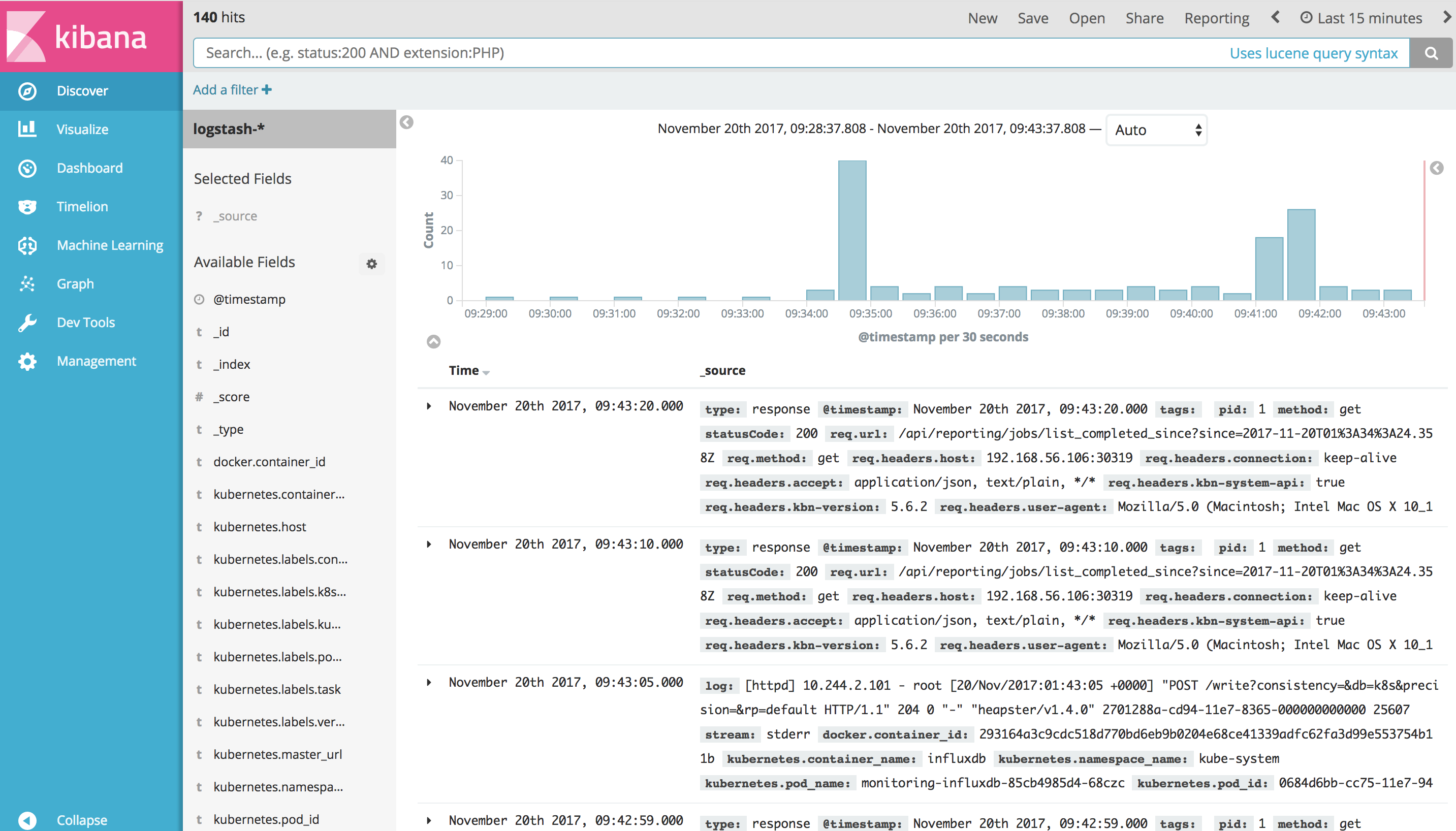
Kubernetes 日志管理系统已经就绪,用户可以根据需要创建自己的 Dashboard,具体方法可参考 Kibana 官方文档。
小结
Elasticsearch 附加组件本身会作为 Kubernetes 的应用在集群里运行,以实现集群的日志管理。它是一个 Elasticsearch、Fluentd 和 Kibana 的组合。
Elasticsearch 是一个搜索引擎,负责存储日志并提供查询接口。
Fluentd 负责从 Kubernetes 搜集日志并发送给 Elasticsearch。
Kibana 提供了一个 Web GUI,用户可以浏览和搜索存储在 Elasticsearch 中的日志。
写在最后
作为 Kubernetes 的实战教程,我们已经到了该收尾的地方。
本教程涵盖了 Kubernetes 最最重要的技术:集群架构、容器化应用部署、Scale Up/Down、滚动更新、监控检查、集群网络、数据管理、监控和日志管理,通过大量的实验探讨了 Kubernetes 的运行机制。
这个教程的目标是使读者能够掌握实施和管理 Kubernetes 的必需技能,能够真正将 Kubernetes 用起来。
为了达到这个目标,每一章都设计了大量的实践操作环节,通过截图和日志帮助读者理解各个技术要点,同时为读者自己实践 Kubernetes 提供详尽的参考。
本教程对读者应该会有两个作用:
初学者可以按照章节顺序系统地学习 Kubernetes,并通过教程中的实验掌握 Kubernetes 的理论知识和实操技能。
有经验的运维人员可以将本教程当做参考材料,在实际工作中有针对性地查看相关知识点。
希望读者们能够通过本教程打下扎实基础,能够从容地运维 Kubernetes ,并结合所在公司和组织的实际需求搭建出实用的容器管理平台。
最后祝大家使用 Kubernetes 愉快!
书籍:
1.《每天5分钟玩转Kubernetes》
https://item.jd.com/26225745440.html
2.《每天5分钟玩转Docker容器技术》
https://item.jd.com/16936307278.html
3.《每天5分钟玩转OpenStack》
https://item.jd.com/12086376.html












