
什么是封装?
在定义类的时候,如果可以直接修改类中的字段那么就可能会出现以下的情况,age可以设置成1000,score可以设置为10000
所以就引出了封装的概念,那么什么是封装呢或者说封装可以实现那些目的
- 封装可以隐藏实现的细节
- 让使用者只能通过实现写好的访问方法来访问这些字段,这样一来我们只需要在这些方法中增加逻辑控制,限制对数据的不合理访问、
- 方便数据检查,有利于于保护对象信息的完整性
- 便于修改,提高代码的可维护性
为了实现良好的封装,需要从两个方面考虑
- 把字段(成员变量)和实现细节隐藏起来,不允许外部直接访问
- 把方法暴露出来,让方法控制这些成员变量进行安全的访问和操作
因此,封装就有两个含义:把该隐藏的隐藏起来,把该暴露的暴露出来。
实现封装的方式:使用访问控制符
java提供了三种访问权限,准确的说还有一种是默认的访问权限,加上它一共四种。
- private 在当前类中可访问
- default 在当前包内和访问
- protected 在当前类和它派生的类中可访问
- public 公众的访问权限,谁都能访问
JAVA中包的概念
Java中用package关键字定义一个包,下面通过几个实验,理解Java中的包的概念和作用。
实验1:先看一个无包的情形
在G盘下新建一个Test.java,如图1:

写下面这些代码
public class PackageTest{
public static void main(String args[]){
System.out.println( "Hello World!");
}
}
然后保存,然后打开控制台(win+R--输入cmd--回车即可),输入 G:--回车 进入G盘,输入 javac PackageTest.java 编译PackageTest.java,具体如下图:

编译成功之后,会发现与PackageTest.java同目录下多了一个文---PackageTest.class,运行的时候执行的就是该文件,如下图:
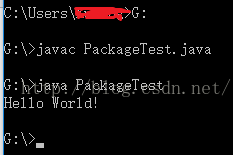
运行这个程序,在控制台输入 java PackageTest ,运行结果如下:
这是没有包的情形,下面看看有包的情形。
实验2:
将实验1中的G盘下的PackageTest.class文件删除,打开PackageTest.java,在前面加上这些内容:
package p1.p2.p3;
再在控制台输入javac PackageTest.java编译程序,如果没有其他提示证明编译成功,编译结果如下:

同样可以查看G盘下又多了一个PackageTest.class文件,用同样的方法运行程序,在控制台输入java PackageTest,结果是这样的:

意思就是找不到PackageTest这个类,为什么呢?因为在PackageTest.java中定义了包。如何解决这个问题呢?
接下来,我们在G盘下新建一个文件夹p1,在p1下新建一个文件夹p2,在p2下新建一个文件p3,再把G盘下的PackageTest.class文件放到文件夹p3中,如下图:

再在控制台运行这个程序,输入java PackageTest,结果如下:

还是找不到这个类,为什么呢?因为这个类的名字不是PackageTest了,而是p1.p2.p3.PackageTest了,所以正确运行这个程序的方法是:
在控制台输入 java p1.p2.p3.PackageTest 就能得到想要的结果了:

从上面的实验可以看出:
1.包对.java源文件没有作用,只对.class字节码文件起作用。
2.包相当于一个字节码的相对路径。例如上例中PackageTest.class的绝对路径就是:
G:\p1\p2\p3
引入包可以防止文件名之间的冲突(例如一个公司的网站域名为:www.abc.def.cn,则这个公司的程序员可以将所有的包设置为cn.def.abc)。
package
C/C++ 的 #include会把所包含的内容在编译时添加到程序文件中,而java的import则不同。
这里我们先了解一下Java 的 package 到底有何用处。
package名称就像是我们的姓,而class名称就像是我们的名字 。package和package的附属关系用”.”来连接,这就像是复姓。比如说 java.lang.String就是复姓 java.lang,名字為 String 的类别;java.io.InputStream 则是复姓 java.io,名字為 InputStream的类别。
Java 会使用 package 这种机制的原因也非常明显,就像我们取姓名一样 ,光是一间学校的同一届同学中,就有可能会出现不少同名的同学,如果不取姓的话,那学校在处理学生资料,或是同学彼此之间的称呼,就会发生很大的困扰。相同的,全世界的 Java 类数量,恐怕比日本人还多,如果类别不使用package名称,那在用到相同名称的不同类时, 就会产生极大的困扰。所以package这种方式让极大降低了类之间的命名冲突。
Java 的package名称我们可以自己取,不像人的姓没有太大的选择 ( 所以出现很多同名同姓的情况 ),如果依照 Sun 的规范来取套件名称,那理论上不同人所取的套件名称不会相同 ( 需要的话请参阅 “命名惯例” 的相关文章 ),也就不会发生名称冲突的情况。
可是现在问题来了,因為很多package的名称非常的长,在编程时,要使用一个类要将多个包名.类名完全写出,会让代码变得冗长,减低了简洁度。例如
java.io.InputStream is = java.lang.System.in; java.io.InputStreamReader isr= new java.io.InputStreamReader(is); java.io.BufferedReader br = new java.io.BufferedReader(isr);
- 1
- 2
- 3
显得非常麻烦,于是Sun公司就引入了import。
import
import就是在java文件开头的地方,先说明会用到那些类别。
接着我们就能在代码中只用类名指定某个类,也就是只称呼名字,不称呼他的姓。
首先,在程序开头写:
import java.lang.System;
import java.io.InputStream;
import java.io.InputStreamReader; import java.io.BufferedReader;
- 1
- 2
- 3
- 4
于是我们就可以在程序中这样写到:
InputStream = System.in;
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr);
- 1
- 2
- 3
一个java文件就像一个大房间,我们在门口写着在房间里面的class的姓和名字,所以在房间里面提到某个class就直接用他的名字就可以。例如:
System 就是指 java.lang.System,而 InputStream 就是指 java.io.InputStream。
但是如果一个java文件里面有多个同个“姓”,即包名相同的类(例如上面的InputStream,InputStreamReader,BufferedReader都是java.io中的类),我们一一写出显得比较繁杂,所以Sun就让我们可以使用
import java.lang.*;
import java.io.*;
- 1
- 2
表示文件里面说到的类不是java.lang包的就是java.io包的。编译器会帮我们选择与类名对应的包。
那我们可不可以再懒一点直接写成下面声明呢?
import java.*;
- 1
历史告诉我们,这样是不行的。因為那些类别是姓 java.io 而不是姓 java。就像姓『诸葛』的人应该不会喜欢你称他為『诸』 先生吧。这样写的话只会将java包下的类声明,而不不会声明子包的任何类。
这里注意,java.lang包里面的类实在是太常太常太常用到了,几乎没有类不用它的, 所以不管你有没有写 import java.lang,编译器都会自动帮你补上,也就是说编译器只要看到没有姓的类别,它就会自动去lang包里面查找。所以我们就不用特别去 import java.lang了。
一开始说 import 跟 #include 不同,是因为import 的功能到此為止,它不像#include 一样,会将其他java文件的内容载入进来。import 只是让编译器编译这个java文件时把没有姓的类别加上姓,并不会把别的文件程序写进来。你开心的话可以不使用import,只要在用到类别的时候,用它的全部姓名来称呼它就行了(就像例子一开始那样),这样跟使用import功能完全一样。
import的两种导入声明
- 单类型导入(single-type-import)
(例:import java.util.ArrayList; ) - 按需类型导入(type-import-on-demand)
(例:import java.util.*;)
有如下属性:
java以这样两种方式导入包中的任何一个public的类和接口(只有public类和接口才能被导入)
上面说到导入声明仅导入声明目录下面的类而不导入子包,这也是为什么称它们为类型导入声明的原因。
导入的类或接口的简名(simple name)具有编译单元作用域。这表示该类型简名可以在导入语句所在的编译单元的任何地方使用.这并不意味着你可以使用该类型所有成员的简名,而只能使用类型自身的简名。
例如: java.lang包中的public类都是自动导入的,包括Math和System类.但是,你不能使用它们的成员的简名PI()和gc(),而必须使用Math.PI()和System.gc().你不需要键入的是java.lang.Math.PI()和java.lang.System.gc()。程序员有时会导入当前包或java.lang包,这是不需要的,因为当前包的成员本身就在作用域内,而java.lang包是自动导入的。java编译器会忽略这些冗余导入声明(redundant import declarations)。即使像这样
import java.util.ArrayList;
import java.util.*;
多次导入,也可编译通过。编译器会将冗余导入声明忽略.
static import静态导入
在Java程序中,是不允许定义独立的函数和常量的。即什么属性或者方法的使用必须依附于什么东西,例如使用类或接口作为挂靠单位才行(在类里可以挂靠各种成员,而接口里则只能挂靠常量)。
如果想要直接在程序里面不写出其他类或接口的成员的挂靠单元,有一种变通的做法 :
将所有的常量都定义到一个接口里面,然后让需要这些常量的类实现这个接口(这样的接口有一个专门的名称,叫(“Constant Interface”)。这个方法可以工作。但是,因为这样一来,就可以从“一个类实现了哪个接口”推断出“这个类需要使用哪些常量”,有“会暴露实现细节”的问题。
于是J2SE 1.5里引入了“Static Import”机制,借助这一机制,可以用略掉所在的类或接口名的方式,来使用静态成员。static import和import其中一个不一致的地方就是static import导入的是静态成员,而import导入的是类或接口类型。
如下是一个有静态变量和静态方法的类
package com.assignment.test;
public class staticFieldsClass {
static int staticNoPublicField = 0; public static int staticField = 1; public static void staticFunction(){} }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
平时我们使用这些静态成员是用类名.静态成员的形式使用,即staticFieldsClass.staticField或者staticFieldsClass.staticFunction()。
现在用static import的方式:
//**精准导入**
//直接导入具体的静态变量、常量、方法方法,注意导入方法直接写方法名不需要括号。
import static com.assignment.test.StaticFieldsClass.staticField;
import static com.assignment.test.StaticFieldsClass.staticFunction;
//或者使用如下形式: //**按需导入**不必逐一指出静态成员名称的导入方式 //import static com.assignment.test.StaticFieldsClass.*; public class StaticTest { public static void main(String[] args) { //这里直接写静态成员而不需要通过类名调用 System.out.println(staticField); staticFunction(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
这里有几个问题需要弄清楚:
Static Import无权改变无法使用本来就不能使用的静态成员的约束,上面例子的StaticTest和staticFieldsClass不是在同一个包下,所以StaticTest只能访问到staticFieldsClass中public的变量。使用了Static Import也同样如此。
导入的静态成员和本地的静态成员名字相同起了冲突,这种情况下的处理规则,是“本地优先。
不同的类(接口)可以包括名称相同的静态成员。例如在进行Static Import的时候,出现了“两个导入语句导入同名的静态成员”的情况。在这种时候,J2SE 1.5会这样来加以处理:
- 如果两个语句都是精确导入的形式,或者都是按需导入的形式,那么会造成编译错误。
- 如果一个语句采用精确导入的形式,一个采用按需导入的形式,那么采用精确导入的形式的一个有效。
大家都这么聪明上面的几个特性我就不写例子了。
static import这么叼那它有什么负面影响吗?
答案是肯定的,去掉静态成员前面的类型名,固然有助于在频繁调用时显得简洁,但是同时也失去了关于“这个东西在哪里定义”的提示信息,理解或维护代码就呵呵了。
但是如果导入的来源很著名(比如java.lang.Math),这个问题就不那么严重了。
按需导入机制
使用按需导入声明是否会降低Java代码的执行效率?
绝对不会!
一、import的按需导入
import java.util.*;
public class NeedImportTest {
public static void main(String[] args) { ArrayList tList = new ArrayList(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
编译之后的class文件 :
//import java.util.*被替换成import java.util.ArrayList
//即按需导入编译过程会替换成单类型导入。
import java.util.ArrayList;
public class NeedImportTest {
public static void main(String[] args) { new ArrayList(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
二、static import的按需导入
import static com.assignment.test.StaticFieldsClass.*;
public class StaticNeedImportTest {
public static void main(String[] args) { System.out.println(staticField); staticFunction(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
上面StaticNeedImportTest 类编译之后 :
//可以看出 :
//1、static import的精准导入以及按需导入编译之后都会变成import的单类型导入
import com.assignment.test.StaticFieldsClass;
public class StaticNeedImportTest {
public static void main(String[] args) { //2、编译之后“打回原形”,使用原来的方法调用静态成员 System.out.println(StaticFieldsClass.staticField); StaticFieldsClass.staticFunction(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
附加
这是否意味着你总是可以使用按需导入声明?
是,也不是!
在类似Demo的非正式开发中使用按需导入声明显得很有用。
然而,有这四个理由让你可以放弃这种声明:
- 编译速度:在一个很大的项目中,它们会极大的影响编译速度.但在小型项目中使用在编译时间上可以忽略不计。
- 命名冲突:解决避免命名冲突问题的答案就是使用全名。而按需导入恰恰就是使用导入声明初衷的否定。
- 说明问题:毕竟高级语言的代码是给人看的,按需导入看不出使用到的具体类型。
- 无名包问题:如果在编译单元的顶部没有包声明,Java编译器首选会从无名包中搜索一个类型,然后才是按需类型声明。如果有命名冲突就会产生问题。
Sun的工程师一般不使用按需类型导入声明.这你可以在他们的代码中找到:
在java.util.Properties类中的导入声明:
import java.io.IOException;
import java.io.PrintStream;
import java.io.PrintWriter; import java.io.InputStream; import java.io.OutputStream; import java.io.Reader; import java.io.Writer; import java.io.OutputStreamWriter; import java.io.BufferedWriter; import java.security.AccessController; import java.security.PrivilegedAction;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
可以看到他们用单类型导入详细的列出了需要的java.io包中的具体类型。













