一.分区策略
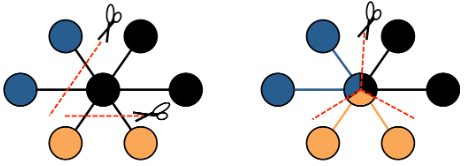
GraphX采用顶点分割的方式进行分布式图分区。GraphX不会沿着边划分图形,而是沿着顶点划分图形,这可以减少通信和存储的开销。从逻辑上讲,这对应于为机器分配边并允许顶点跨越多台机器。分配边的方法取决于分区策略PartitionStrategy并且对各种启发式方法进行了一些折中。用户可以使用Graph.partitionBy运算符重新划分图【可以使用不同分区策略】。默认的分区策略是使用图形构造中提供的边的初始分区。但是,用户可以轻松切换到GraphX中包含的2D分区或其他启发式方法。
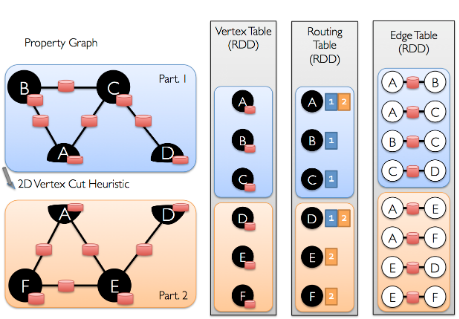
一旦对边进行了划分,高效图并行计算的关键挑战就是将顶点属性和边有效结合。由于现实世界中的图通常具有比顶点更多的边,因此我们将顶点属性移到边上。由于并非所有分区都包含与所有顶点相邻的边,因此我们在内部维护一个路由表,该路由表在实现诸如triplets操作所需要的连接时,标示在哪里广播顶点aggregateMessages。
二.测试数据
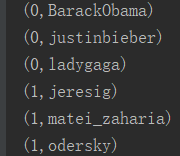
1.users.txt

2.followers.txt
3.数据可视化
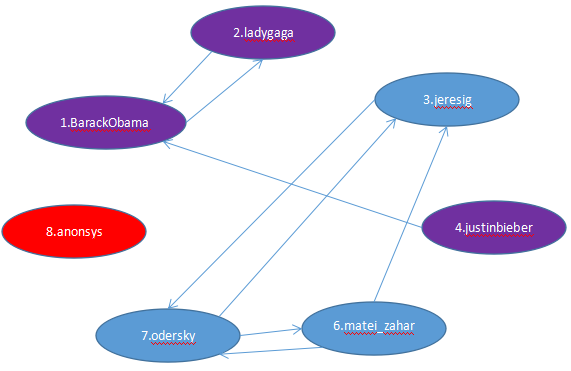
三.PageRank网页排名
1.简介
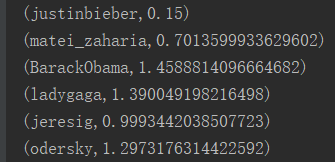
使用PageRank测量图中每个顶点的重要性,假设从边u到v表示的认可度x。例如,如果一个Twitter用户被许多其他用户关注,则该用户将获得很高的排名。GraphX带有PageRank的静态和动态实现,作为PageRank对象上的方法。静态PageRant运行固定的迭代次数,而动态PageRank运行直到排名收敛【变化小于指定的阈值】。GraphOps运行直接方法调用这些算法。
2.代码实现
1 package graphx
2
3 import org.apache.log4j.{Level, Logger}
4 import org.apache.spark.graphx.GraphLoader
5 import org.apache.spark.sql.SparkSession
6
7 /**
8 * Created by Administrator on 2019/11/27.
9 */
10 object PageRank {
11 Logger.getLogger("org").setLevel(Level.WARN)
12 def main(args: Array[String]) {
13 val spark = SparkSession.builder()
14 .master("local[2]")
15 .appName(s"${this.getClass.getSimpleName}")
16 .getOrCreate()
17 val sc = spark.sparkContext
18 val graph = GraphLoader.edgeListFile(sc, "D:\\software\\spark-2.4.4\\data\\graphx\\followers.txt")
19 // 调用PageRank图计算算法
20 val ranks = graph.pageRank(0.0001).vertices
21 // join
22 val users = sc.textFile("D:\\software\\spark-2.4.4\\data\\graphx\\users.txt").map(line => {
23 val fields = line.split(",")
24 (fields(0).toLong, fields(1))
25 })
26 // join
27 val ranksByUsername = users.join(ranks).map{
28 case (id, (username, rank)) => (username, rank)
29 }
30 // print
31 ranksByUsername.foreach(println)
32 }
33 }
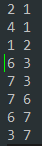
3.执行结果
四.ConnectedComponents连通体算法
1.简介
连通体算法实现把图划分为多个子图【不进行节点切分】,清除孤岛子图【只要一个节点的子图】。其使用子图中编号最小的顶点ID标记子图。
2.代码实现
1 package graphx
2
3 import org.apache.log4j.{Level, Logger}
4 import org.apache.spark.graphx.GraphLoader
5 import org.apache.spark.sql.SparkSession
6
7 /**
8 * Created by Administrator on 2019/11/27.
9 */
10 object ConnectedComponents {
11 Logger.getLogger("org").setLevel(Level.WARN)
12 def main(args: Array[String]) {
13 val spark = SparkSession.builder()
14 .master("local[2]")
15 .appName(s"${this.getClass.getSimpleName}")
16 .getOrCreate()
17 val sc = spark.sparkContext
18 val graph = GraphLoader.edgeListFile(sc, "D:\\software\\spark-2.4.4\\data\\graphx\\followers.txt")
19 // 调用connectedComponents连通体算法
20 val cc = graph.connectedComponents().vertices
21 // join
22 val users = sc.textFile("D:\\software\\spark-2.4.4\\data\\graphx\\users.txt").map(line => {
23 val fields = line.split(",")
24 (fields(0).toLong, fields(1))
25 })
26 // join
27 val ranksByUsername = users.join(cc).map {
28 case (id, (username, rank)) => (username, rank)
29 }
30 val count = ranksByUsername.count().toInt
31 // print
32 ranksByUsername.map(_.swap).takeOrdered(count).foreach(println)
33 }
34 }
3.执行结果

五.TriangleCount三角计数算法
1.简介
当顶点有两个相邻的顶点且它们之间存在边时,该顶点是三角形的一部分。GraphX在TriangleCount对象中实现三角计数算法,该算法通过确定经过每个顶点的三角形的数量,从而提供聚类的度量。注意,TriangleCount要求边定义必须为规范方向【srcId < dstId】,并且必须使用Graph.partitionBy对图进行分区。
2.代码实现
1 package graphx
2
3 import org.apache.log4j.{Level, Logger}
4 import org.apache.spark.graphx.{PartitionStrategy, GraphLoader}
5 import org.apache.spark.sql.SparkSession
6
7 /**
8 * Created by Administrator on 2019/11/27.
9 */
10 object TriangleCount {
11 Logger.getLogger("org").setLevel(Level.WARN)
12 def main(args: Array[String]) {
13 val spark = SparkSession.builder()
14 .master("local[2]")
15 .appName(s"${this.getClass.getSimpleName}")
16 .getOrCreate()
17 val sc = spark.sparkContext
18 val graph = GraphLoader.edgeListFile(sc, "D:\\software\\spark-2.4.4\\data\\graphx\\followers.txt", true)
19 .partitionBy(PartitionStrategy.RandomVertexCut)
20
21 // 调用triangleCount三角计数算法
22 val triCounts = graph.triangleCount().vertices
23 // map
24 val users = sc.textFile("D:\\software\\spark-2.4.4\\data\\graphx\\users.txt").map(line => {
25 val fields = line.split(",")
26 (fields(0).toLong, fields(1))
27 })
28 // join
29 val triCountByUsername = users.join(triCounts).map { case (id, (username, tc)) =>
30 (username, tc)
31 }
32 val count = triCountByUsername.count().toInt
33 // print
34 triCountByUsername.map(_.swap).takeOrdered(count).foreach(println)
35 }
36 }
3.执行结果