
Pandas统计分析基础
Pandas(Python Data Analysis Library)是基于NumPy的数据分析模块,它提供了大量标准数据模型和高效操作大型数据集所需的工具,可以说Pandas是使得Python能够成为高效且强大的数据分析环境的重要因素之一。
导入方式:import pandas as pd
Pandas有三种数据结构:Series、DataFrame和Panel。Series类似于一维数组;DataFrame是类似表格的二维数组;Panel可以视为Excel的多表单Shee
一、Pandas中的数据结构
1.Series
Series 是一种一维数组对象,包含了一个值序列,并且包含了数据标签,称为索引(index),可通过索引来访问数组中的数据。
Series的创建:
pd.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False) 通过列表创建Series:
import pandas as pd
obj = pd.Series([1, -2, 3, -4]) #仅有一个数组构成
print(obj) 
创建Series时指定索引:
i = ["a", "c", "d", "a"]
v = [2, 4, 5, 7]
t = pd.Series(v, index = i, name = "col")
print(t) 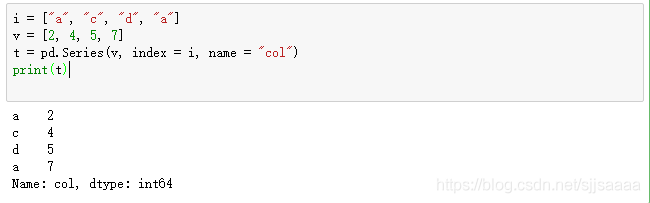
尽管创建Series指定了index参数,实际Pandas还是有隐藏的index位置信息的。所以Series有两套描述某条数据的手段:位置和标签.
Series位置和标签的使用:

通过字典创建:
如果数据被存放在一个Python字典中,也可以直接通过这个字典来创建Series。
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
obj3 = pd.Series(sdata)
print(obj3) 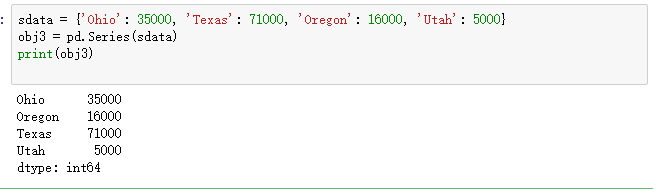
键值和指定的索引不匹配:
sdata = {"a" : 100, "b" : 200, "e" : 300}
letter = ["a", "b","c" , "e" ]
obj = pd.Series(sdata, index = letter)
print(obj) 
不同索引数据的自动对齐:
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
obj1 = pd.Series(sdata)
states = ['California', 'Ohio', 'Oregon', 'Texas']
obj2 = pd.Series(sdata, index = states)
print(obj1+obj2) 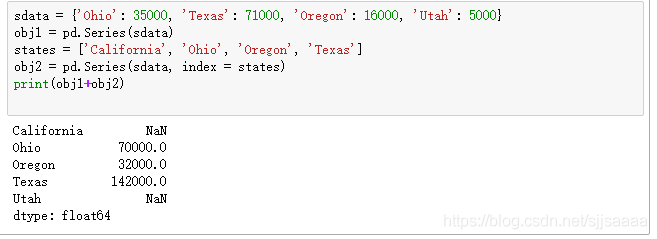
Series索引的修改:
obj = pd.Series([4,7,-3,2])
obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
print(obj) 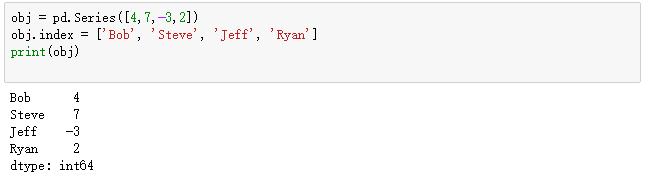
2.DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。
DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。 DataFrame的创建:
格式:
pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False) 创建:
data = {
'name':['张三', '李四', '王五', '小明'],
'sex':['female', 'female', 'male', 'male'],
'year':[2001, 2001, 2003, 2002],
'city':['北京', '上海', '广州', '北京']
}
df = pd.DataFrame(data)
print(df) 
DataFrame的索引: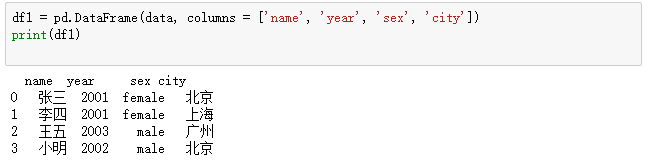
DataFrame创建时的空缺值:
df2 = pd.DataFrame(data, columns = ['name', 'year', 'sex', 'city','address'])
print(df2) 
DataFrame构造函数的columns函数给出列的名字,index给出label标签。
DataFrame创建时指定列名:
df3 = pd.DataFrame(data, columns = ['name', 'sex', 'year', 'city'], index = ['a', 'b', 'c', 'd'])
print(df3) 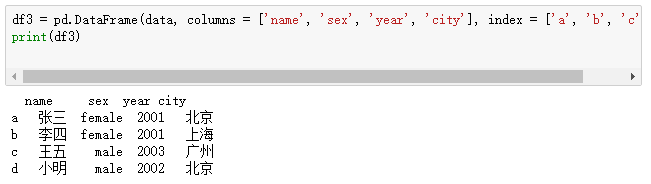
DataFrame的属性:
3.索引对象
Pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。构建Series或 DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index。
显示DataFrame的索引和列:
print(df)
print(df.index)
print(df.columns) 
每个索引都有一些方法和属性,它们可用于设置逻辑并回答有关该索引所包含的数据的常见问题。Index的常用方法和属性:
4.查看DataFrame的常用属性
DataFrame的基础属性有values、index、columns、dtypes、ndim和shape,分别可以获取DataFrame的元素、索引、列名、类型、维度和形状。

二、Pandas索引操作
1.重新索引
索引对象是无法修改的,因此,重新索引是指对索引重新排序而不是重新命名,如果某个索引值不存在的话,会引入缺失值。
对于重建索引引入的缺失值,可以利用fill_value参数填充。
obj = pd.Series([7.2,-4.3,4.5,3.6],index=list("badc"))
obj
obj.reindex(list("abcde")) 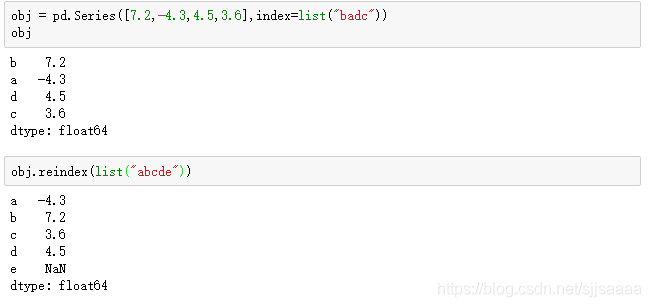
重建索引时填充缺失值。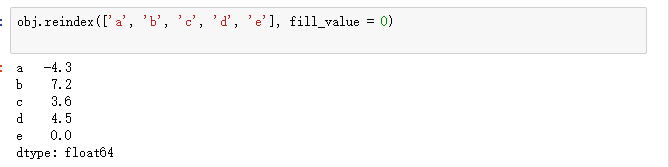
缺失值的前向填充:
缺失值的后向填充:
DataFrame数据:
df4 = pd.DataFrame(np.arange(9).reshape(3,3),
index = ['a','c','d'],columns = ['one','two','four'])
print(df4) 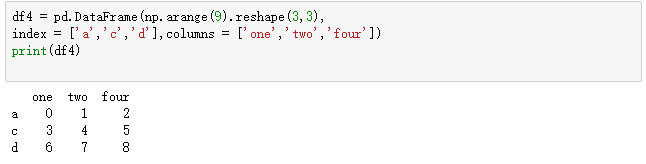
reindex操作: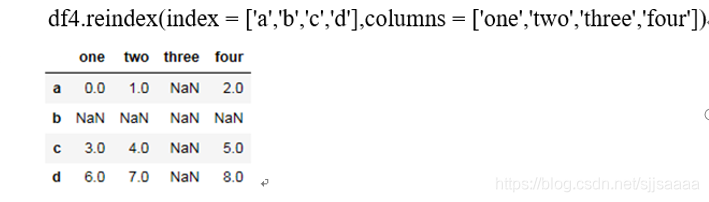
传入fill_value = n用n代替缺失值。

reindex函数参数: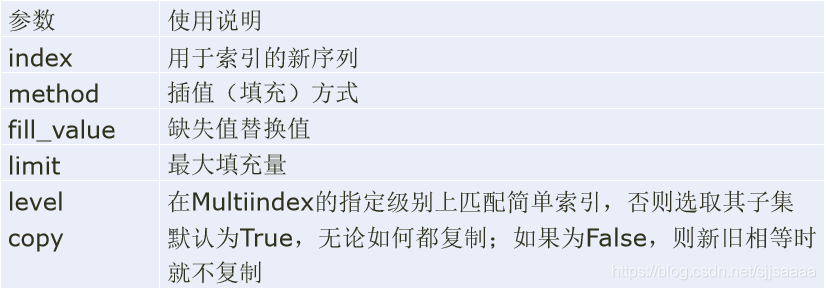
2.更换索引
如果不希望使用默认的行索引,则可以在创建的时候通过Index参数来设置。
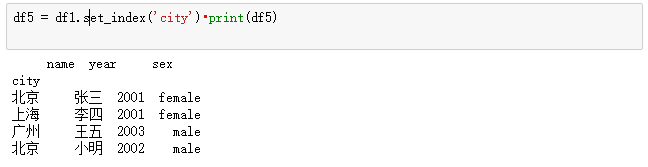
在DataFrame数据中,如果希望将列数据作为索引,则可以通过set_index方法来实现。
重建索引:
三、DataFrame的数据查询与编辑
1.DataFrame数据的查询
在数据分析中,选取需要的数据进行分析处理是最基本操作。在Pandas中需要通过索引完成数据的选取。
选取列:
通过列索引或以属性的方式可以单独获取DataFrame的列数据,返回的数据类型为Series。
选取行:
通过切片形式可以选取一行或多行数据

选取通过DataFrame提供的head和tail方法可以得到多行数据,但是用这两种方法得到的数据都是从开始或者末尾获取连续的数据, 而利用sample可以随机抽取数据并显示。
head() #默认获取前5行
head(n)#获取前n行
tail()#默认获取后5行
head(n)#获取后n行
sample(n)#随机抽取n行显示
选取行和列:
DataFrame.loc(行索引名称或条件,列索引名称)
DataFrame.iloc(行索引位置,列索引位置)
利用iloc选取行和列:
布尔选择
可以对DataFrame中的数据进行布尔方式选择 data[data["数据列名"]==20]
### [](https://blog.csdn.net/sjjsaaaa/article/details/109604951)DataFrame数据的编辑
**增加数据:**

增加列时,只需为要增加的列赋值即可创建一个新的列。

**删除数据:**
删除数据直接用drop方法,通过axis参数确定是删除的是行还是列。默认数据删除不修改原数据,需要在原数据删除行列需要设置参数inplace = True。

删除列:

**修改数据:**
修改数据时直接对选择的数据赋值即可。
需要注意的是,数据修改是直接对DataFrame数据修改,操作无法撤销,因此更改数据时要做好数据备份。
[](https://blog.csdn.net/sjjsaaaa/article/details/109604951)四、Pandas数据运算
------------------------------------------------------------------------
### [](https://blog.csdn.net/sjjsaaaa/article/details/109604951)1.算术运算
Pandas的数据对象在进行算术运算时,如果有相同索引则进行算术运算,如果没有,则会自动进行数据对齐,但会引入缺失值。
**series相加:**




### [](https://blog.csdn.net/sjjsaaaa/article/details/109604951)2.函数应用和映射
已定义好的函数可以通过以下三种方法应用到数据:
1. map函数:将函数套用到Series的每个元素中;
2. apply函数,将函数套用到DataFrame的行或列上,行与列通过axis参数设置;
3. applymap函数,将函数套用到DataFrame的每个元素上。
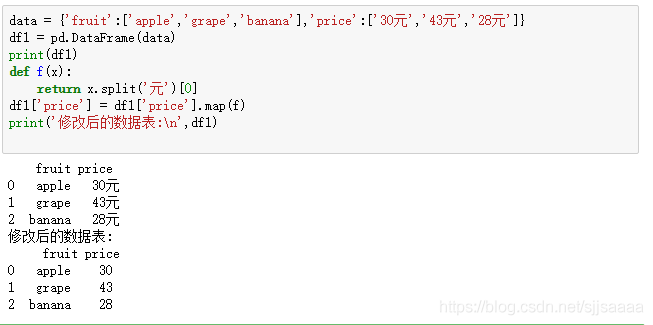
将水果价格表中的“元”去掉。
data = {'fruit':['apple','grape','banana'],'price':['30元','43元','28元']} df1 = pd.DataFrame(data) print(df1) def f(x): return x.split('元')[0] df1['price'] = df1['price'].map(f) print('修改后的数据表:\n',df1)
**apply函数的使用方法:**

**applymap函数的用法:**

### [](https://blog.csdn.net/sjjsaaaa/article/details/109604951)3.排序
sort\_index方法:对索引进行排序,默认为升序,降序排序时加参数 ascending=False。
sort\_values方法:对数值进行排序。by参数设置待排序的列名

### [](https://blog.csdn.net/sjjsaaaa/article/details/109604951)4.汇总与统计
**数据汇总:**
在DataFrame中,可以通过sum方法对每列进行求和汇总,与Excel中的sum函数类似。如果设置axis = 1指定轴方向,可以实现按行汇总。

**数据描述与统计**
利用describe方法会对每个数值型的列数据进行统计
df2.describe()
**Pandas中常用的描述性统计量**

对于类别型特征的描述性统计,可以使用频数统计表。Pandas库中通过unique方法获取不重复的数组,利用value\_counts方法实现频数统计。
[](https://blog.csdn.net/sjjsaaaa/article/details/109604951)五、数据分组与聚合
---------------------------------------------------------------------
### [](https://blog.csdn.net/sjjsaaaa/article/details/109604951)1.数据分组
**groupby方法**
groupby方法可以根据索引或字段对数据进行分组。
格式为:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
groupby方法的参数及其说明:



**按列名分组**
DataFrame数据的列索引名可以作为分组键,但需要注意的是用于分组的对象必须是DataFrame数据本身,否则搜索不到索引名称会报错。

**按列表或元组分组**
分组键还可以是长度和DataFrame行数相同的列表或元组,相当于将列表或元组看做DataFrame的一列,然后将其分组。

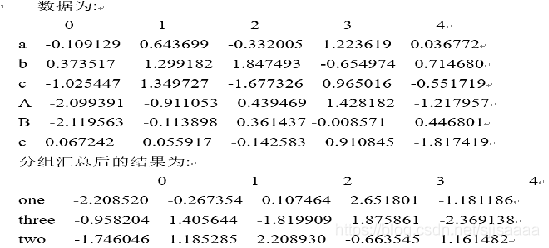
**按字典分组**
如果原始的DataFrame中的分组信息很难确定或不存在,可以通过字典结构,定义分组信息。

**按函数分组**
函数作为分组键的原理类似于字典,通过映射关系进行分组,但是函数更加灵活。


### [](https://blog.csdn.net/sjjsaaaa/article/details/109604951)2.数据聚合
**聚合函数**
除了之前示例中的mean函数外,常用的聚合运算还有count和sum等。
**聚合运算方法**
**使用agg方法聚合数据**
agg、aggregate方法都支持对每个分组应用某个函数,包括Python内置函数或自定义函数。同时,这两个方法也能够直接对DataFrame进行函数应用操作。
在正常使用过程中,agg和aggregate函数对DataFrame对象操作的功能基本相同,因此只需掌握一个即可。
### [](https://blog.csdn.net/sjjsaaaa/article/details/109604951)3.分组运算
1. transform方法
通过transform方法可以将运算分布到每一行。
2. 使用apply方法聚合数据
apply方法类似于agg方法,能够将函数应用于每一列。
[](https://blog.csdn.net/sjjsaaaa/article/details/109604951)六、数据透视表
-------------------------------------------------------------------
### [](https://blog.csdn.net/sjjsaaaa/article/details/109604951)1.透视表
数据透视表(Pivot Table)是数据分析中常见的工具之一,根据一个或多个键值对数据进行聚合,根据列或行的分组键将数据划分到各个区域。
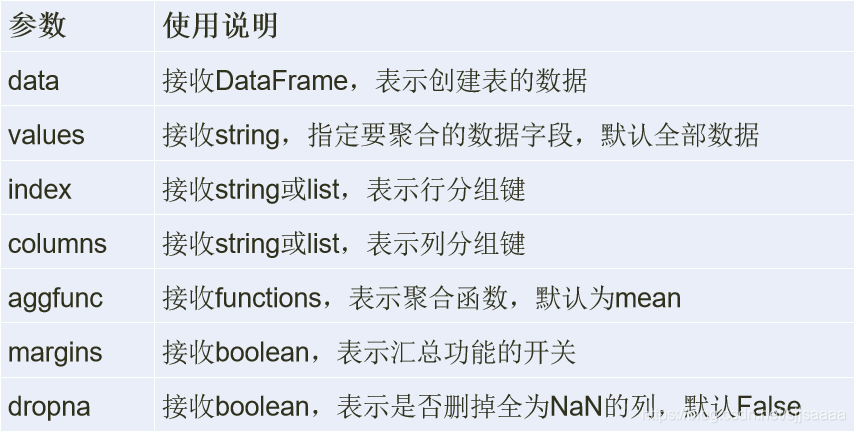
pivot_table函数格式: pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
**pivot\_table函数主要参数及其说明**
### [](https://blog.csdn.net/sjjsaaaa/article/details/109604951)2.交叉表
交叉表是一种特殊的透视表,主要用于计算分组频率。
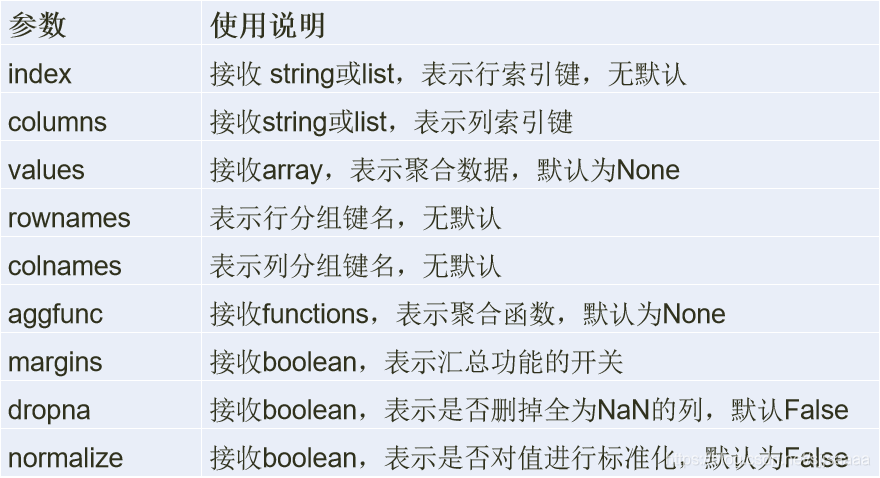
crosstab的格式: crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, dropna=True, normalize=False)
**crosstab主要参数及其说明**
[](https://blog.csdn.net/sjjsaaaa/article/details/109604951)七、Pandas可视化
-----------------------------------------------------------------------
### [](https://blog.csdn.net/sjjsaaaa/article/details/109604951)1.线形图
Pandas库中的Series和DataFrame中都有绘制各类图表的plot方法,默认绘制的都是线形图。
通过DataFrame对象的plot方法可以为各列绘制一条线,并创建图例。
### [](https://blog.csdn.net/sjjsaaaa/article/details/109604951)2.柱状图
在Pandas中绘制柱状图只需在plot函数中加参数kind = ‘bar’,如果类别较多,可以绘制水平柱状图(kind = ‘barh’)。
### [](https://blog.csdn.net/sjjsaaaa/article/details/109604951)3.直方图和密度图
直方图用于频率分布,y轴为数值或比率。绘制直方图,可以观察数据值的大致分布规律。pandas中的直方图可以通过hist方法绘制。
核密度估计是对真实密度的估计,其过程是将数据的分布近似为一组核(如正态分布)。通过plot函数的kind = ‘kde’可以进行绘制。
### [](https://blog.csdn.net/sjjsaaaa/article/details/109604951)4.散点图
通过plot函数的kind = 'scatter’可以进行绘制。











