
一、Pipeline介绍
Jenkins2.0中最大的一个特性就是Pipeline,实际使用中Pipeline已经超越了我们对jenkins本身的理解,可能在之前我们大多数把Jenkins当做是一个持续集成的工具。但是在Jenkins2.0中,Jenkins完成了CI到CD的华丽转身,而且因为Jenkins的开放性,随着一些测试plugin的加入,CT持续测试也可以在Jenkins Pipeline上实现。以及多节点的组合式任务,使得Jenkins可以实现复杂的发布流程。
Pipeline,简而言之,就是一套运行于Jenkins上的工作流框架,将原本独立运行于单个或者多个节点的任务连接起来,实现单个任务难以完成的复杂流程编排与可视化。
1、Jenkins持续集成架构图
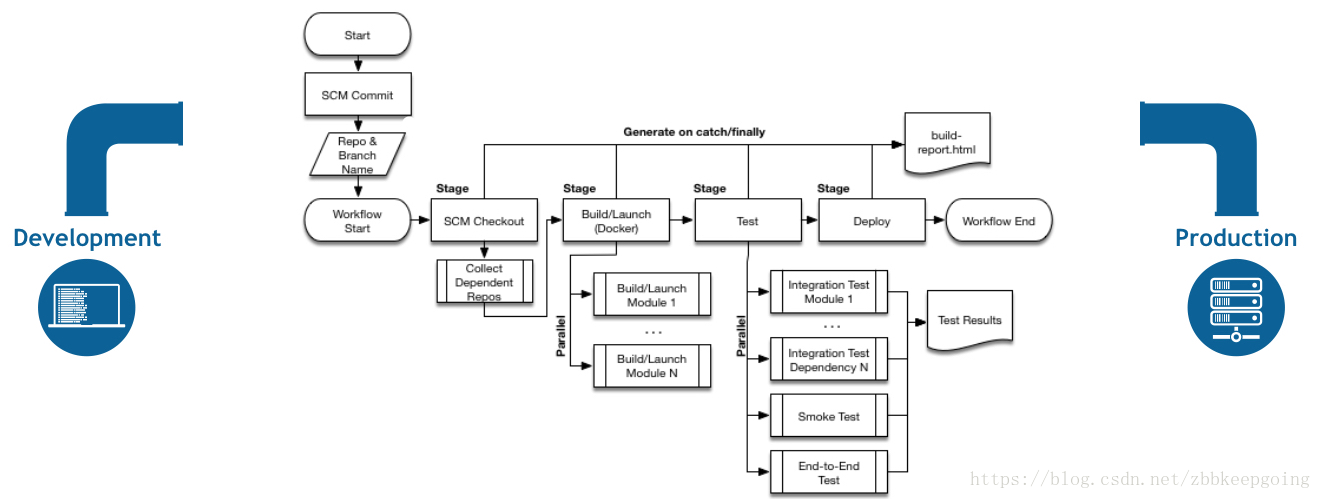
2、Pipeline的组成部分
①Node
我们可以将Node称为是节点或者Agent。节点可以执行某一阶段(Stage)、某几阶段(Stage)乃至整个Pipeline,就看我们Pipeline中在哪里去定义Node。我们可以将Node作为Jenkins Master的Slave 节点来分担Master节点的构建以及执行job负载。也可以将Node当做测试、部署的专用节点。比如我们可以增加一个Ansible节点用来做自动化部署,增加 一个Jmeter节点用来做性能测试。
②Stage
我们可以将Stage称为阶段,每一个Stage为Pipeline中的一个小部分,而每个Stage中最小部分为Step。比如一个简单的持续集成Pipeline。我们可以分为两个Stage,第一个是git clone code,把最新代码拉下来,第二个为Build,即利用Ant、Maven等工具进行代码编译构建。
③Step
我们可以把Step称为步骤,一个或者多个Step将会组成一个Stage,Step是Pipeline组成的最小单位。一个Step可以很简单,比如echo “hello”。也可以很复杂,比如sh‘’ “docker build -t jenkins:master ”。
3、Pipeline两种语法
Pipeline脚本是由Groovy语言实现
①声明式Pipeline
pipeline {
agent any //定义使用哪个Node进行Job的执行
stages {
stage('Build') { //定义Build的stage
steps { //定义Build的stage下面的所有step
//
}
}
stage('Test') {
steps {
//
}
}
stage('Deploy') {
steps {
//
}
}
}
}
②脚本式Pipeline
node { //定义使用哪个Node进行Job的执行与声明式中的Agent等同。
stage('Build') { //定义Build的stage步骤
// //定义Build的stage下面的所有step步骤
}
stage('Test') {
//
}
stage('Deploy') {
//
}
}
4、如何写Pipeline
Jenkins贴心的为我们提供了快速生成脚本的功能
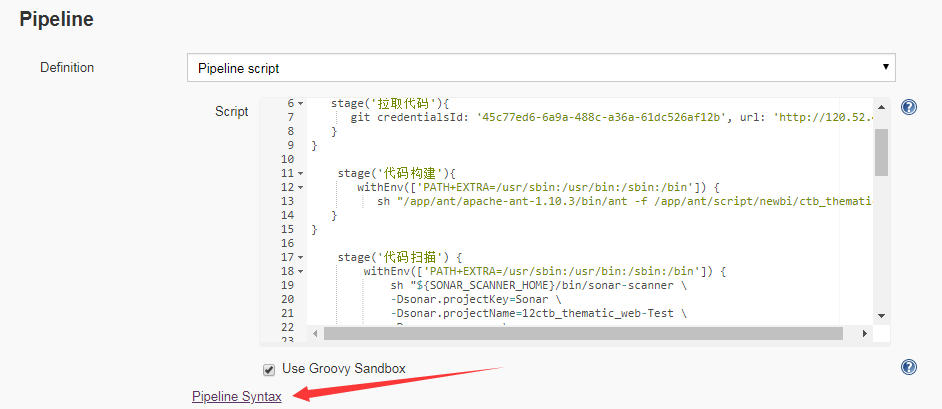
①拉取代码为例
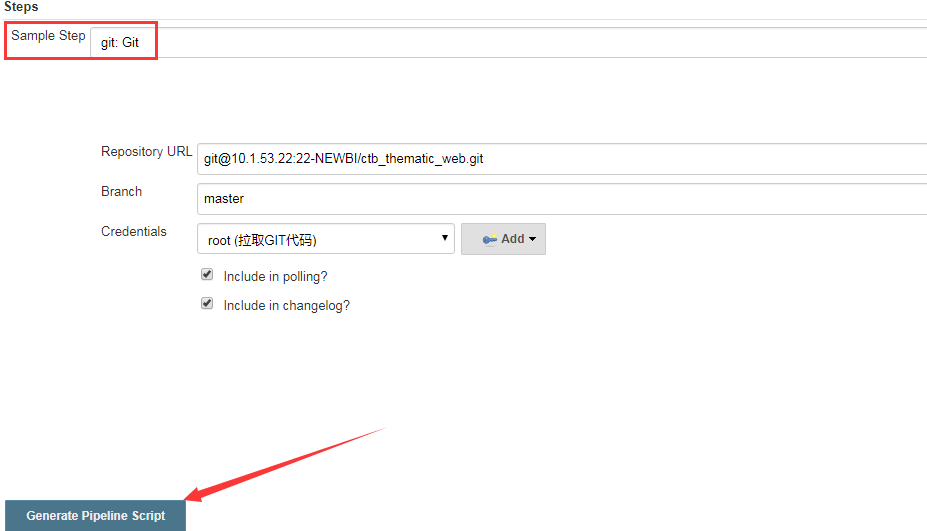
②生成Pipeline脚本

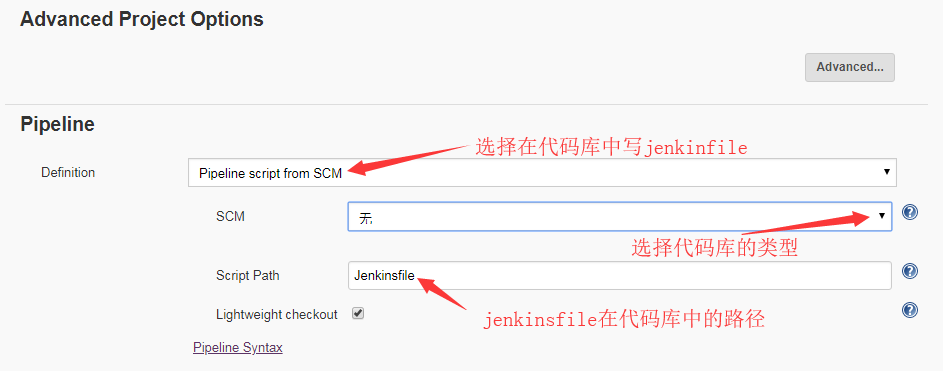
③Pipeline最佳实践
通常推荐在 Jenkins中直接从源代码控制(SCM)中载入Jenkinsfile Pipeline,这样可以对Jenkinsfile也进行分支管理以及不同版本的管理。
更多Pipeline的使用和说明请参照官方文档:https://jenkins.io/doc/book/pipeline/











