大家好,我是皮皮。
一、前言
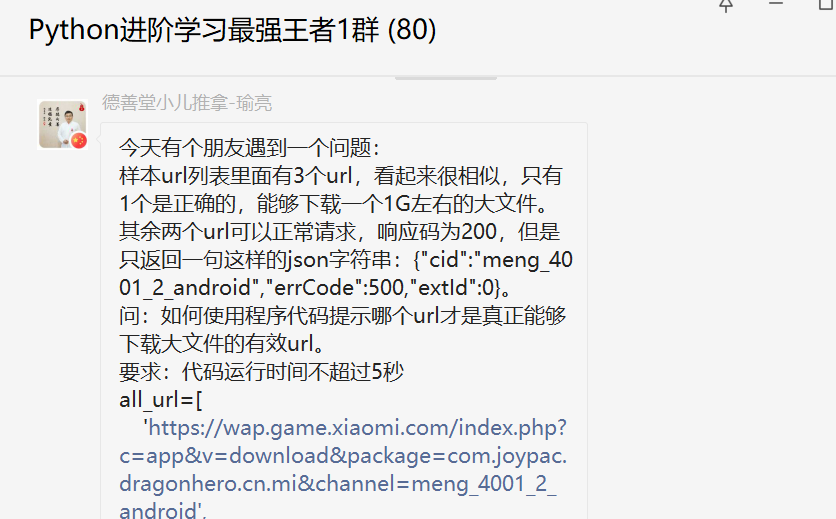
前几天在Python最强王者交流群【木易雲】问了一个Pandas的问题,这里拿出来给大家分享下。

数据如下:

二、实现过程
这里【隔壁😼山楂】给了一个思路,使用分组排序,再拼接。【逸】也给了一个思路,如下所示:

思路还是挺多的,后来【郑煜哲·Xiaopang】还给了一个思路,先groupby,再reset-index,拼接新增列。【D I Y】提示用excel,也是可以做到的。

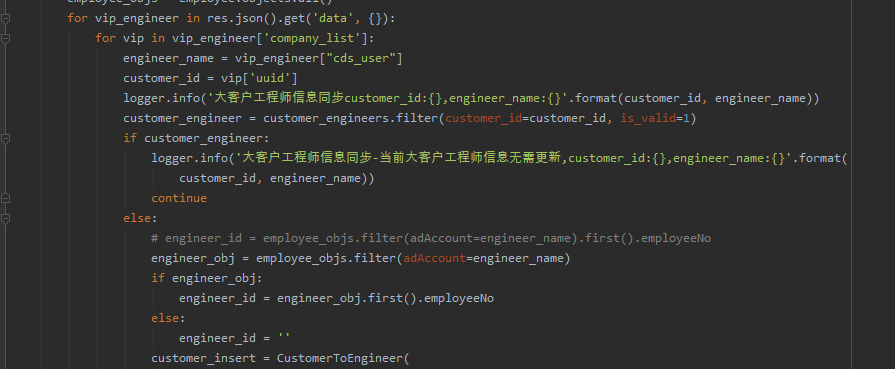
后来ChatGPT给出了解决方法,代码如下:
df['编号'] = df.groupby(['日期', '凭证字号']).cumcount() + 1 # 合并列生成新的'凭证编号'列 df['凭证编号'] = df['日期'] + df['凭证字号'] + '-' + df['编号'].astype(str)顺利地解决了粉丝的问题。

三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python正则表达式的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【木易雲】提问,感谢【隔壁😼山楂】、【逸】、【郑煜哲·Xiaopang】给出的思路和代码解析,感谢【eric】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。